
在计算机领域,缓存是一种高速的数据存储层,它可以更高效地利用已有的资源,提高产品的响应速度和可用性。缓存在计算机中随处可见,从底层硬件到操作系统,再到我们日常使用的应用等。接下来这篇文章将主要介绍应用层面的缓存机制的分类和工作原理。
缓存的优缺点
缓存的使用主要有以下这些优点:
- 加速读写:缓存通常都是全内存形式,对内存的直接读写会比传统的存储层如MySQL,性能好很多
- 避免重复计算: 通过提前缓存一些复杂计算可以降低后端对CPU、IO资源的需求,同时也大幅度减少响应时间
- 缓解数据库压力:使用缓存可以避免频繁对数据库的查询访问,大大降低数据库的压力
同时,也会带来一些额外的成本:
- 代码维护成本:需要同时处理缓存层和存储层之间的代码逻辑,增加开发者的成本
- 数据不一致性:需要处理缓存与真实数据源之间一定时间内的数据不一致性,同时还需要有合适的机制进行数据更新
- 运维成本:引入缓存层,如Redis等,需要做高并发相关的集群
常见缓存
应用服务器缓存
该缓存是最常见的缓存机制,就是在应用服务器本地内存中保存一定的缓存数据,一旦用户请求发送过来,先查看内存中是否存在缓存,如果命中,则返回给用户。否则,就从数据库中读取数据并写入本地缓存。
该方式十分简单,很容易实现,不过缺点是在大型应用中多台服务器每个服务器都要维护自己的本地缓存,由于负载均衡的影响,每次请求都会分发到不同的服务器上,这大大增加了缓存失效的概率。
分布式缓存
为了解决上述的问题,分布式缓存会将数据分布在多个缓存服务器上,每个缓存服务器都会有一部分数据,在请求到来时,可以根据哈希算法定位到具体的缓存服务器上。
在分布式缓存架构中,通常还会有一台配置服务器(zookeeper)。请求到达时在会先去配置服务器上读取具体的缓存服务器信息,最后配置服务器会将请求转发到具体的缓存服务器上。
CDN
内容分发网络(CDN)也是一种常见的缓存,它主要用户缓存一些静态的网站资源,如图片、多媒体等。当用户发送请求时,该请求会先到达根据用户所在地请求最近的CDN服务器,如果命中缓存,则直接返回数据给用户。否则,该CDN服务器会向后端服务器请求资源并将其缓存到本地上,以便下次用户发送请求时能直接响应。
缓存同步机制
虽然缓存机制有很多的好处,但它也需要一些额外的机制来保障数据和缓存之间的一致性。如果数据库的数据发生变更,缓存应该失效并保持同步。根据不同的业务需求,可以采用不同的缓存同步机制。以下是常见的缓存同步机制:
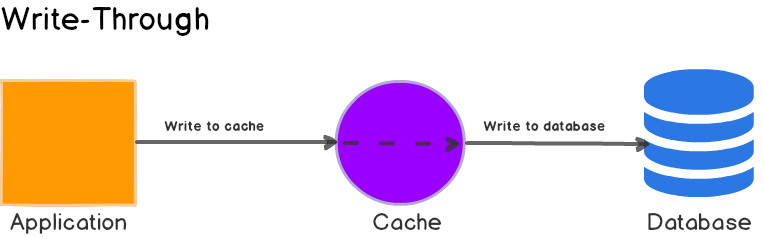
Write-through cache
直写模式(Write-through)是指在数据更新时,同时写入缓存服务器和远程数据源。此模式的优点是操作简单,可以很容易保持数据的一致性;缺点则是因为数据修改需要同时写入存储,数据写入速度较慢。
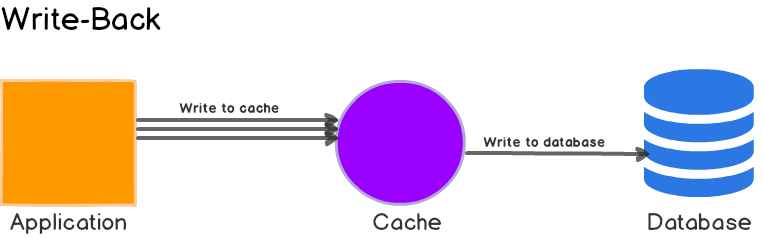
Write-back
回写模式(Write back)是指只写缓存,不写数据源。只有当缓存被淘汰时或在某一时刻统一进行同步缓存。此模式的优点是,只有速度很快,由于不涉及后端的数据存储操作,可以达到低延迟,高吞吐量的效果。但同时一旦缓存挂了就有数据丢失的风险,该模式通常适合一些逻辑简单,不需要事务的统计任务等。
Write-around cache
Write Around模式是直接将数据写入到数据源中,只有当数据被读取的时候,才会写入缓存中去。该模式对于像实时日志等数据只写一次,并且很少会被读取等场景比较实用。
缓存淘汰(Cache Eviction)策略
由于内存限制等因素,在采用缓存时候,还要考虑使用合适的缓存淘汰策略。
LRU
LRU(Least Recently Used)算法会淘汰最久没有访问的数据。该算法由于比较常见,这里简单介绍一下它的实现方式。我们可以采用哈希表和双向链表的方式来实现:
class Node {
private final String key;
private String value;
private Node prev;
private Node next;
public Node(String key, String value) {
this.key = key;
this.value = value;
}
}
public class LRUCache {
private final Map<String, Node> map;
private final int capacity;
private Node head = null;
private Node tail = null;
public LRUCache(int capacity) {
this.map = new HashMap<String, Node>();
this.capacity = capacity;
}
public String get(String key) {
if (!map.containsKey(key)) {
return null;
}
Node node = map.get(key);
deleteFromList(node);
setListHead(node);
return node.getValue();
}
public void put(String key, String value) {
if (map.containsKey(key)) {
Node node = map.get(key);
node.setValue(value);
deleteFromList(node);
setListHead(node);
} else {
if (map.size() >= capacity) {
map.remove(tail.getKey());
deleteFromList(tail);
}
Node node = new Node(key, value);
map.put(key, node);
setListHead(node);
}
}
}
LFU
LFU(Least Frequently Used)算法会根据缓存命中频率淘汰最少被访问的缓存数据。
MRU
MRU(Most Recently Used)算法与LFU算法相反,会将最近访问的数据先淘汰掉。
FIFO
FIFO(First In First Out)算法则根据先进先出的算法进行淘汰旧有缓存数据。
LIFO
LIFO(Last In First Out)算法则根据后进先出的方式进行淘汰旧有缓存数据。
RR
RR(Random Replacement)会随机替换旧有缓存数据。





