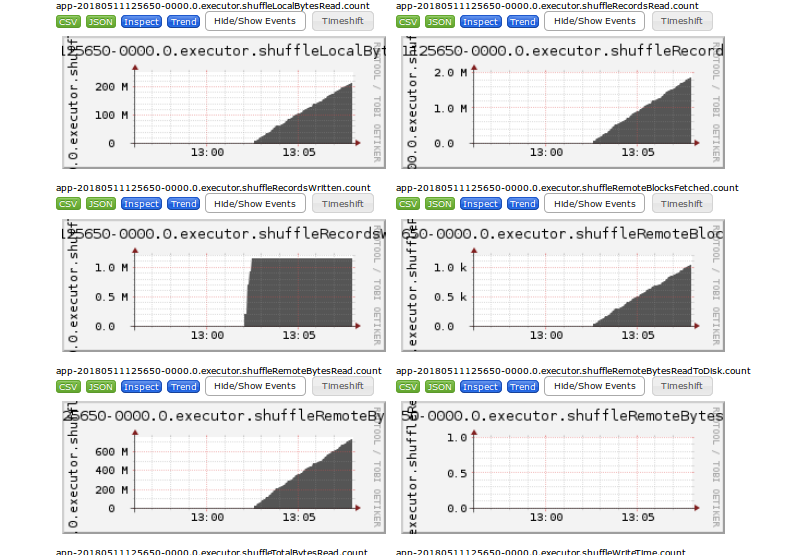
这次与上次spark 2节点2g数据orderby性能测试和疑惑点的不同点:
1. 输入数据在两台机器上都有拷贝,读取时直接本地读取
2. 直接输出数据到本地,每台机器上输出的是自己运行的分区
读取数据时slave5仍然只读了4个分区,等会可以看出原因,读取数据时的tasks如下:
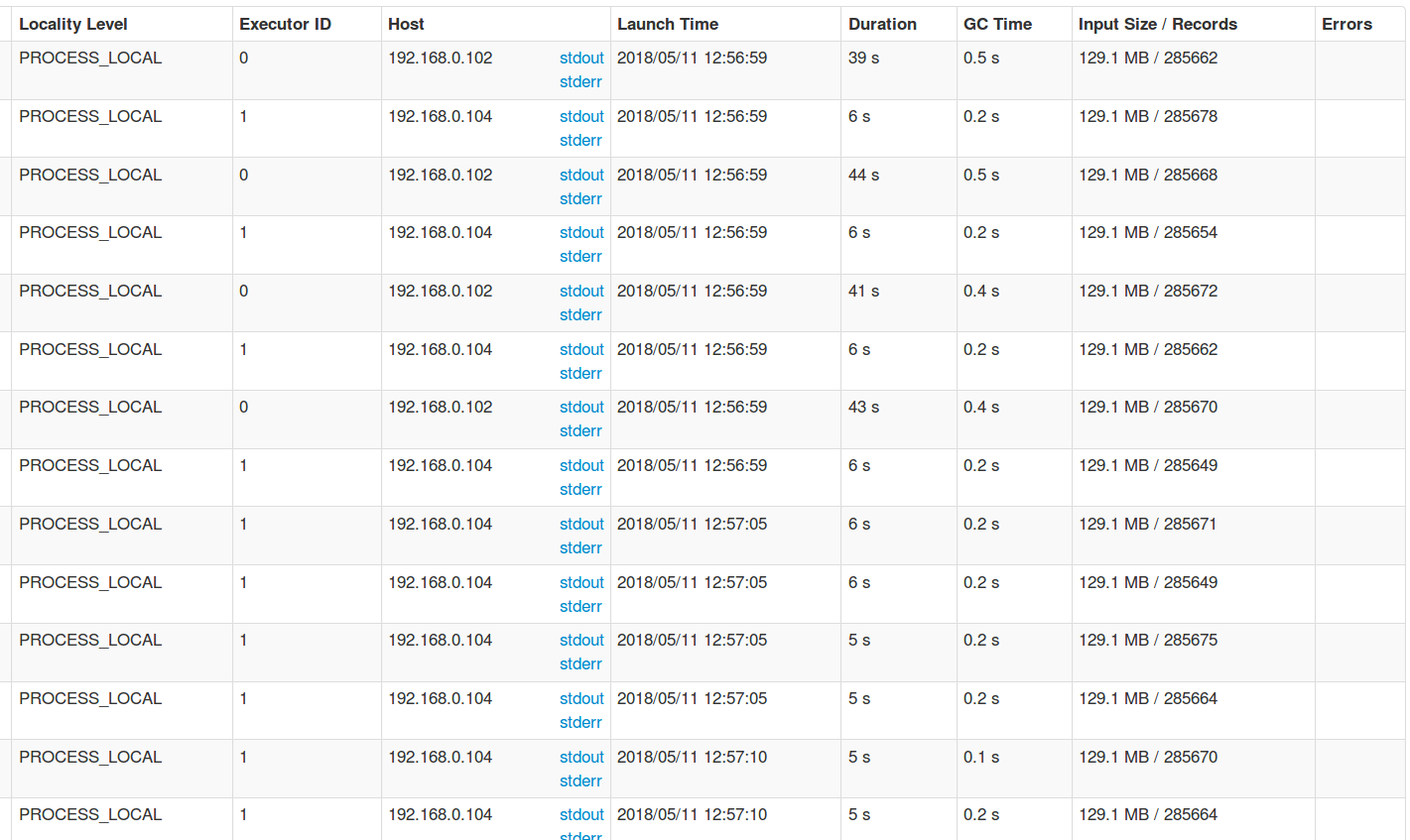
这就导致了这次的jobs,stages,tasks的分配和上次比可以说是一样,再上一张shuffle read的总览图:

下面是ganglia的测试图,我们可以看出原因:
master1:

slave5:
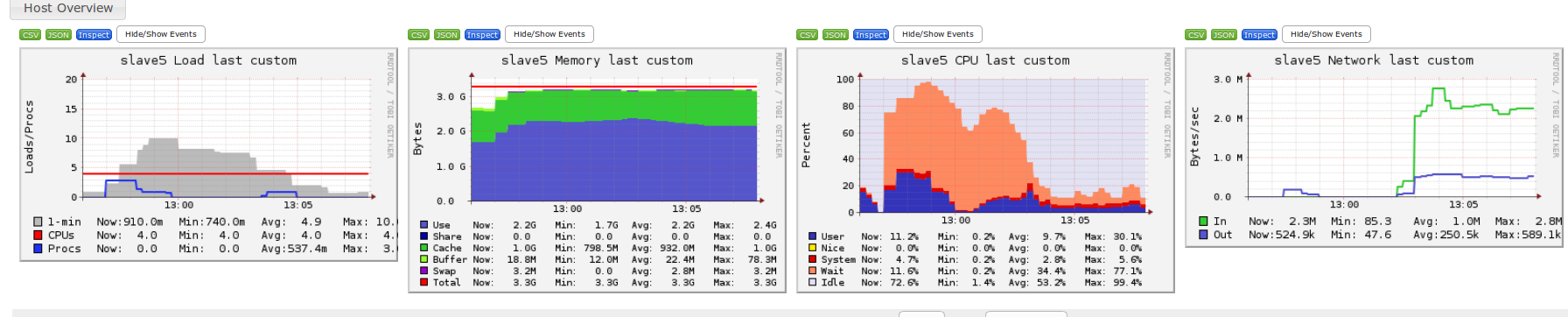
上次是因为网络io导致的slave5只读取了4个分区,这次数据在本地了,磁盘io又严重影响了性能,注意master1是固态盘,slave5是机械盘
除了这些数据,这次还记录了executor的gc日志和sink ganglia的数据,
这次我先只关注和分析master1,也就是executor1的数据:
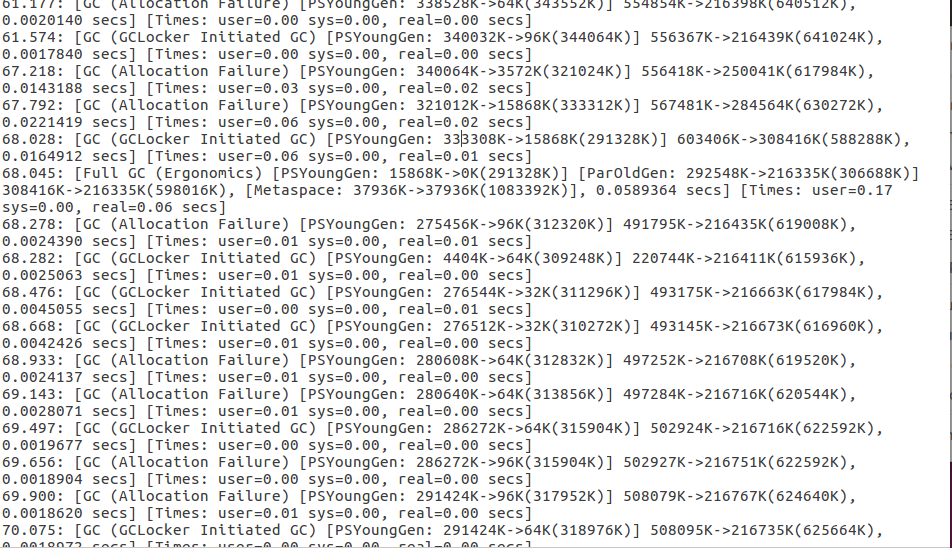
应用开始时的一段gc日志(第一个字段是应用开始运行时为时间零点的秒数):

sink ganglia有很多指标,先上几个觉得重要的:
上个jobs的图方便对应时间:

下面是ganglia的数据:时间(第1小格应用还没提交,大概为第2小格读取数据,之后5格shuffle write ,再之后shuffle read)
左bytesread.count 右byteswrite.count: 磁盘读写,第二格为什么是空的?

下一幅图:左上是 deserializedTime.count 右边显示一半的单词是spill
executor1共执行14个tasks,4个轮次,可以看出因不同轮次导致数据写到磁盘不计入spill
疑惑点:怎么决定哪些轮次的数据留在内存,哪些写到磁盘?
shuffle read导致反序列化用时快速增长
gc时间增长较均衡,水平部分是由于等待slave5完成tasks

跟堆空间和gc相关的一些指标:再上一段开始60秒后的gc日志,这时的堆内存已经扩展到650m, 新生代340m,已经达到executor可用内存的限制了,之后差不多都维持在这个水平,shuffle read阶段开始下降
57-58分钟的数据都没有,从gc日志上看这段时间堆空间使用在400m左右,怀疑是网络问题导致的,sink ganglia的数据实在太多了
疑惑点:堆内存为什么没占满?
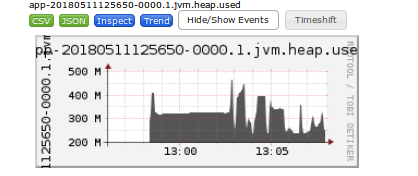
下面几张被盖住的单词是Space-Used



总结一下,这次实验的主要疑惑其实就是 executor怎么处理不同轮次之间数据的内存占用?
还有sink ganglia看了令人发晕的指标,再放几张: