

让AI通过预测,捕捉你「左手画龙,右手画彩虹」的动作,对于AI理解人类行为至关重要。
想要做到这一点,人体运动数据不可或缺,但实际上,真实的3D运动数据恰恰是稀缺资源。
现在,来自马克斯·普朗克智能系统研究所的一项研究,利用对抗学习框架,在缺少真实3D标签的情况下,也能对实时视频里的人体运动,做出运动学上的合理预测。
就像这样,奔跑、跳跃都能跟得上:
并且,相比前辈,这一名为VIBE的方法更懂人心,连胳膊要抬几度,都计算得明明白白。

那么,VIBE到底是如何做到的?
对抗学习框架
关键创新,在于采用了对抗学习框架。
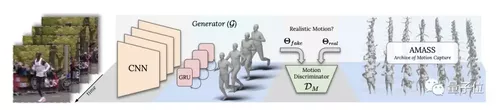
一方面,利用时间(temporal)生成网络,预估视频序列中每个帧的SMPL人体模型参数。
注:SMPL,即A Skinned Multi-Person Linear Model,马普所提出的一种人体建模方法。
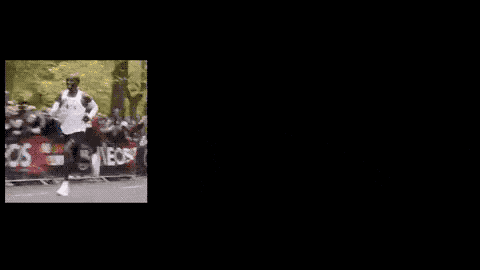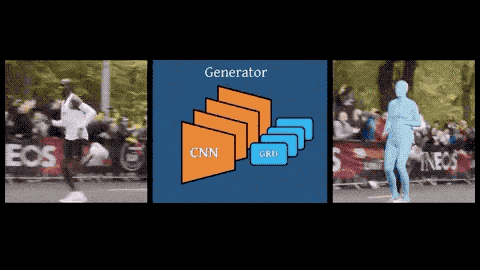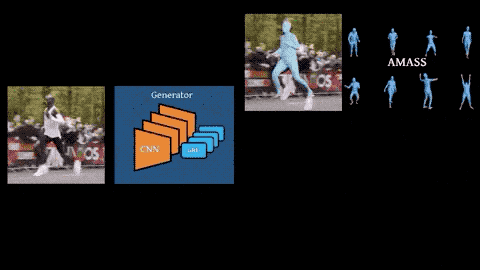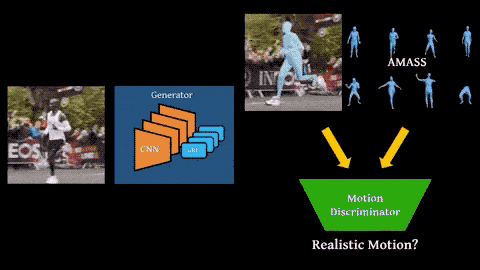
具体来说,给定一个单人视频作为输入,使用预先训练的CNN提取每个帧的特征。
训练双向门控循环单元组成的时间编码器,输出包含过去和将来帧中信息的潜在变量。
然后,利用这些特征对SMPL人体模型的参数进行回归。
另一方面,运动鉴别器能够以SMPL格式访问大量人体动作。
将生成器生成的样本,和取自AMASS的样本作为鉴别器的输入,训练其辨别真实动作和“伪”动作。
AMASS是一个大型开源3D运动捕捉数据集,包含40个小时的运动数据,344个主题,超过11000个动作。(项目地址见文末)

