
在NLP领域,语义相似度的计算一直是个难题:搜索场景下query和Doc的语义相似度、feeds场景下Doc和Doc的语义相似度、机器翻译场景下A句子和B句子的语义相似度等等。本文通过介绍DSSM、CNN-DSSM、LSTM-DSSM等深度学习模型在计算语义相似度上的应用,希望给读者带来帮助。
1. 背景
以搜索引擎和搜索广告为例,最重要的也最难解决的问题是语义相似度,这里主要体现在两个方面:召回和排序。
在召回时,传统的文本相似性如 BM25,无法有效发现语义类 query-Doc 结果对,如"从北京到上海的机票"与"携程网"的相似性、"快递软件"与"菜鸟裹裹"的相似性。
在排序时,一些细微的语言变化往往带来巨大的语义变化,如"小宝宝生病怎么办"和"狗宝宝生病怎么办"、"深度学习"和"学习深度"。
DSSM(Deep Structured Semantic Models)为计算语义相似度提供了一种思路。
本文的最后,笔者结合自身业务,对 DSSM 的使用场景做了一些总结,不是所有的业务都适合用 DSSM。
2. DSSM
DSSM [1](Deep Structured Semantic Models)的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层
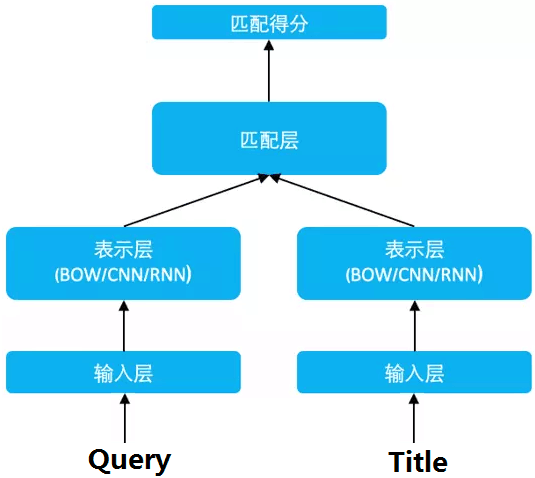
2.1 输入层
输入层做的事情是把句子映射到一个向量空间里并输入到 DNN 中,这里英文和中文的处理方式有很大的不同。
(1)英文
英文的输入层处理方式是通过word hashing。举个例子,假设用 letter-trigams 来切分单词(3 个字母为一组,#表示开始和结束符),boy 这个单词会被切为 #-b-o, b-o-y, o-y-#
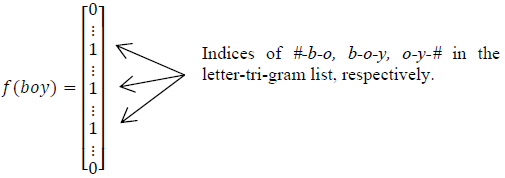
这样做的好处有两个:首先是压缩空间,50 万个词的 one-hot 向量空间可以通过 letter-trigram 压缩为一个 3 万维的向量空间。其次是增强范化能力,三个字母的表达往往能代表英文中的前缀和后缀,而前缀后缀往往具有通用的语义。
这里之所以用 3 个字母的切分粒度,是综合考虑了向量空间和单词冲突:
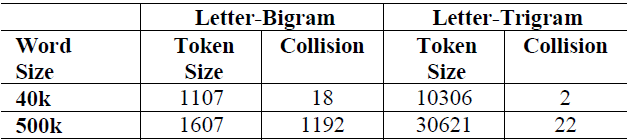
以 50 万个单词的词库为例,2 个字母的切分粒度的单词冲突为 1192(冲突的定义:至少有两个单词的 letter-bigram 向量完全相同),而 3 个字母的单词冲突降为 22 效果很好,且转化后的向量空间 3 万维不是很大,综合考虑选择 3 个字母的切分粒度。
