
简单说监控的话,至少要包括采集端,收集端,存储端,展示端。一个比较简单的逻辑如下
在这个逻辑下,随着业务的扩充,我们有了新的挑战。
挑战
- 存储的数据比较重要
监控在排查问题,复盘的时候是比较重要的。例如类似双十一这种数据,肯定是要可靠保存并且下一年要做对比的。所以这里的存储不能是一个机器的磁盘,而是分布式高可靠的存储。这样保证了意外情况下数据可以准备的查找。 - 机器太多,一个collector撑不住
业务肯定有增长,原来一台机器接收数据也有撑不住的时候,所以collector也必须多个,这里就牵扯到一个问题,多个collector应该如何工作。这里是需要一个压测的,得到一个collector的能力边界。然后进行细分。我们常见的有几种方式。
一种是有规划的知道全局,那么每个collector可以实现规划抓取或者接收。这里就需要一个配置服务中心,这个可以给collector,也可以给agent。给agent的话,就是agent自动连接对应的collector,给collector的话,就是collector进行拉取的路子。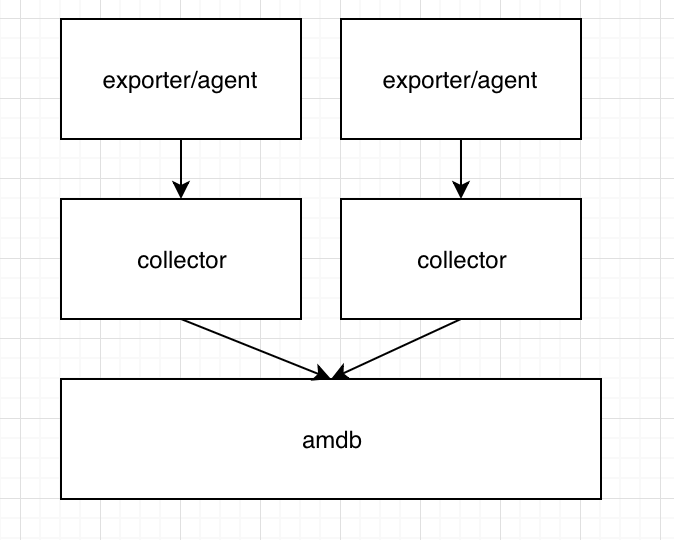

这种规划的模式缺点是不太灵活,进程或者机器不可能完全没有意外,需要做高可用,思路有两种,一种是挂掉的机器分摊原来的压力。例如5个collector对应5000节点,现在collector挂掉一个,那么就是4个collector对应5000。这里需要一个分配策略在里面。还有一种方式是每个collector做主备关系,冷备的话的就是主挂掉,有探测能把备拉起来。热备的话一般是双活方案,连个同时在拉取和接受数据。一般的设计collector不存数据,数据在分布式的存储里。
如果是prometheus这种抓取和存储一起的,他本身也会负责一部分查询的话,就需要双活方案了,或者把缓存提出来。
下面是双活的样子
注:双活方案拉比推更适合,如果想用推的话,可以选择把数据都推倒一个集中点,那个点进行拉取操作。
- 存储查询的压力
现在所有的数据都在storage上,数据的及时性以及查询压力都在存储,这种架构的模式的瓶颈最终落在了存储,所以存储这边需要适当的优化。最简单的一种方式就加机器,例如hbase这种,加regionserver是可以有效缓解的。如果是其他存储呢?
我们考虑监控的一个特点,一般是查询特定的或者近期的数据。所以数据是有热点的。越远的查询的可能性越小,不过类似双十一这种是有数据意义的数据。
所以可以组织热点数据的一个稳定查询。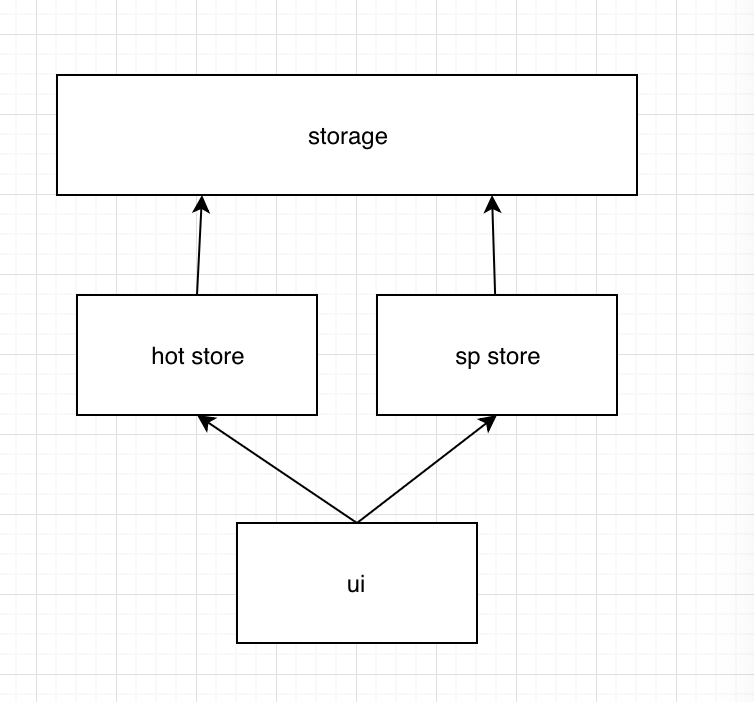

小结
设计根据场景来区分,不同的场景其实方案差别挺大的,这些优化都是为了特定场景准备的。





