
娱乐圈的瓜真的是一波又一波,这次又轮到文章和马伊琍了。他们具体为啥会婚变,咱也不知道,啥也不敢问,啥也不干说。不过他们微博下面还是开锅了,下面就一起来看看吧。
微博页面分析
首先我们先来看看微博页面,爬虫要从何处下手。
页面分析
我们直接进入到马伊琍微博的评论页面
可以看到页面如下:
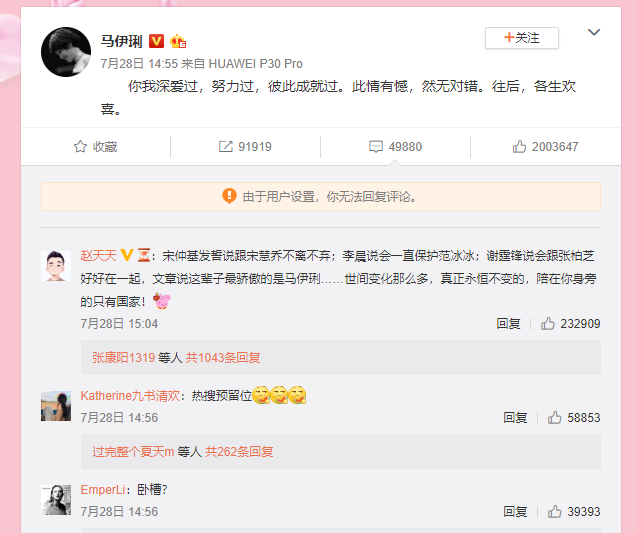
然后我们使用 Chrome 的调试工具(F12),切换到 Network 页签,再次刷新页面,能够看到一条请求,如下:
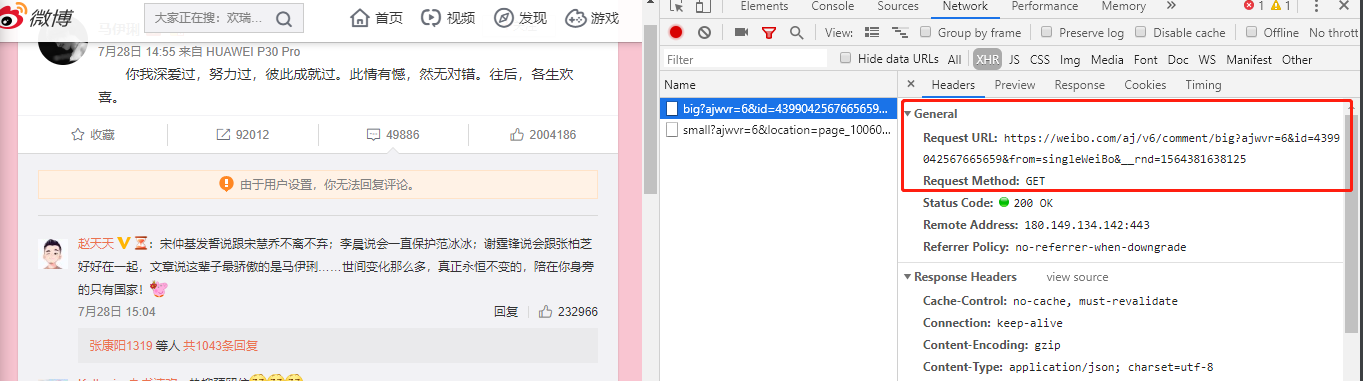
先拷贝出这个请求 URL,放到 Postman 里试一试,如图:
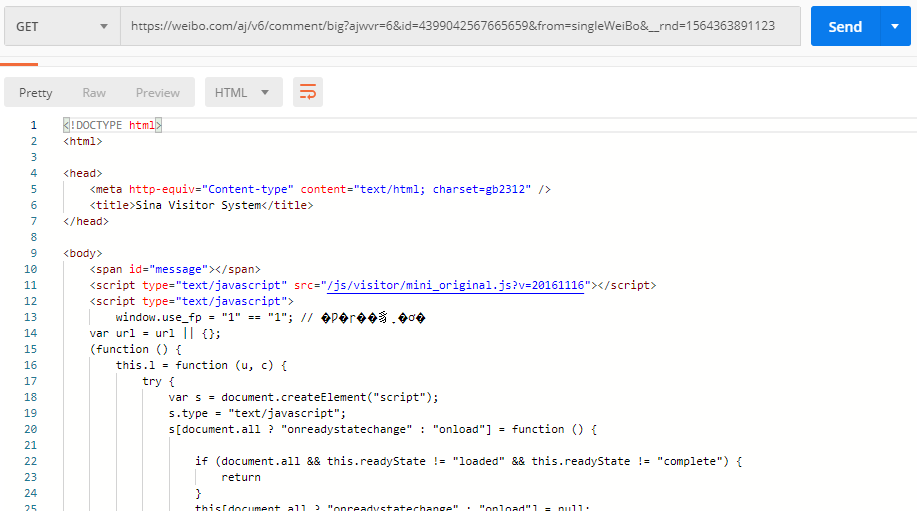
这都是些神马啊

果然没那么简单,看来有反爬在作怪,那么反反爬三板斧先用起来,headers 加一哈
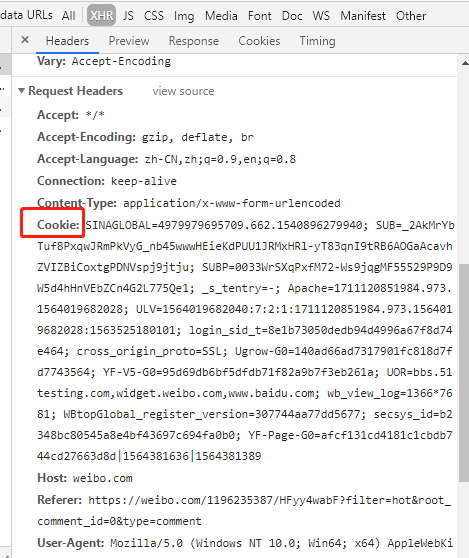
再来继续继续观察 Network 中的请求 headers,发现有一个 Cookie 是那么的长,拷贝出来添加上试试吧
