
PCA的理论知识以及与K-L变换的关系
PCA是主成分分析(Principal Components Analysis)的简称。这是一种数据降维技术,用于数据预处理。一般我们获取的原始数据维度都很高,那么我们可以运用PCA算法降低特征维度。这样不仅可以去除无用的噪声,还能减少很大的计算量。
K-L转换(Karhunen-Loève Transform)是建立在统计特性基础上的一种转换,它是均方差(MSE, Mean Square Error)意义下的最佳转换,因此在资料压缩技术中占有重要的地位。K-L转换是对输入的向量x,做一个正交变换,使得输出的向量得以去除数据的相关性。

不过在图像处理上,K-L变换即是PCA变换,两者可以说是没有区别的。(待考证)
PCA的主要步骤
1、输入样本矩阵,大小:m*n。每一行为一个n维样本,共m个,如下图:
样本矩阵X=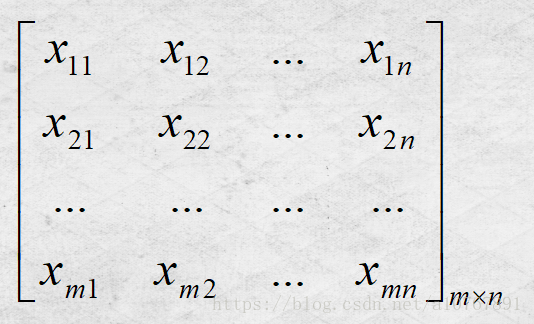
取第一行为例,它的下标含义是 行表示样本序号,列表示样本维度。

2、对样本矩阵进行中心化(取均值);

3、计算样本的协方差矩阵;
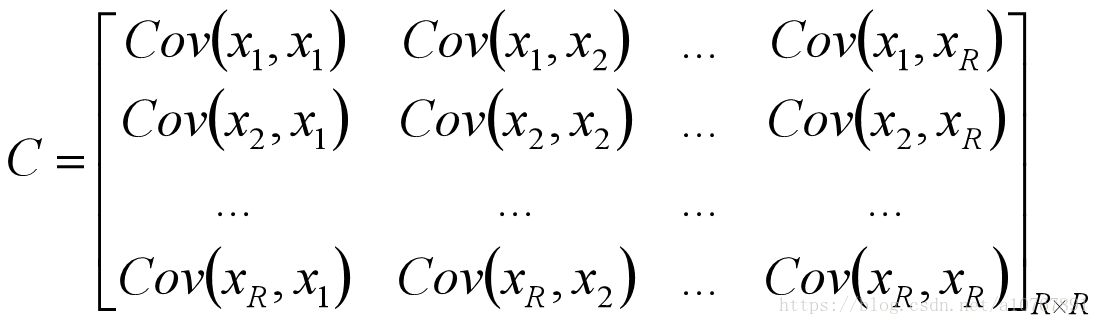
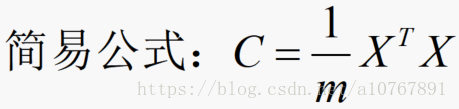
4、计算协方差矩阵的特征值并取出最大的k个特征值所对应的特征向量,构成一个新的矩阵;
若使用matlab的话直接利用函数eig即可求得,若是用python3的话,借助numpy.linalg.eig函数即可。
5、这个矩阵就是我们要求的特征矩阵(也称特征脸),里面每一列就为样本的一维主成分。把样本矩阵投影到以该矩阵为基的新空间中,便可以将n维数据降低成k维数据。
为了让大家对特征脸有个直观印象,下面将展示提取出来的特征脸结果,略恐怖,注意! (:P)
使用的是ORL人脸库中的实例:共40个人的人脸图片,每人有10张。


PCA的设计思路
从上面PCA的实现步骤可以发现,它的关键步骤便是求出样本协方差矩阵C的特征向量矩阵。可是,为什么要这么做呢?为什么这么做就可以把人脸特征提取出来呢?这是我在学习PCA算法过程中一直思考的问题,经过多方查找资料,对比分析、思考,终于有了一个初步的理解。下面就让我们来一探究竟吧。
上文中提到过,PCA变换其实就是一种降维技术。
什么是降维?降维就是指通过矩阵乘法运算后,把原来的矩阵维度减少。比如

维数减少了,虽然可以大大减少算法的计算量,但是若对基矩阵P选择不当的话就很有可能会导致信息量的缺失。
因此我们要选择哪K个基(这里还不知道是特征向量)才能保证降维后能最大程度保留原有的信息,是进行设计的主方向。
什么是信息呢?根据信息论的定义,我们可以知道信息来源于未知。也就是说如果不同样本的同一维度的值差异特别大,那该维度带给我们的信息量就是极大的。转换成数学语言,也就是说某维度的方差越大,它的信息量越大。
举个例子:假如你有3个人的人脸特征数据,他们均有3个维度:眼睛、鼻子、嘴巴。如果他们鼻子这一维度的数据都是一样的,如下图中,三个人都是大鼻子(方差=0)。那么我们从鼻子这一维度获得的信息量就是为零,因为无法从该维度得知该人脸图像到底属于谁的。

那如果他们鼻子这一维度的数据各不相同,如下图中,三个人分别是大、中、小鼻子(方差很大)。那么我们从鼻子这一维度获得的信息量就很大了,甚至直接用这一个维度就可以识别出是谁的人脸图像。

