
长文。巨长。
本文的依据是我学习整个Spark的学习历程。在这里,我会从几个方面来跟大家一起讨论。Spark 是什么?Spark 跟 Hadoop 有什么渊源?Spark 有哪些方便的组件?什么场景下用 Spark ,如何使用?以及用什么样的姿势来学习 Spark 会比较好?
Apache Spark™ is a fast and general engine for large-scale data processing.
Spark就是一个能够快速以及通用的处理大规模数据的引擎。怎么理解这句话呢?
Spark 就是一个处理引擎,它提供了类似 map , reduce , groupBy,persist 这些操作,来方便地对数据进行各种各样的并行处理。它以一个有向无环图来定义一个应用,方便对任务的容错和重试处理。它定义了一个叫 RDD 的弹性数据结构,将所有的数据和中间结果都尽可能缓存在内存中,形成一个分布式内存数据集。
然后为什么说它只是一个处理引擎呢?从数据源角度看, Spark 可以从 HBase、ElasticSeach、Hive 等渠道获取。从运行资源角度看, Spark 可以跑在 Spark集群,Hadoop 集群 ,Mesos 集群上,所以它只是一个处理引擎。至此它拥有了快速的,通用的属性,也就成为一个通用的大数据处理引擎。
Spark 和 Hadoop 有什么渊源?
容我细细道来。说起 Spark ,我们不可不提到它的老前辈 MapReduce 。
MapReduce 是一个编程模型 ,可以实现运行在规模可以灵活调整的由普通机器组成的集群上,一个典型的 MapReduce计算往往由几千台机器组成、处理以 TB 计算的数据。 这在 Google 发出《MapReduce: Simplified Data Processing on Large Clusters 》这篇论文之前,几乎是不可想象的。并行计算,容错机制是那么的高效和可靠。开源的 Hadoop 就实现了 MapReduce ,以及它的基石分布式文件系统 HDFS (Hadoop Distribute File System),也即是 《Google File System》 的开源版实现。
既然这么高效那为什么还会出现 Spark 呢?一个巨大的原因是,Hadoop 把数据的中间结果放到了HDFS 上了,这就导致处理的过程虽然非常可靠,但是耗时也非常非常长。当初写 Spark 是因为需要进行进行大规模数据的机器学习,总所周知机器学习需要不断访问数据不断访问数据不断迭代,这对于 MapReduce 来说是致命的,效率很慢,所以实现了Spark。
那么Spark发展至今,有哪些方便的组件呢?如下图。
val datas:DataFrame = hc.sql("SELECT SEX,TALL FROM PERSONS");
val model = LogisticRegressionWithSGD.train(datas, 50)
KafkaSteaming.createStream(x => model.predict(x.SEX));短短几行代码可能就涵盖了,Spark SQL,MLLib,SparkSteaming 。这几个组件分别是干啥的呢?Spark Core Engine 提供了最基础的操作,如 map , reduce , reduceBy , groupBy 等基础操作,提供了 RDD 和有向无环图的管理结构,提供了容错机制。
SparkSQL 提供了对于 Hive,HBase等数据库的操作,以 SQL 作为统一的查询规范进行数据访问。不仅如此 Spark 还提供了 DataFrame 的操作方式将数据的操作抽象化为对对象的操作。
MLLib 提供了机器学习相关的流水线处理 Pipline ,以及实现了绝大部分机器学习的组件,如 LinearRegression 、GBDT、LogisticRegression、SVM等,可以非常方便地用于大规模数据的机器学习。
GraphX 提供了大规模的图处理及图计算算法,其中有传统的 stronglyConnectedComponent 强直通性算法,也有实现了 PageRank 的新型的 Pregel 分布式图计算框架,以及实现了 Label Propagation Algorithm 的机器学习标签传播算法。
而 SparkSteaming 则提供了批量流计算,用于接收来自 Kafka 或者 Twritter 消息中间件的数据,进行实时处理。
那么我们应该在什么场景下使用 Spark ,以及如何使用呢?
1、有钱的时候
Spark 需要非常多非常多的内存,比 MapReduce 多多了,MapReduce 只是需要少量的内存和大量硬盘,所以跑 Spark 来说会比较贵。
2、迫切需要快速处理大数据量的时候。
如果不是很迫切,那么使用 Hadoop 和 Hive 可能更加合适,因为它们也可以完成绝大部分的数据处理,并不是一定要用 Spark。
3、需要处理大规模图的时候
当前做巨大图计算的引擎来说,Spark 可以说是最合适的。
4、其他的计算框架需要 Spark 作为计算引擎的时候。
比如Hive on Spark,比如 Impala 。Spark 可以作为一个分布式计算引擎嵌入到其他计算系统中。
Spark 运行架构是怎样的?