再次使用 Postman 调用
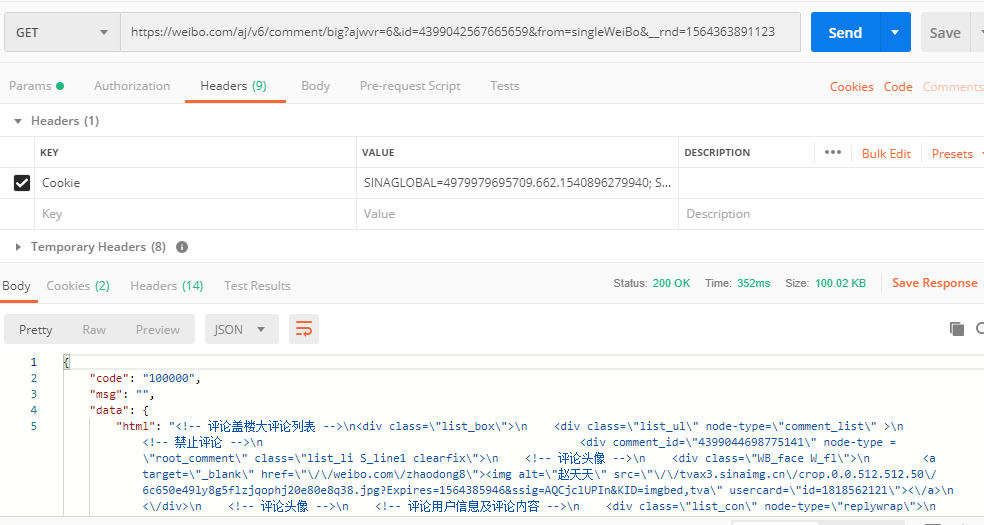
哎呦,不错哦,有正常数据返回了

URL 分析
现在再来看看我们使用的 URL
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4399042567665659&from=singleWeiBo&__rnd=1564381638125
总共有4各参数,ajwvr、id、from 和 __rnd。
1.精简 URL
我们先从后往前一个一个的去掉每个参数试试,发现去掉后面两个,我们都可以获取到评论记录,那么后面两个参数我们就去掉它,现在的 URL 变为:
2.增加 page 参数
再次观察现在获取到的数据,发现返回的数据还有一个 page 的数据域,如下:
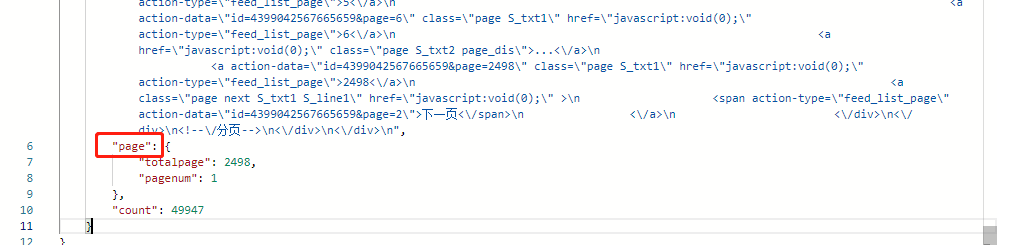
而且当前是在 “pagenum”: 1 的,那么我们要怎么控制到不同的 page 页面呢,试着增加一个 page 参数到 URL 中,如:
