
背景
前不久开发了一个运营小工具,运营人员上传一个id的列表,即可导出对应id的额外数据。需求本身不复杂,很快就开发完了,但上线后,运营反馈了一个问题,导出后的数据跟导出之前的数据顺序不一致。
经过沟通后发现,原来运营的id数据是从另一个 Excel 复制出来的一列,用工具导出完之后,需要再把新增的一列数据复制回去。就像下面这样:
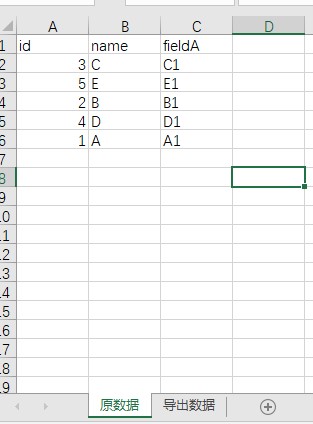
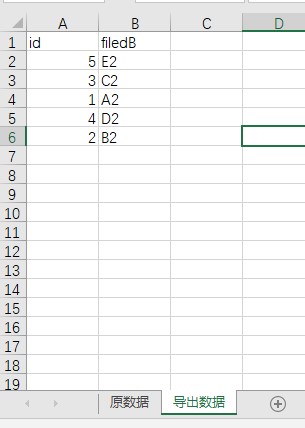
emmmm,跟从产品经理了解到的需求好像还是有点点不一样,那怎么解决这个问题呢?
方案一、排序
拍了拍我聪明的大脑壳,一个骚操作就诞生了,把两边都按id排序一下,顺序不就一样了?就像这样:


机智如我,这种方法比较简单粗暴,也确实能解决问题,但有两个明显的缺点:
- 如果两边id的数量并不一致,那这个方案是行不通的
- 排序后,原文件无法恢复到原序列
虽然简单粗暴能解决问题,但是还不够好。

方案二、修改框架
目前类似的小工具都统一使用组内开发的一个批量处理工具,接入比较简单方便,框架的大致原理是解析文件后,分发给多个 gorutine 进行并发处理,最后通过 reduce 操作聚合结果,所以最终结果只会是局部有序。
要想解决这个问题,需要对框架进行一些修改,最简单的处理方式,可以在解析文件后,先创建一个有序 map 作为 reduce 的结果表,每个子任务完成后,把结果写回最初的 map 里,最后按顺序输出即可。
但这个方案比较耗时,而且存在一定风险,毕竟在Go语言里,是没有有序 map 这样的数据结构的,实现起来并不简单(当然也可以用两个 map 来解决,一个存id和数据的映射,另一个存id与原序号的映射),最重要的一点是,很多任务都使用了这个框架,还需要考虑是否会影响之前的任务。

当我把想法跟同事交流后,同事嘿嘿一笑,搞这么复杂干嘛,让他们用vloop就行了。
vlookup ???经过一番搜索后,终于搞明白了,原来还有这么好用的东西,于是便有了方案三,也就是本篇的主角。
方案三、vlookup 函数
vlookup 函数是 excel 中的一个函数,可以用于纵向查找,函数语法如下:

这个函数一共有四个参数,第一个是要查找的值,第二个参数是查找区域,第三个参数是需要返回的值所在的列的序号,第四个参数代表是精确匹配还是模糊匹配。
好了,函数讲解完成,很简单吧。

下面我们来练习一下:
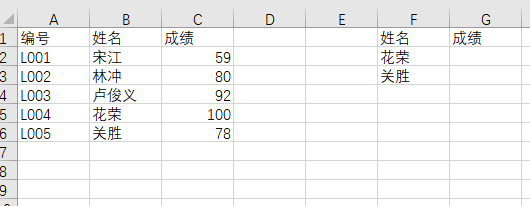
我们需要在G列取出两位同学的成绩,来套一下公式,第一个参数是要查找的值,这里选“花荣”,也就是 $F2,第二个参数是匹配对象范围,这里框选出BC两列。
划重点!!!这里选出的区域,第一列必须包含要查证的值,比如这里的花荣和关胜,都在B列中。
第三个参数代表需要取第几列的值,注意,这里是指选中区域的第几列,我们选中的是BC两列,需要取的是C列,所以应该是第2列(序号从1开始)。
第四个参数代表是否需要模糊匹配,FALSE代表否,TRUE代表是,这里我们选择 FALSE。
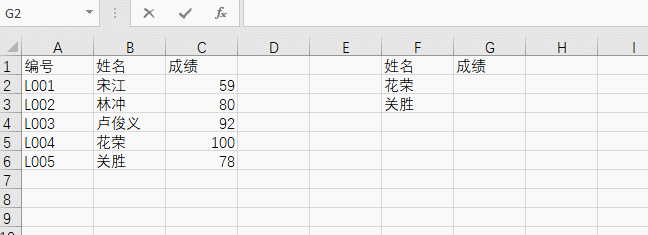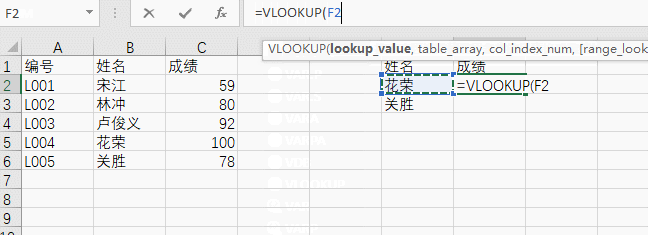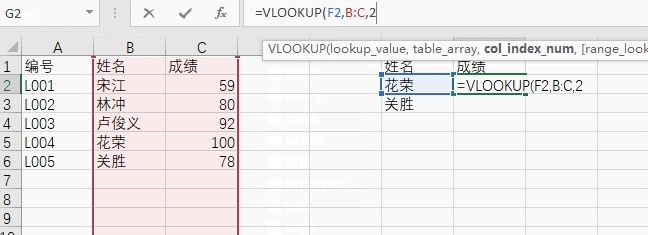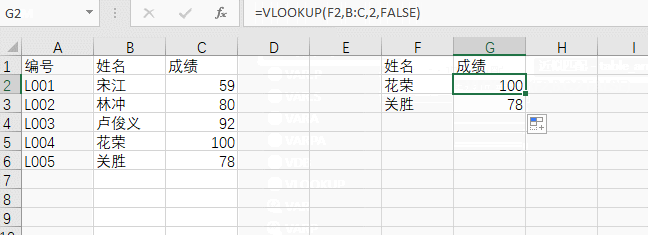
所以公式就变成了:
=VLOOKUP(F2,B:C,2,FALSE)
下面是操作动态图:
其实也很简单嘛。