Spark 任务由 Driver 提交 Application 给 Master ,然后由 Master 将 Application 切分成多个 Job ,然后调度 DAG Scheduler 将 Task 切分成多个 stage ,分配给多个 Worker,每个Worker 接收到 TaskSet 任务集后,将调度 Executor 们进行任务分配,每个 Executor 都有自己的 DataSet 用于计算。通讯是使用akka。
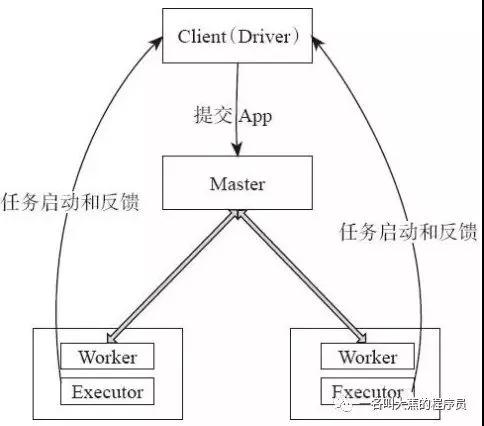
Driver会记录所有stage的信息。要是stage切分过多,那占用Driver的内存会非常多。若task运行的stage失败,默认会进行4次重试,若4次重试全部失败,SparkContext会停止所有工作。
Driver也会记录stage的运行时间,如果task运行的stage时间太久,Driver可能会认为这个job可能失败了,会重新分配一个task给另外一个Executor,两个task都会同时跑,谁先跑完谁交差,另外一个只有被干掉的份。
从运行模式来看,Spark有这么几种方式可以运行。
local
mesos
standalone
yarn-client
yarn-cluster
下面一个一个来解剖它们。
local,顾名思义,是跑在本地的,指将Driver和Executor都运行在提交任务的机器上。 local[2] 代表启动两个线程来跑任务, local[*]代表启动任意数量需要的线程来跑Spark任务。
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核。Mesos最初是由加州大学伯克利分校的AMPLab开发的,后在Twitter得到广泛使用。
Spark on mesos,是指跑在mesos平台上。目前有两个模式可以选择,粗粒度模式(CoarseMesosSchedulerBackend)和细粒度模式(MesosSchedulerBackend)。粗粒度模式下,Spark任务在指定资源的时候,所分配的资源将会被锁定,其他应用无法share。在细粒度模式下,Spark启动时Secheduler只会分配给当前需要的资源,类似云的想法,不会对资源进行锁定。
Spark on standalone,是指跑在 Spark 集群上。Spark集群可以自成一个平台,资源由Spark来管理,不借助任何外部资源,若在测试阶段可以考虑使用这种模式,比较高效,但是在生产环境若有多个任务,不太建议使用这种方式。
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Spark on yarn,是指跑在Hadoop集群上。Hadoop提供的yarn是一个比较好的资源管理平台,若项目中已经有使用Hadoop相关的组件,建议优先使用yarn来进行资源管理。
将Spark任务提交到yarn上同样有两个模式,一种是yarn-client,一种是yarn-cluster。
yarn-client将SparkContext运行在本地,Driver也运行在本地,这种模式一般不推荐,因为在分配Driver资源的时候,提交的机器往往并不能满足。
yarn-cluster,将任务提交到Hadoop集群上,由yarn来决定Driver应该跑在哪个机器,SparkContext也会运行在被分配的机器上,建议使用这种模式。
无论是yarn-client还是yarn-cluster,都是在yarn平台的管理下完成,而Spark on yarn目前只支持粗粒度方式(Hadoop2.6.0),所以在任务多,资源需求大的情况下,可能需要扩大Hadoop集群避免资源抢占。
Spark 使用的时候有哪些坑呢,如何使用呢?
00000:Spark on yarn 启动的时候一直在 waiting。
第一种可能,队列资源不足,所有的资源都在被其他同学占用ing。
解决方案:把那个同学打晕,然后kill application。
第二种可能,设置的 Driver 或者 executor 的 cpu 或者 memory 资源太多。
解决方案:看看队列资源有多少,拿小本本计算一下究竟能申请多少,然后给自己一巴掌。如果集群资源太烂,单台机器只有16G,那你就别动不动就申请一个 driver 或者 executor 一下就来个32G了。
第三种可能,程序报错了,一直在重试。
解决方案:滚回去debug去。
特别提醒:Spark 默认是有10%的内存的 overhead 的,所以会比你申请的多10%。
00001:Driver 抛 OutOfMemory Exception
很明显嘛,就是driver的内存不足了,尝试看一下哪个地方占用内存太多了,特别提醒一下,stage的切分,task的分配都是在Driver 分配的,数量太多的话会爆炸。以及collect(),count()等这些操作都是需要把所有信息搜集到driver端的。
解决方案:打自己一巴掌,然后看dump日志或者看看自己的代码,是不是哪里搞错了。如果一切都很合理,那就提高一下内存吧。
00010:executor 抛 OutOfMemory Exception
内存不足。哇,那这个可能性就多了。
是不是数据量太大 partition 数太少?太少了就多加点 partition 。
是不是产生数据倾斜了?解决它。
是不是某个操作,比如flatmap,导致单个executor产生大量数据了?
