
页面的渲染过程
当我们在浏览器里输入一个 URL 后,最终会呈现一个完整的网页。会经历以下几个步骤:
1、HTML 的加载
页面上输入 URL 后,会先拿到 HTML 文件。HTML是一个页面的基础,所以会在最开始的时候下载它,下载完毕后就开始对它进行解析
2、其他静态资源的下载
HTML 在解析的过程中,如果发现 HTML 文本里面有一些外部的资源链接,比如 CSS、JS 和图片等,会立即启用别的线程下载这些静态资源。在 head 中遇到 JS 文件时,HTML 的解析会停 下来,等 JS 文件下载结束并且执行完,HTML 的解析工作再接着来,防止 JS 修改已经完成的解析结果
知识拓展
由上得知,JS 文件放在 head 中属于同步加载,会阻塞 DOM 树的构建,进而影响页面的加载。当 JS 文件较多时,页面白屏的时间也会变长
那如何避免这个问题呢?下面有三个解决方案
1、 script 放在 body 里(一般是 </body> 上面)
由于 DOM 是自上而下解析的,因此 JS 不会阻塞 DOM 的解析,而且这时候可以在 JS 中操作 DOM
2、设置 defer 属性
通过给 script 标签设置 defer 属性,将脚本文件设置为延迟加载,当浏览器遇到带有 defer 属性的 script 标签时,会再开启一个线程去下载 JS 文件,同时继续解析 HTML,等 HTML 全部解析完、DOM 加载完成之后,再去执行加载好的 JS 文件。只适用于引用外部 JS 文件,并且可以确保所有加了 defer 属性的脚本会按顺序执行
3、设置 async 属性
async 属性和 defer 属性类似,也是会开启一个线程去下载js文件,但和 defer 不同的是,aysnc 会在 JS 加载完成后立刻执行,而不是会等到 DOM 加载完成之后再执行,所以还是有可能会造成阻塞。同样的也是只适用于外部 JS 文件,如果有多个设置了 aysnc 的 JS 文件,不能像 defer 那样保证按照顺序执行
4、动态创建脚本
这样去动态创建文件也不会影响到页面的加载,以下是百度统计的demo
<script>
var _hmt = _hmt || [];
(function () {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script>
3、DOM 树的构建
DOM 的全称是:文档对象模型(Document Object Model),在 HTML 解析时,解析器会把解析完的 HTML转化成 DOM 对象,再进一步构建 DOM 树
4、CSSOM 树的构建
当 CSS 下载完,CSS 解析器就开始对 CSS 进行解析,把 CSS 解析成 CSS 对象,然后把这些 CSS 对象组装成一颗 CSSOM 树
5、渲染树的构建
DOM 树和 CSSOM 树都构建完成以后,浏览器会根据这两棵树构建出一棵渲染树
6、布局计算
渲染树构建完成以后,所有元素的位置关系和需要应用的样式就确定了。这时候浏览器会计算出所有元素的大小
和绝对位置
7、渲染
布局计算完成以后,浏览器就可以在页面上渲染元素了,经过渲染引擎的处理后,整个页面就显示在了屏幕上
上面是一个浏览器渲染页面的大概过程,接下来就来把这个过程的几个重要部分再详细讲下
DOM 树的构建
页面中的每一个 HTML 标签,都会被浏览器解析成一个对象,我们称它为文档对象(Document Object)。HTML
本质是一个嵌套结构,在解析的时候会把每个文档对象用一个树形结构组织起来,所有的文档对象都会挂在一个叫做 Document 的东西上,这种组织方式就是 HTML 最基础的结构–文档对象模型(DOM),这棵树里面的每个文档对象就叫做 DOM 节点。
在 HTML 加载的过程中,DOM 树就在开始构建了。构建的过程是先把 HTML 里每个标签都解析成 DOM 节点(每
个标签的属性、值和上下文关系等都在这个文档对象里),然后使用深度遍历的方法把这些对象构造成一棵树。
我们以下面的 HTML 文件为例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<header>
<p>header</p>
</header>
<div class="content">
<p class="title">title</p>
</div>
</body>
</html>
在构建 DOM 树的时候,就是从最外层 HTML 节点开始,按深度优先的方式构建。之所以用深度优先,是因为HTML在加载的时候是自上而下的,最先加载的是根节点 ,然后是根节点的第一个子节点 ,再然后是 head 的第一个子节点,head 构建完成后再去构建 body 部分的内容,以此类推。使用深度优先的方式构建 这棵树就和文档的加载顺序吻合了。最后,上面这个 HTML 结构会生成这样一颗 DOM 树:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UFUa0edZ-1589276730057)(https://user-gold-cdn.xitu.io/2020/5/12/172083fc6802bb64?w=532&h=287&f=png&s=12789)]
CSSOM 树的构建
在浏览器构建 DOM 树的同时,如果样式也加载完成了,那么 CSSOM 树也在同步地构建。CSS 树和 DOM 类
似,它的树形结构会记录所有样式的信息
假设我们给上面的 HTML 加上这些样式:
body {
font-size: 16px;
}
p {
margin: 0;
padding: 0;
}
header {
width: 100%;
height: 50px;
text-align: center;
display: none;
}
header p {
color: #333;
}
.content {
padding: 0 16px;
}
.content .title {
font-size: 24px;
}
这组样式通过解析器的构造,会得到类似这样的一颗 CSSOM 树: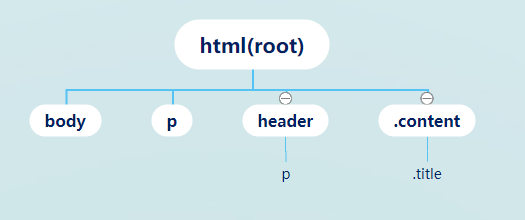
Tips:
1、这棵树的结构只是一个示意图,并不是浏览器构造 CSSOM 树的真实数据结构,各个浏览器实现 CSSOM 树的方式也不完全相同
2、CSSOM 树和 DOM 树是独立的两个数据结构,它们没有一一对应的关系。DOM 树描述的是 HTML 标签的层级关系,CSSOM 树描述的是选择器之间的层级关系
3、CSS 中存在样式继承机制,有些属性在父节点设置后,其后代节点都会具备这个样式。比如在 html 上设置一个 “color: red” ,那页面的所有标签都会继承这个属性。当然不是所有标签和属性都是可以继承的,比如 border 这种属性就是不可继承的。如果 border 可继承,那么在一个父元素里设置了以后,所有子元素都会有个边框,这显然是不合理的。所以在大部分情况下,通过这种推理,就能知道哪些样式可以继承,哪些样式不可以继承
小结

这一篇就讲了大概这么些东西,下一篇接着讲渲染树的构建、渲染过程、布局、绘制、重排重绘以及怎么优化页面性能(还没写完,只有个大纲)
觉得写的不好或不正确的地方还请不吝赐教 [抱拳]