下面我们再来做一题,试试模糊匹配。
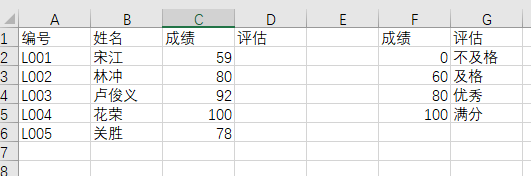
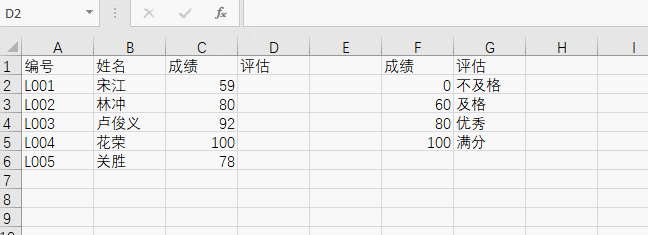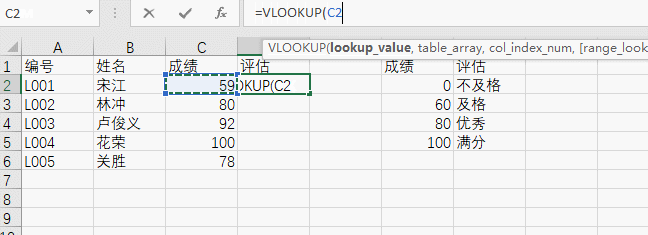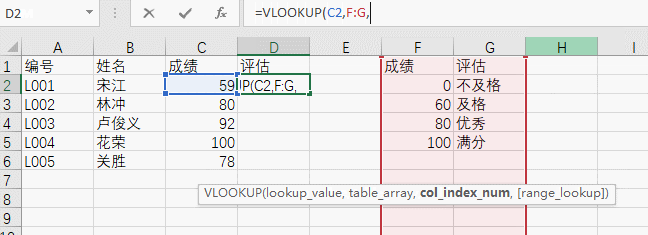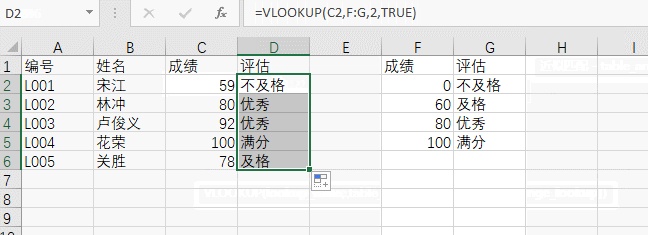
现在我们需要给这五位同学评分,评价标准是:059是不及格,6070是及格,7080是良,8099是优秀,100是满分。
这个时候,模糊匹配就派上了用场。
第一个参数,待查找的值,这里是成绩,所以选择C2。
第二个参数,匹配对象范围,这里选FG两列。
第三个参数,需要取出的值,这里选第二列。
第四个参数,是否模糊匹配,这里选TRUE。
所以公式就是:
=VLOOKUP(C2,F:G,2,TRUE)
下面是操作的动态图:
手有点冷,操作有点捉急,哈哈哈哈。
其实这个函数也挺简单的嘛,建议多练习一下,以备不时之需。即使不想学也没关系,至少得知道 Excel 可以实现这样的功能,下次需要的时候再查也无妨。
还是那句话,知识就像手里的牌,知道的越多,便越能灵活应对。

总结
其实写这篇文章,总结一下 vlookup 的用法只是一方面,另一方面也是对自己的反思,自从学了编程之后,曾一度对 Excel 等工具不屑一顾,总觉得能用代码完成的功能,就不应该借助它们的力量。
如果是在学习探索阶段,通过自己的努力来实现各种功能自然是不错的,但也不应该忘记,我们所掌握的各种编程语言也不过是工具而已,最重要的是解决问题,用什么工具解决又有什么区别呢?
见过很多人会拼命吹嘘XX语言是最好的语言,我觉得这样的讨论很无聊,还不如吹一吹清风是世界上最帅的男人。