(2)中文
中文的输入层处理方式与英文有很大不同,首先中文分词是个让所有 NLP 从业者头疼的事情,即便业界号称能做到 95%左右的分词准确性,但分词结果极为不可控,往往会在分词阶段引入误差。所以这里我们不分词,而是仿照英文的处理方式,对应到中文的最小粒度就是单字了。(曾经有人用偏旁部首切的,感兴趣的朋友可以试试)
由于常用的单字为 1.5 万左右,而常用的双字大约到百万级别了,所以这里出于向量空间的考虑,采用字向量(one-hot)作为输入,向量空间约为 1.5 万维。
2.2 表示层
DSSM 的表示层采用 BOW(Bag of words)的方式,相当于把字向量的位置信息抛弃了,整个句子里的词都放在一个袋子里了,不分先后顺序。当然这样做会有问题,我们先为 CNN-DSSM 和 LSTM-DSSM 埋下一个伏笔。
紧接着是一个含有多个隐层的 DNN,如下图所示:
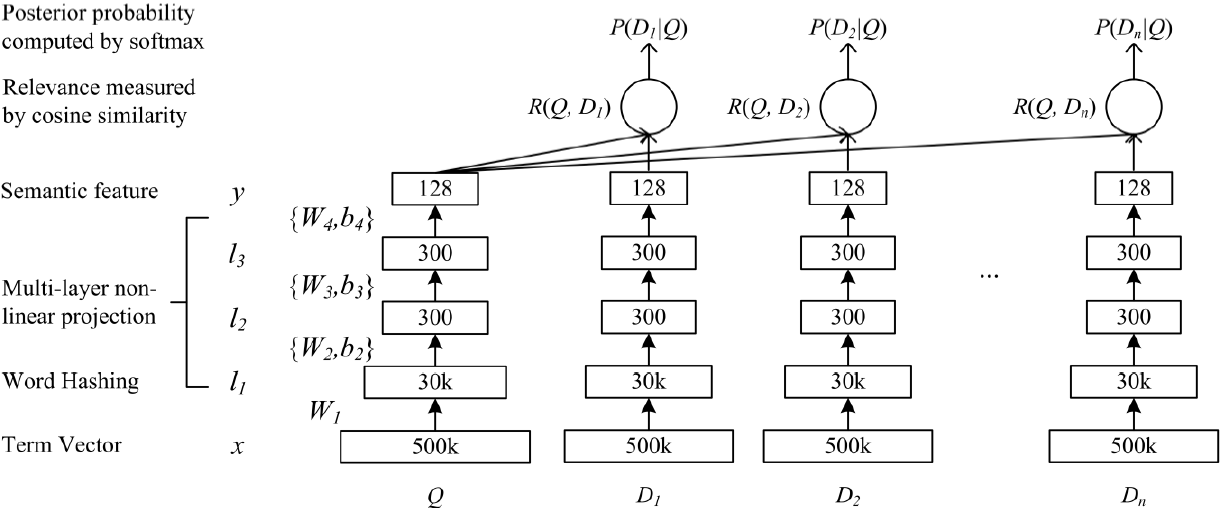
用 Wi 表示第 i 层的权值矩阵,bi 表示第 i 层的 bias 项。则第一隐层向量 l1(300 维),第 i 个隐层向量 li(300 维),输出向量 y(128 维)可以分别表示为:
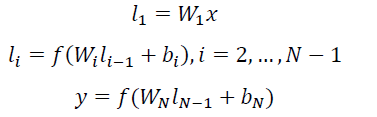
用 tanh 作为隐层和输出层的激活函数:
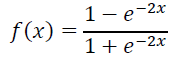
最终输出一个 128 维的低纬语义向量。
2.3 匹配层
Query 和 Doc 的语义相似性可以用这两个语义向量(128 维) 的 cosine 距离来表示:
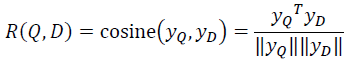
通过softmax 函数可以把Query 与正样本 Doc 的语义相似性转化为一个后验概率:
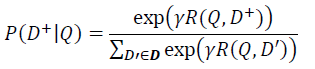
其中 r 为 softmax 的平滑因子,D 为 Query 下的正样本,D-为 Query 下的负样本(采取随机负采样),D 为 Query 下的整个样本空间。
在训练阶段,通过极大似然估计,我们最小化损失函数:
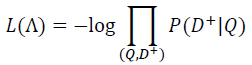
残差会在表示层的 DNN 中反向传播,最终通过随机梯度下降(SGD)使模型收敛,得到各网络层的参数{Wi,bi}。
2.4 优缺点