由于循环网络在顺序处理输入时会更新其隐藏状态,最终的隐藏状态将保留该序列中信息的摘要。研究人员在鉴别器中引入了自注意力机制,来放大最终表示中最重要的帧的作用。
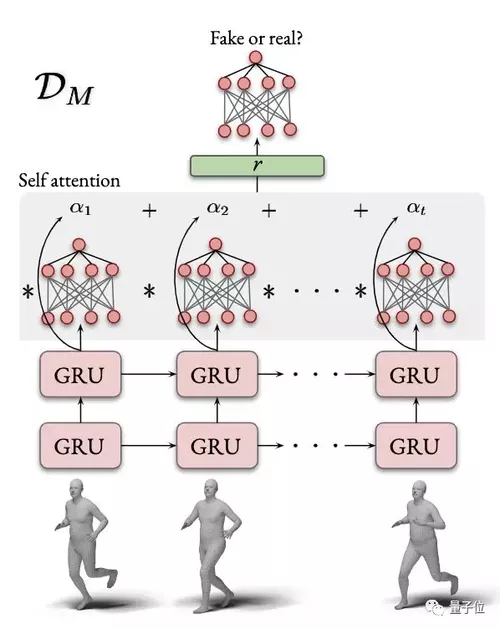
多项性能指标达SOTA
老规矩,先来看下数据集。
对于训练数据集,混合使用了2D和3D数据集。PennAction和PoseTrack是唯一的ground-truth 2D视频数据集,3D数据集方面采用的是MPI-INF3DHP和Human3.6M。除此之外,还利用AMASS进行对抗性训练,获得真实样本。
在评估、对比方面,采用的数据集主要是3DPW、MPI-INF3DHP和Human3.6M。
那么,在训练后,在上述三个数据集上,采用最先进方法结果的比较,如表1所示:
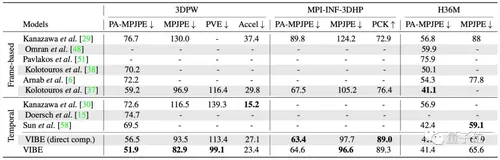
△表1:在3DPW、MPI-INF-3DHP、H36M三个数据集上,各个最先进方法的结果比较
研究人员在这个三个数据集上,将VIBE和其他最先进的,基于帧和时间的模型做了性能比较。
可以不难看出,VIBE在3DPW和MPI-INF-3DHP这两个数据集上的表现是比较好的,性能上超越了其他模型。
在H36M数据集上,也得到相对接近于目前最优值的结果。
除此之外,表1中还涉及了一个加速度误差(acceleration error),从数值上可以看出,VIBE与基于帧的HMR方法相比,误差是较小的,也就是结果更加平滑。
但与基于时间的模型相比,加速度误差却比较高,但是这里却存在一个问题,基于时间的模型,采用了较为“激进”的平滑处理方式,会使得快速运动视频的准确性降低,如下图所示。

△上:VIBE;下:基于时间的HMR。
VIBE模型能够恢复正确的全局旋转,这是前人提出的方法中存在的一个比较严重的问题,这也是在表1中MPJPE和PVE指标比较好的原因。

此外,实验还证明,有和没有运动鉴别器DM,对模型的性能也具有较大的影响,如表2所示。
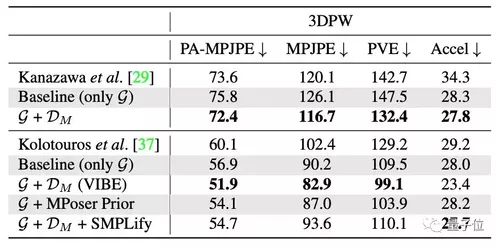
△表2:运动鉴别器DM的消融实验
还尝试了几种自注意力的配置,将VIBE方法与静态合并方法进行了比较,结果如表3所示。
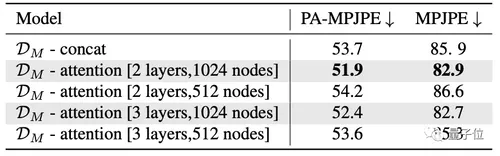
△表3:自注意力的消融实验
GitHub已开源,快速上手玩Demo
除了吊炸天的实验效果,另一个令人激动的消息是,论文代码已开源!
研究人员在实现过程中采用的是Pytorch,实验设备需要同时支持 CPU 和 GPU 的推理,在RTX2080Ti上速度高达30帧/秒,以及是在3DPW 和 MPI-INF-3DHP 数据集上实现 SOTA 结果。

准备工作也很简单,首先要克隆这个项目,只需输入:
git clone https://github.com/mkocabas/VIBE.git
使用 pip 或 conda 安装需求:
# pip
bash install_pip.sh
# conda
bash install_conda.sh
接下来在这个GitHub项目中,下载好数据集,可以运行:
bash prepare_data.sh
然后就可以运行已经准备好的demo代码了(可以在任意视频上运行VIBE):
# Run on a local video
python demo.py --vid_file sample_video.mp4 --output_folder output/ --display
# Run on a YouTube video
python demo.py --vid_file https://www.youtube.com/watch?v=wPZP8Bwxplo --output_folder output/ --display
当然,如果你没有上述实验所需要的设备、环境,可以采用Google Colab。





