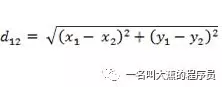今天跟大家分享一下,机器学习中最简单的算法之一,KNN近邻算法,这是一个有监督的分类学习算法。
啥玩意叫有监督呢?就是作为训练的每个样本都是有标记的,比如样本1是A类,样本2是B类,这样的有标记的样本。而什么叫分类呢?输出结果是离散的,可穷尽的,就叫分类。
KNN近邻算法的核心思想是:
近朱者赤,近墨者黑,选K而取其最大可能。
从哪开始聊呢?先从算法的核心过程开始吧。
准备基本数据集 -> 计算待测试样本整个数据集所有数据的距离 -> 根据距离进行排序 ->获取前K个样本,将他们的标签进行统计 -> 获取频次最大的标签作为结果输出
举个栗子:我想知道我现在最可能处于哪个小区,我们假设小区都一样大。
我得到了一批小区的GPS定位经纬度 -> 我得到了我自己的GPS经纬度 -> 计算出我跟所有这些小区的距离,然后排序一下 -> 拿到前K个距离的样本,对他们的小区名称进行统计 -> bingo,频次最大的那个小区就可能是我的小区了。
听起来蛮简单的,但是在实际操作过程中会遇到几个问题。如果基础样本数太多,该如何计算出所有的距离?如果不是空间距离,比如是两个文本,如何衡量两个实体之间的距离?取K个样本,那么K取多少对于结果比较好?
这些是我们作为使用者需要去考虑的事情,模型本身不考虑这个东西。就开放性地把问题抛出来吧,大家都思考思考。
用一个识别手写数字的例子来分享一下这个算法吧,代码自己写的,但是例子是书上的,轻喷。首先我们的数据长下面这样子,32*32的1024个像素的图片,都是手写的。
这是数字1

这是数字0

先定义一个函数,参数inX是要用来计算的向量,dataSet是测试数据集,labels是与dataSet一一对应的标签值,k是我们想获取的前k个样本的数值。
def classify0(inX, dataSet, labels, k):
#获得数据集的行数
dataSetSize = dataSet.shape[0]
#渲染出一个矩阵,行数跟dataSet行数一样,每一行都是要计算的图片
diffMat = tile(inX, (dataSetSize,1)) - dataSet
#然后计算出(Xn - Xi)^2 每个维度的坐标的相见的值
#这里使用的是欧拉距离来衡量两个图片之间的距离
sqDiffMat = diffMat**2
#每一个值相加,再进行开方,得到N维空间的距离
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#根据距离进行降序排序,获取前K个标签进行频次统计,然后取最大的那个
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]嘛,核心的分类算法就这样实现完了,不难,好好看看应该能看懂,最好自己写一遍。算法的主要思想就是把我们要计算的问题转变成能衡量距离的向量,然后计算向量之间的距离,用近朱者赤的观点来进行标签选择。
下面是一点工具类。这个函数是将一个文件转变成向量的工具,因为我们这里是文本所以直接用遍历的方式,这里比较原始,可以使用numpy等工具来进行矩阵的渲染。
def img2Vector(fileName): returnVect = zeros((1,1024)) fr = open(fileName) for i in range(32): lineStr = fr.readline() for j in range(32): returnVect[0,32*i+j] = int(lineStr[j]) return returnVect 如果是真正的图片,我们可以用img库来进行转换,转换完的矩阵会有三个通道,RGB,而且每个通道的每个像素都0-255。有几百万像素就有几百万的像素点。 我们有一堆文本来训练和测试这个模型。下面是测试方法,我就不细说了。
[object Object] [object Object]
def handWriterClassTest():
hwLabels = []
traningFileList = listdir('trainingDigits')
m = len(traningFileList)
traningMat = zeros((m,1024))
for i in range(m):
fileNameStr = traningFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
traningMat[i,:] = img2Vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest= img2Vector('testDigits/%s' % fileNameStr)
classiFierResult = classify0(vectorUnderTest, traningMat, hwLabels, 3)
print "the classifier came back with:%d , the real answer is: %d" % (classiFierResult,classNumStr)
if(classiFierResult != classNumStr):
errorCount += 1.0
print "\n the total numer of Error is: % d ,the error rate is: %f" % (errorCount,(errorCount/float(mTest)))
测试的结果准确度大概在98.8%这样子,在这个数据集上效果还是不错的,作为一个入门级算法。好了有什么好玩的大家再一次分享吧。什么你问欧拉距离是什么??是他是他就是他。