
前言
字符串匹配算法是常见的一种字符串操作,其是在一个主字符串中查找一个子字符串(也叫模式串),即判断模式串是否是主字符串的一个子串。最简单的做法是两个循环分别比较每个字符,直到找到匹配的位置或遍历结束。这种做法需要消耗 O(m * n) (m 表示主字符串的长度,n 表示模式串的长度) 的时间复杂度。而 KMP 算法则可以通过跳过一些重复的比较过程将时间复杂度控制在 O(m + n) (m 表示主字符串的长度,n 表示模式串的长度)。
传统字符串匹配算法
基本过程
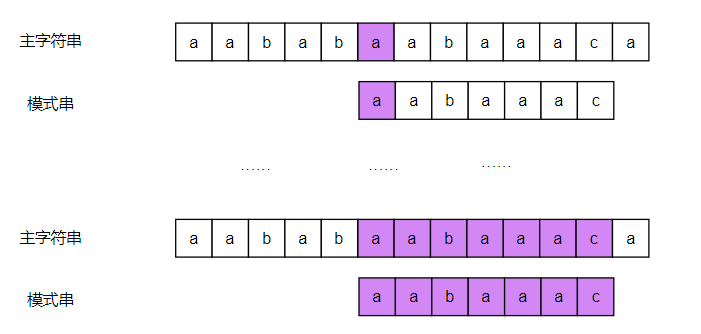
传统的字符串匹配算法,是用两个循环,外层循环遍历主字符串,里层循环遍历模式串。在外层循环的每一次循环过程,都以当前主字符串指针的位置为起始位置,遍历 n 个字符( n 为模式串长度),与模式串的字符一 一进行比较,直到所有字符匹配或遍历结束。其过程大致如下图所示
当主字符串和模式串的当前位置字符匹配时,指针向后移动一位

当发现有字符不匹配时,主字符串的查询起始位置相比上次的查询起始位置加一,模式串的查询起始位置归零

重复上述过程直到所有字符匹配或遍历结束
程序代码
/**
* 字符串匹配:如果 needle 是 haystack 的子字符串,则输出最先匹配的 haystack 的起始下标,否则返回 -1
* 输入参数:haystack 主字符串; needle 模式串
* 返回:-1 或其他非负整数。-1:needle 不是 haystack 的子字符串,其他非负整数:最先匹配的 haystack 的起始下标
*/
public int strStr(String haystack, String needle)
{
if (haystack == null || needle == null || needle.length() > haystack.length())
{
return -1;
}
if (needle.length() == 0)
{
return 0;
}
for (int i = 0; i < haystack.length(); i++)
{
int j = 0;
for (; j < needle.length(); j++)
{
if (i + j >= haystack.length() || haystack.charAt(i + j) != needle.charAt(j))
{
break;
}
}
if (j == needle.length())
{
return i;
}
}
return -1;
}
KMP算法
由于传统的字符串匹配算法在面对字符不匹配时,会将模式串的查询起始位置归零,而主字符串的查询起始位置仅仅是相比上次增加一而已。从这个地方进行重新比较,将会产生大量的重复的比较。例如主字符串是abababababc,模式串是ababc,采用传统的字符串匹配算法将会对abab在主字符串abababababc中进行重复的比较。而实际上,在模式串c字符匹配失败时,由于abab的最长相同前缀后缀是ab,所以下次重新进行查询匹配时,模式串的查询起始位置可以从第三个字符开始,而主字符串的查询起始位置也可以从失配的地方开始。这就可以减少字符串ab的重复匹配,而这也就是KMP算法的主要思想。
基本过程
KMP算法主要是先对模式串求解其部分匹配表(网上也有称之为 next 数组),即字符串的最长公共前缀后缀字符串长度,主要是用来在字符串发生失配时决定模式串指针的移动。然后用两个指针分别指向主字符串和模式串,比较两个指针指向的字符是否相同,如果相同,则分别将指针向后移动一位,如果不同,则保持主字符串指针不动,将模式串的指针根据其部分匹配表(或 next 数组)移动位置,进行下一轮比较。
流程图
其大致流程如下图所示:

示例
仍以“传统字符串匹配算法”章节中的例子为例,KMP算法的匹配过程大致如下
当主字符串和模式串的的指针指向的字符匹配时,两者的指针均向后移动一位

当主字符串和模式串的指针指向的字符不匹配时,如果模式串指针不是在第一位,则保持主字符串指针不动,根据部分匹配表将模式串的指针进行移动;如果模式串指针在第一位,则保持模式串指针不动,将主字符串指针向后移动一位