优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
3. CNN-DSSM
针对 DSSM 词袋模型丢失上下文信息的缺点,CLSM[2](convolutional latent semantic model)应运而生,又叫 CNN-DSSM。CNN-DSSM 与 DSSM 的区别主要在于输入层和表示层。
3.1 输入层
(1)英文
英文的处理方式,除了上文提到的 letter-trigram,CNN-DSSM 还在输入层增加了word-trigram
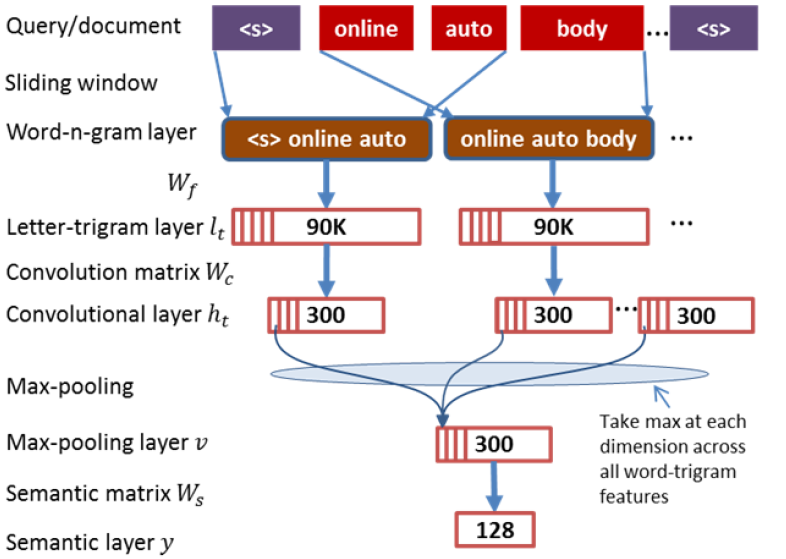
如上图所示,word-trigram其实就是一个包含了上下文信息的滑动窗口。举个例子:把<s> online auto body ... <s>这句话提取出前三个词<s> online auto,之后再分别对这三个词进行letter-trigram映射到一个 3 万维的向量空间里,然后把三个向量 concat 起来,最终映射到一个 9 万维的向量空间里。
(2)中文
英文的处理方式(word-trigram letter-trigram)在中文中并不可取,因为英文中虽然用了 word-ngram 把样本空间拉成了百万级,但是经过 letter-trigram 又把向量空间降到可控级别,只有 3*30K(9 万)。而中文如果用 word-trigram,那向量空间就是百万级的了,显然还是字向量(1.5 万维)比较可控。
3.2 表示层
CNN-DSSM 的表示层由一个卷积神经网络组成,如下图所示:
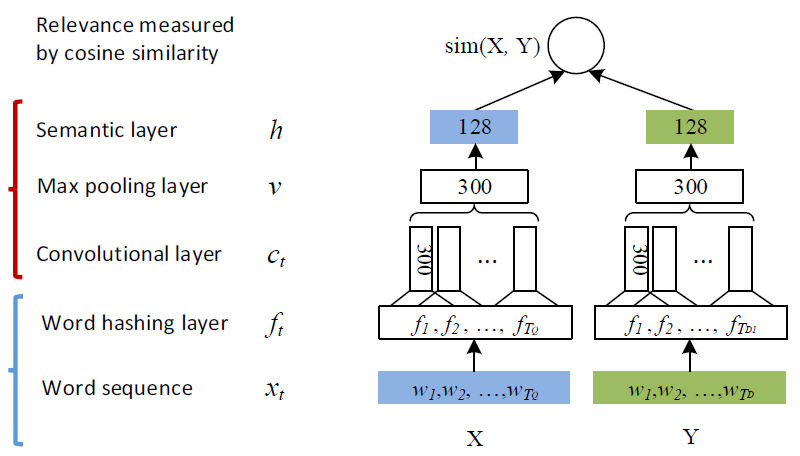
(1)卷积层——Convolutional layer
卷积层的作用是提取滑动窗口下的上下文特征。以下图为例,假设输入层是一个 302*90000(302 行,9 万列)的矩阵,代表 302 个字向量(query 的和 Doc 的长度一般小于 300,这里少了就补全,多了就截断),每个字向量有 9 万维。而卷积核是一个 3*90000 的权值矩阵,卷积核以步长为 1 向下移动,得到的 feature map 是一个 300*1 的矩阵,feature map 的计算公式是(输入层维数 302-卷积核大小 3 步长 1)/步长 1=300。而这样的卷积核有 300 个,所以形成了 300 个 300*1 的 feature map 矩阵。
(2)池化层——Max pooling layer