综上,我们就可以很容易联想到 第一个优化目标:降维后各维度的方差尽可能大。
既然有了第一个,当然就会有第二个啦(我说的是优化目标,别想多啦),我们的第二个优化目标便是保证不同维度之间的相关性为0(其实就是让基向量互相正交)。
因为如果某2个维度间存在相关性,就说明从一个维度的值可以推测出另一个维度的值。说明该维度中有一个是多余的,对我们识别特征帮助不大,那自然可以把其中一个维度舍去。
比如说:如果上面例子中嘴巴与鼻子这两个维度之间存在线性关系(相关性为1,完全相关):对于格式:(y)嘴巴、(x)鼻子,有y=x,x∈[大,中,小]。那么嘴巴这一维度在这里是不是就是冗余的?有它没它都一个样,完全可以通过鼻子的大小推测出嘴巴的大小,进而判断出人脸的身份。
综上所述,
PCA算法的优化目标就是: ① 降维后同一纬度的方差最大
② 不同维度之间的相关性为0
根据线性代数,我们可以知道同一元素的协方差就表示该元素的方差,不同元素之间的协方差就表示它们的相关性。因此这两个优化目标可以用协方差矩阵来表示,如下图:
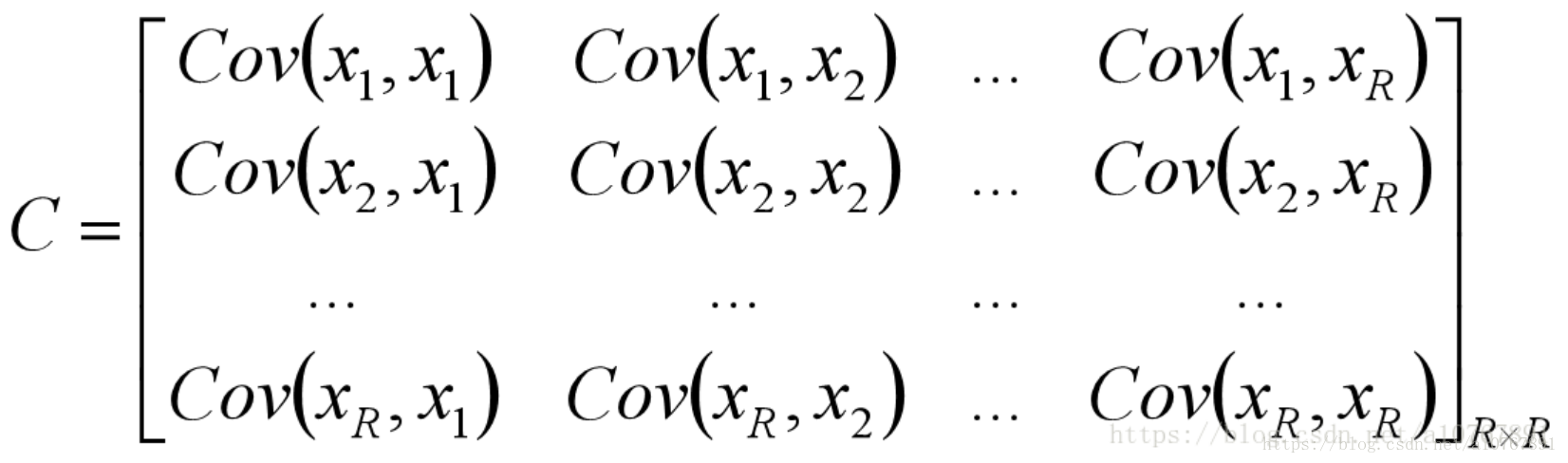

如下图,根据矩阵的迹的定义:

可以知道优化目标一便是令Cy矩阵的对角线元素之和最大。即max tr(Cy)
-------------------------------------------------------------------------------------------------------------
知道了目标,接下来就好办,我们要做的就是想尽一切办法去达到我们的优化目标。
下面便是推导过程:

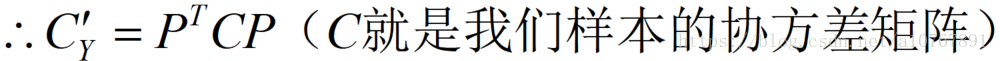

PS:拉格朗日乘子法定义如下
|


根据:

可以看到,最终求得的结果满足特征向量的关系式,因此由样本矩阵特征向量基矩阵,就是我们要求的变换矩阵。
由该矩阵降维得到的新样本矩阵可以最大程度保留原样本的信息。
至此,问题都已经解决了:信息量保存能力最大的基向量一定是样本矩阵X的协方差矩阵的特征向量,并且这个特征向量保存的信息量就是它对应的特征值的绝对值。这个推导过程就解释了为什么PCA算法要利用样本协方差的特征向量矩阵来降维。
我觉得这正是理解PCA算法的关键点,只要理解了这一点,对PCA算法也就基本掌握了,之后要自己编程实现PCA
人脸识别系统,也就只是按部就班的事了。
这是我用python3.6写的参考代码(基于PCA的人脸识别系统):https://github.com/LJRice/KL-PAC-_face
大家有兴趣的话可以研究一下,若是文章、代码中有哪里不对还请私信我,谢谢观看:D
(PS:该文章只是讲解了PCA的工作原理,不涉及它的具体实现方法。等以后有时间,还会对代码进行详细介绍的。)