重复上述过程直到所有字符匹配或遍历结束

部分匹配表的作用
部分匹配表是用来在字符匹配失败时决定模式串指针的移动的。那为什么这种方式有效呢。现在来解释一下为什么在字符不匹配时可以根据部分匹配表直接跳过模式串部分的字符,并且可以保持主字符串的指针不动。
首先,假设已经正确的求出了模式串的部分匹配表,在某个字符匹配失败时,模式串的前一个字符对应的部分匹配表的值为 n(为简单起见,假设为 2),根据KMP算法,可以得知模式串的指针应该指向第 3 个字符。如下图所示

可是为什么是第 3 个字符,而不是大于 3 的其他字符呢(为简单起见,假设为第 4 个字符)。如下图所示,假设可以指针跳到第 4 个字符,则意味着前 3 个字符与主字符指针的前 3 个字符相等,那么就可以推出刚才失配的位置前面的模式串子串的最长公共前缀后缀是 3 而不是 2,这与部分匹配表中的值 2 相矛盾,而在此之前已经假设了部分匹配表是正确的,所以在匹配失败时,模式串的指针只能跳到第 3 个字符而不是第 4 个字符。

因此在字符匹配失败时,可以根据部分匹配表直接跳到将模式的指针移动到正确的位置并且可以跳过一些无效的重复比较项,从而提高效率。
最长公共前缀后缀
部分匹配表是根据字符串的最长公共前缀后缀求出的。那么什么是字符串的最长公共前缀后缀呢。假设一个字符串的长度为 m ,那么字符串的最长公共前缀后缀即是满足以下要求的由 [0, n] 组成子字符串:
- 存在正整数 n,n <= m
- 由 [0, n] 组成的字符串与由 [m - n, m]组成的字符串相等
- 若 n == m,则要求所有字符都相等,若 n != m,则由 [0, n + 1] 组成的字符串与由 [m - n - 1, m]组成的字符串不相等
简单来说,就是一个字符串的最开始的前 n (n 要尽可能的大)个字符和最后的 n 个字符相等。例如:aaaaaa的最长公共前缀后缀是aaaaaa,而aaaabbbaaabb没有最长的公共前缀后缀,而aaaabbaaa的最长公共前缀后缀是aaa
部分匹配表求解过程
部分匹配表(也称为 next 数组),主要的求解过程是用两个指针,第一个指针指向第一个字符,第二个指针指向第二个字符,然后比较两个指针指向的字符是否相等,如果相等,则当前第二个指针指向的字符的部分匹配表值是第一个指针所在位置的下标加一,然后分别将两个指针向后移动一位;如果两个指针指向的字符不相等,则取出第一个指针的前一位字符对应的部分匹配表的值,将第一个指针跳到此位置,然后与第二个指针指向的字符进行比较,如果不相等则重复上述过程直到相等或回到第一个字符,如果回到了第一个字符还没有遇到字符相等的情况,则值是0,然后将第二个指针往后移动一位,否则将第一个指针所在位置的下标加一得到当前第二个指针指向的字符的部分匹配表值,然后分别将两个指针往后移动一位。重复上述过程直到第二个指针到字符串末尾结束。
流程图
其大致流程图如下

示例
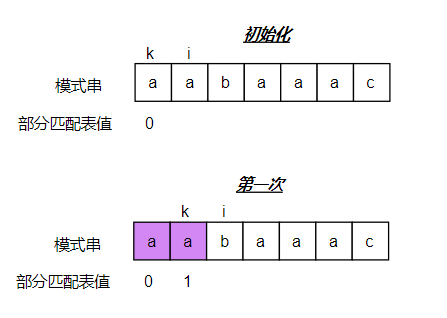
仍以“传统字符串匹配算法”章节中的模式串为例,其求解部分匹配表的流程大致如下
第一次循环时,由于 k 和 i 所在位置的字符相等,所以 i 位置的部分匹配表的值为 k 的下标位置加一,然后将 k 和 i 分别向后移动一位
第二次循环时,由于 k 和 i 所在位置的字符不匹配,所以将 k 移动到 k 前一个位置的部分匹配表的值对应的地方,即 0 的位置,此时与 i 位置的字符仍然不匹配,由于此时 k 已经是在字符串的第一个位置,所以此时 i 所在位置的部分匹配表的值为 0,然后将 i 向后移动一位
第三次循环时,由于 k 和 i 所在位置的字符相等,所以 i 位置的部分匹配表的值为 k 的下标位置加一,然后将 k 和 i 分别向后移动一位