池化层的作用是为句子找到全局的上下文特征。池化层以 Max-over-time pooling 的方式,每个 feature map 都取最大值,得到一个 300 维的向量。Max-over-pooling 可以解决可变长度的句子输入问题(因为不管 Feature Map 中有多少个值,只需要提取其中的最大值)。不过我们在上一步已经做了句子的定长处理(固定句子长度为 302),所以就没有可变长度句子的问题。最终池化层的输出为各个 Feature Map 的最大值,即一个 300*1 的向量。这里多提一句,之所以 Max pooling 层要保持固定的输出维度,是因为下一层全链接层要求有固定的输入层数,才能进行训练。
(3)全连接层——Semantic layer
最后通过全连接层把一个 300 维的向量转化为一个 128 维的低维语义向量。全连接层采用 tanh 函数:
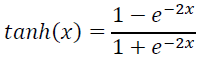
3.3 匹配层
CNN-DSSM 的匹配层和 DSSM 的一样,这里省略。
3.4 优缺点
优点:CNN-DSSM 通过卷积层提取了滑动窗口下的上下文信息,又通过池化层提取了全局的上下文信息,上下文信息得到较为有效的保留。
缺点:对于间隔较远的上下文信息,难以有效保留。举个例子,I grew up in France... I speak fluent French,显然 France 和 French 是具有上下文依赖关系的,但是由于 CNN-DSSM 滑动窗口(卷积核)大小的限制,导致无法捕获该上下文信息。
4. LSTM-DSSM
针对 CNN-DSSM 无法捕获较远距离上下文特征的缺点,有人提出了用LSTM-DSSM[3](Long-Short-Term Memory)来解决该问题。不过说 LSTM 之前,要先介绍它的"爸爸""RNN。
4.1 RNN
RNN(Recurrent Neural Networks)可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。如果我们将这个循环展开:
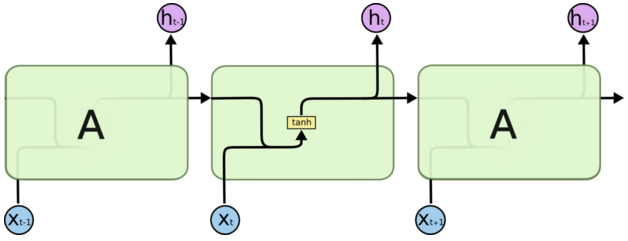
假设输入 xi 为一个 query 中几个连续的词,hi 为输出。那么上一个神经元的输出 h(t-1) 与当前细胞的输入 Xt 拼接后经过 tanh 函数会输出 ht,同时把 ht 传递给下一个细胞。
不幸的是,在这个间隔不断增大时,RNN 会逐渐丧失学习到远距离信息的能力。因为 RNN 随着距离的加长,会导致梯度消失。简单来说,由于求导的链式法则,直接导致梯度被表示为连乘的形式,以至梯度消失(几个小于 1 的数相乘会逐渐趋向于 0)。
