
TensorFlow 源码
截止到目前为止,TensorFlow 在 【Github】 的 Contributors 已经接近900人,Fork 30000次。
学习这么庞大的开源项目,首先必须要搞清楚其代码组织形式,我们先来看目录结构:

Project 目录分为4个:
1)tensorflow
核心代码目录,图中可以看到其子目录结构,后面我们会展开讲解。
2)third_party
第三方库,包括:eigen3,fft2d,hadoop,mkl,probuf 等。
3)tools
只有两个文件 bazel.rc 和 tf_env_collect.sh。
4)util/python
存放用到的 python 工具。
另外一个比较重要的文件是 configure,用于配置 tensorflow 的安装环境。
对于 tensorflow 核心目录,里面比较关键的几个模块:
1.1)core
这是 tensorflow 的核心代码模块.
1.2)tensorboard
不用解释,应该都清楚,这是可视化工具 tensorboard 的代码目录。
1.3)stream_executor
tensorflow 流图的并行计算执行,核心代码。
1.4)go,java,python
主要的第三方 API。
1.5)contrib
存放有其他项目贡献者添加的相关贡献代码,非核心官方代码,有具体方向的应用可以参考这里面的模块。
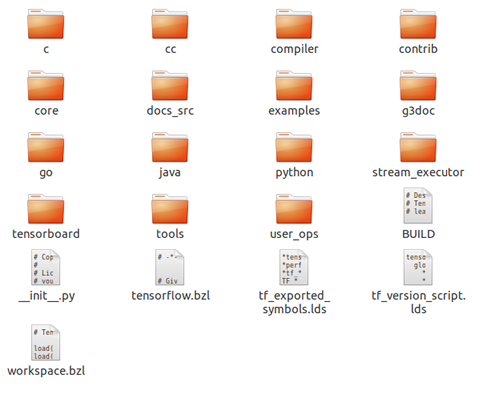
二. 核心代码目录 Core
Core 目录是代码最核心的部分,包含 框架、图、会话、runtime 最核心的部分,主要模块包括:
common_runtime:公共运行库,包含 会话(session)、线程(thread),内存管理(memory), 设备调度(device)等基本运行库。
distributed_runtime:分布式运行库,与上面类似,作为分布式情况下的运行库,提供运行支撑。
framework:框架基础模块定义,主要是通用组件的结构格式定义;
graph:计算流图相关基础操作(类结构),包括 拆分、合并、执行 等操作,被外面的 executor 调用;
kernels:核心操作定义,像常用的运算 matmul,sigmoid 等操作;
lib:基础库用于内部调用,包括 hash、io、jpeg、math 等;
ops:对 kernel 下的op进行注册和对外声明;
protobuf:Google 的传输交换模块,用于传输时的数据序列化;
三. Graph 与 Session
关于 Graph 和 Session 前面已经有篇幅讲过,概念上可能大家并没有完全理解,本篇再讲一下。
Graph
首先搞清一个概念,Graph 是 Tensorflow 必须要存在的,是灵魂核心,你所看到的任何一个 图都是通过 Graph来组织的。

再来看一段你已经很熟悉的代码:
>>> import tensorflow as tf
>>> str = tf.constant("Hello World!")
>>> se = tf.Session()
>>> print se.run(str)
没看到 Graph 的创建对不对? 实际上在你创建 Session 的时候,系统自动为你创建了一个 默认Graph,用于接下来所有 OP 的组织和存放。
某些情况下,你可以同时维护两个以上的 Graph,比如我们经常会遇到这样一句, tf.Graph.as_default()
curr_graph = tf.Graph()
with curr_graph.as_default():
c_val = tf.constant(1.0)
assert c_val.graph is curr_graph
在定义 OP 操作的时候可以选择Graph 作为 default,那么你所创建的 OP 就建立在对应 Graph 下面了。
Session
TensorFlow 的 Session 用法你可能比较熟了,来回顾一下:
# method 1
sess = tf.Session()
print sess.run(…)
sess.close()
# method 2
with tf.Session() as sess:
print sess.run(…)
# method 3 - 仅用于交互式环境
sess = tf.InteractiveSession()
a = tf.constant(1.0)
b = tf.constant(2.0)
c = a + b
# 我们直接使用'c.eval()' 而不是'sess.run'
print(c.eval())
sess.close()
对于 Graph 和 Session 的关系,需要记住,Graph 可以在对应多个 Session 中执行。