第四次循环时,由于 k 和 i 所在位置的字符相等,所以 i 位置的部分匹配表的值为 k 的下标位置加一,然后将 k 和 i 分别向后移动一位
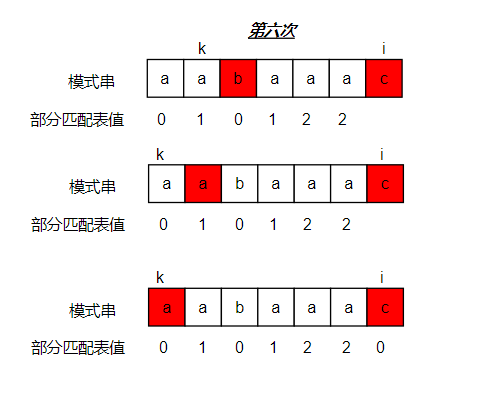
第五次循环时,由于 k 和 i 所在位置的字符不匹配,所以将 k 移动到 k 前一个位置的部分匹配表的值对应的地方,即 1 的位置,此时与 i 位置的字符相等,所以 i 位置的部分匹配表的值为此时 k 的下标位置加一,即 2,然后将 k 和 i 分别向后移动一位

第六次循环时,由于 k 和 i 所在位置的字符不匹配,所以将 k 移动到 k 前一个位置的部分匹配表的值对应的地方,即 1 的位置,此时与 i 位置的字符仍然不匹配,由于此时 k 不是在字符串的第一个位置,所以继续将 k 移动到 k 前一个位置的部分匹配表的值对应的地方,即 0 的位置,此时与 i 位置的字符仍然不匹配,由于此时 k 已经是在字符串的第一个位置,所以此时 i 所在位置的部分匹配表的值为 0。由于 i 已经到达字符串最后一位,所以结束循环。至此,字符串的部分匹配表也求解完毕
程序代码
/**
* 获取字符串的部分匹配表(next数组),即截止当前位置的字符串的最长公共前缀后缀的长度(第一个位置默认为0)
* 例如:输入"aabaaac"
* 输出:[0, 1, 0, 1, 2, 2, 0]
*/
public int[] getPartialMatchTable(String str)
{
if (str == null || str.length() == 0)
{
return null;
}
int[] partialMatchTable = new int[str.length()];
int pointer = 0;
partialMatchTable[0] = 0;
for (int i = 1; i < str.length(); i++)
{
while (str.charAt(i) != str.charAt(pointer) && pointer > 0)
{
pointer = partialMatchTable[pointer - 1];
}
if (str.charAt(i) == str.charAt(pointer))
{
partialMatchTable[i] = pointer + 1;
pointer++;
}
else
{
partialMatchTable[i] = 0;
}
}
return partialMatchTable;
}
/**
* 字符串匹配:如果 needle 是 haystack 的子字符串,则输出最先匹配的 haystack 的起始下标,否则返回 -1
* 输入参数:haystack 主字符串; needle 模式串
* 返回:-1 或其他非负整数。-1:needle 不是 haystack 的子字符串,其他非负整数:最先匹配的 haystack 的起始下标
*/
public int strStr(String haystack, String needle)
{
if (haystack == null || needle == null)
{
return -1;
}
if (needle.length() == 0)
{
return 0;
}
int[] partialMatchTable = getPartialMatchTable(needle);
int index = 0; // 模式串的指针
int i = 0; // 主字符串的指针
while (i < haystack.length())
{
if (haystack.charAt(i) == needle.charAt(index))
{
if (index == needle.length() - 1)
{
return i - index;
}
index++;
i++;
}
else
{
// 如果模式串指针大于0,说明已经进行了部分匹配,此时只需要根据部分匹配表移动模式串的指针即可,不需要移动主字符串的指针
if (index > 0)
{
index = partialMatchTable[index - 1];
}
// 如果模式串指针为0,说明第一个字符就匹配失败,此时需要移动主字符串指向到下一个位置
else
{
i++;
}
}
}
return -1;
}