4.2 LSTM
LSTM[4]((Long-Short-Term Memory)是一种 RNN 特殊的类型,可以学习长期依赖信息。我们分别来介绍它最重要的几个模块:
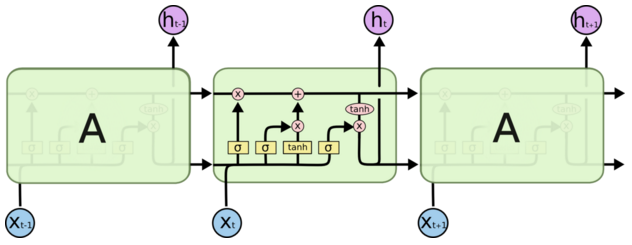
(0)细胞状态
细胞状态这条线可以理解成是一条信息的传送带,只有一些少量的线性交互。在上面流动可以保持信息的不变性。
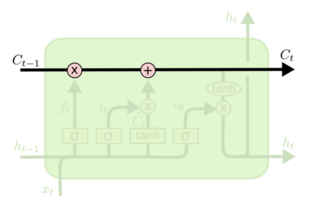
(1)遗忘门
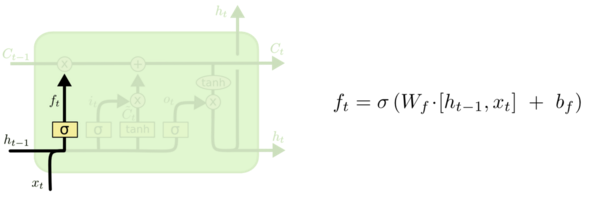
遗忘门 [5]由 Gers 提出,它用来控制细胞状态 cell 有哪些信息可以通过,继续往下传递。如下图所示,上一层的输出 h(t-1) concat 上本层的输入 xt,经过一个 sigmoid 网络(遗忘门)产生一个从 0 到 1 的数值 ft,然后与细胞状态 C(t-1) 相乘,最终决定有多少细胞状态可以继续往后传递。
(2)输入门
输入门决定要新增什么信息到细胞状态,这里包含两部分:一个 sigmoid 输入门和一个 tanh 函数。sigmoid 决定输入的信号控制,tanh 决定输入什么内容。如下图所示,上一层的输出 h(t-1) concat 上本层的输入 xt,经过一个 sigmoid 网络(输入门)产生一个从 0 到 1 的数值 it,同样的信息经过 tanh 网络做非线性变换得到结果 Ct,sigmoid 的结果和 tanh 的结果相乘,最终决定有哪些信息可以输入到细胞状态里。
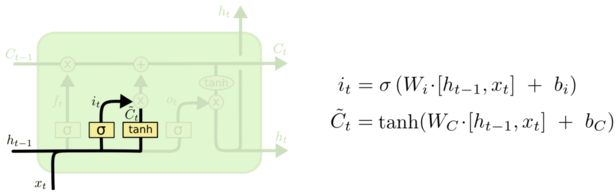
(3)输出门
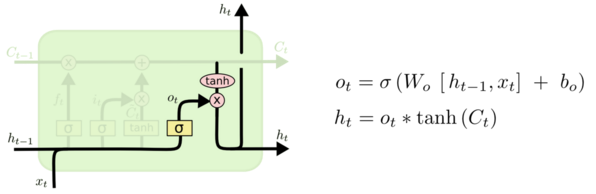
输出门决定从细胞状态要输出什么信息,这里也包含两部分:一个 sigmoid 输出门和一个 tanh 函数。sigmoid 决定输出的信号控制,tanh 决定输出什么内容。如下图所示,上一层的输出 h(t-1) concat 上本层的输入 xt,经过一个 sigmoid 网络(输出门)产生一个从 0 到 1 的数值 Ot,细胞状态 Ct 经过 tanh 网络做非线性变换,得到结果再与 sigmoid 的结果 Ot 相乘,最终决定有哪些信息可以输出,输出的结果 ht 会作为这个细胞的输出,也会作为传递个下一个细胞。
4.2 LSTM-DSSM
LSTM-DSSM 其实用的是 LSTM 的一个变种——加入了peephole[6]的 LSTM。如下图所示:
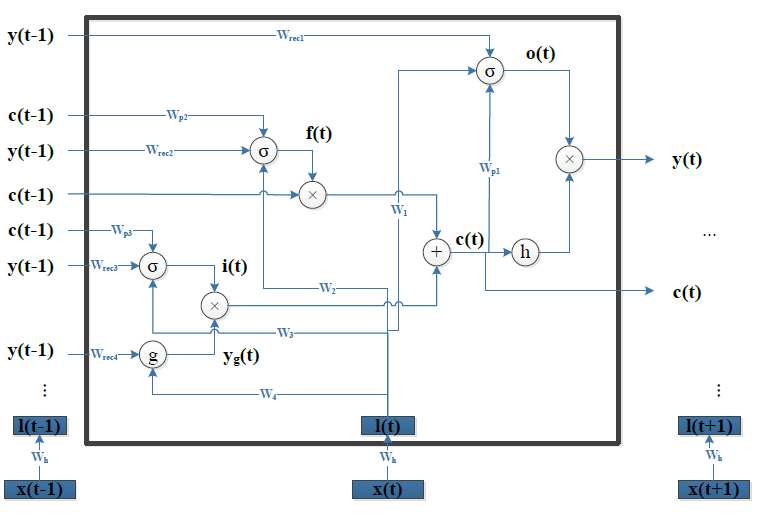
看起来有点复杂,我们换一个图,读者可以看的更清晰:
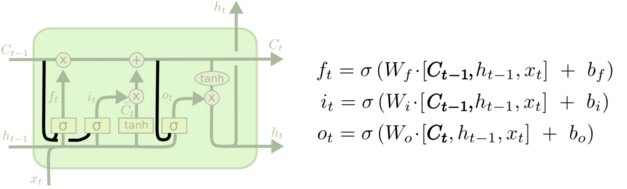
这里三条黑线就是所谓的 peephole,传统的 LSTM 中遗忘门、输入门和输出门只用了 h(t-1) 和 xt 来控制门缝的大小,peephole 的意思是说不但要考虑 h(t-1) 和 xt,也要考虑 Ct-1 和 Ct,其中遗忘门和输入门考虑了 Ct-1,而输出门考虑了 Ct。总体来说需要考虑的信息更丰富了。
好了,来看一个 LSTM-DSSM 整体的网络结构:
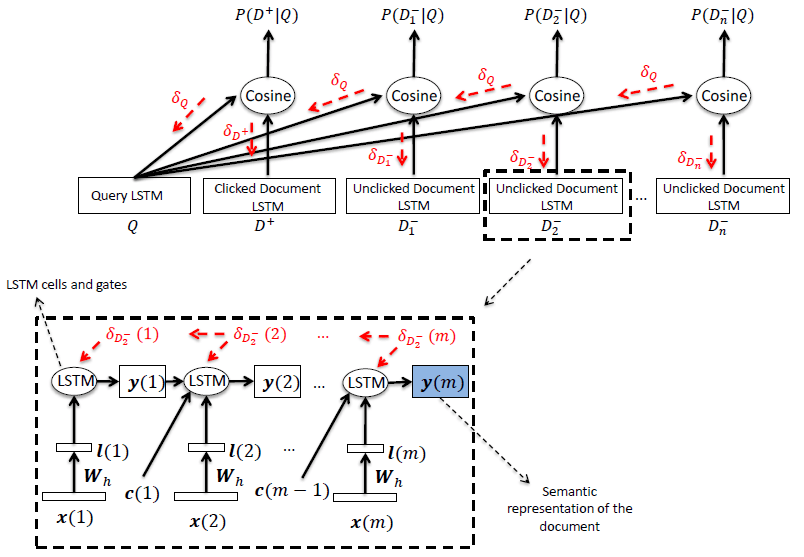
红色的部分可以清晰的看到残差传递的方向。
5. 后记
介绍完了 DSSM 及其几个变种,还要给读者泼点冷水,DSSM 就一定适合所有的业务吗?
这里列出 DSSM 的 2 个缺点以供参考:
1. DSSM 是端到端的模型,虽然省去了人工特征转化、特征工程和特征组合,但端到端的模型有个问题就是效果不可控。对于一些要保证较高的准确率的场景,用有监督人工标注的 query 分类作为打底,再结合无监督的 word2vec、LDA 等进行语义特征的向量化,显然比较可控(至少 query 分类的准确率可以达到 95%以上)。
2. DSSM 是弱监督模型,因为引擎的点击曝光日志里 Query 和 Title 的语义信息比较弱。举个例子,搜索引擎第一页的信息往往都是 Query 的包含匹配,笔者统计过,完全的语义匹配只有不到 2%。这就意味着几乎所有的标题里都包含用户 Query 里的关键词,而仅用点击和曝光就能作为正负样例的判断?显然不太靠谱,因为大部分的用户进行点击时越靠前的点击的概率越大,而引擎的排序又是由 pCTR、CVR、CPC 等多种因素决定的。从这种非常弱的信号里提取出语义的相似性或者差别,那就需要有海量的训练样本。DSSM 论文中提到,实验的训练样本超过 1 亿。笔者和同事也亲测过,用传统 CTR 预估模型千万级的样本量来训练,模型无法收敛。可是这样海量的训练样本,恐怕只有搜索引擎才有吧?普通的搜索业务 query 有上千万,可资源顶多只有几百万,像论文中说需要挑出点击和曝光置信度比较高且资源热度也比较高的作为训练样本,这样就过滤了 80%的长尾 query 和 Title 结果对,所以也只有搜索引擎才有这样的训练语料了吧。另一方面,超过 1 亿的训练样本作为输入,用深度学习模型做训练,需要大型的 GPU 集群,这个对于很多业务来说也是不具备的条件。