是不是请求的内存实在太少了?
00011:executor 抛 is running beyond physical memory limit
哇,你的集群资源超分配了,物理资源被其他团队用了,GG思密达,快拿起40米长木棍。把那个人抓出来。
00100:driver 或者 executor 抛 OutOfMemoryError: GC overhead limit exceeded
出现内存泄漏或者真的集群资源不够,一直在full GC超过次数限制了,仔细检查一下哪些东西占用内存太多,是不是RDD持久化占用太多资源了,还是数据有倾斜,还是真的partition太少导致每个partition数据太多。
00101:运行 GraphX 的时候 driver 抛 OutOfMemory Exception
运行 GraphX 的时候因为会迭代计算,所以会产生非常非常多 stage,这时候 driver 可能没有足够多的内存可以放下这些 stage 和 task 的状态,很容易就出现 OOM。这时候能做的事情就四个,第一增加 driver 内存,第二降低 partition 的数量,第三减少 Pregel 的迭代次数减少stage的数量,第四优化图的切分策略。
00110:大对象网络传输慢。
放弃默认的 Java Serialization,改用 Kryo Serialization。
小对象用广播的模式,避免全局 join。
GraphX 来说改善图切分策略,减少网络交互。
GraphX 尽量单台机器配置高点,可以尽量让更多的 partition 在同一台机器。
00111:SparkStreaming 消息堆积。
调整窗口时间,着重分析消息消费过程的瓶颈并调整相应的资源,尽量降低单笔计算时间。然后根据收集的信息再根据吞吐量来决定窗口时间。
01000:进行 Shuffle 的时候报 Spark Shuffle FetchFailedException。
数据在 Shuffle 的时候中间数据量过大或者数据产生了倾斜,导致部分目标机器崩溃。通过分析崩溃的时候的任务,改善数据 Shuffle 时的数据分布情况。
那应该以怎样的姿势来学习 Spark 呢?
Step1:环境搭建
自己开虚拟机或者云主机搭好Hadoop,Spark,Hive,sqoop,原生的那种,可以直接实现为伪分布式。可以试试我下面推荐的这种版本搭配,这是CDH5.8.x的个组件版本组合。
Apache Zookeeper 3.4.5 + Apache Hadoop 2.6.0 + Apache HBase 1.2.0 + Apache Hive 1.1.0 + Apache Spark 1.6 + Apache Pig 0.12.0 + Apache Flume 1.6.0 + Apache Kafka 0.9.0 + Apache Sqoop 1.4.6/1.99.5
注意事项:版本搭配要合理,不然会有很多坑。
Step2:数据准备
使用Spark生成500万数据,包含[身份证,手机号,日期,性别,身高]五个字段。其中身份证格式为6位,手机号为6位,日期为yyyy-mm-dd格式,性别为F、M,身高为160-190随机数。手机号其中有100万必须为10086,都必须为合理的随机数据,不能是序列,结果保存到Hive表中。
Step3:MapReduce初探
使用 Step2 产生的数据进行关系生成,相同手机号的人认为有关系,可以使用RDF 的组织方式进行保存。直接过滤空数据以及6位号码相同的,若发现同一号码导致的关系数超过3000,剔除,结果先保存到Hive中。
Step4:内存调优及算法实现
利用 Step3 生成的关系,利用GraphX和SLPA进行社区划分,可以借鉴 Spark 的 Pregel 框架,阅读 LPA 实现的源码。当然希望你能改造为SLPA,SLPA需要自己实现,要注意思考GraphX的局限性。
Step5:去做更多的事,实现更多的功能。
投入到更多的数据处理工作中,继续一些亿级别的调优以及机器学习的学习中,不断学习不断提高自己的水平。scala 是 Spark 的原生语言,但是现在也有很多的数据分析师在使用 R 在 Spark 上进行数据分析,也有数据开发工程师使用 Python 在 Spark 进行机器学习,甚至还实现一些深度学习的算法,打通了Tensorflow,这些在未来都可能成为主流。
最后总结一下 Spark:
1、Spark 跟 MapReduce 如出一辙。
2、Spark 很快,是一个计算引擎,其他组件都是可拔插的,但需要耗费很多内存很多钱。
3、不是非得用Spark,还有很多其他的解决方案。
4、Spark 需要循序渐进学习,不断实践,纯理论没什么用。
完。