果然,真的访问到 page 2 了,是不是很香啊
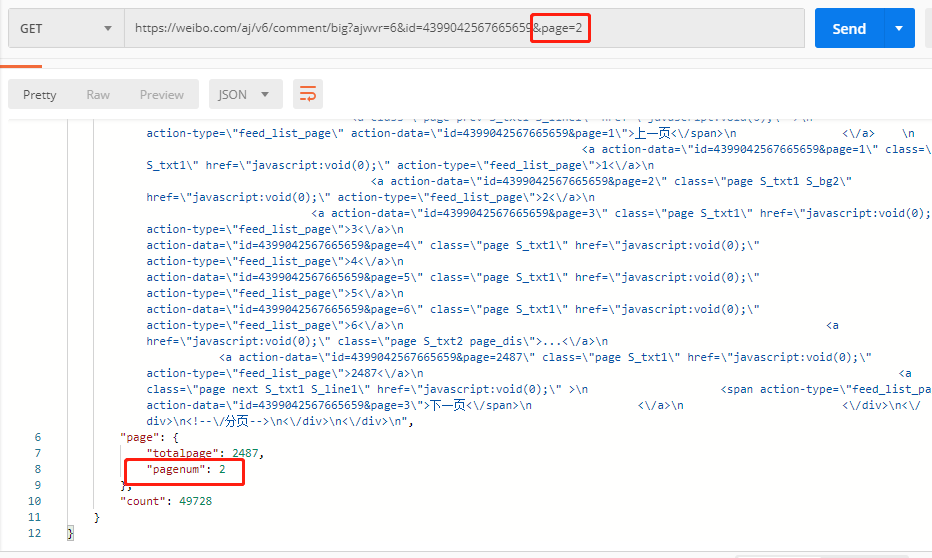
真香
至此,我们的页面分析就基本完成了,下面就是拿数据喽。
获取并保存数据
获取保存数据的部分就比较常规了,直接看代码
import requests
import json
from bs4 import BeautifulSoup
import pandas as pd
import time
Headers = {'Cookie': 'SINAGLOBAL=4979979695709.662.1540896279940; SUB=_2AkMrYbTuf8PxqwJRmPkVyG_nb45wwwHEieKdPUU1JRMxHRl-yT83qnI9tRB6AOGaAcavhZVIZBiCoxtgPDNVspj9jtju; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5d4hHnVEbZCn4G2L775Qe1; _s_tentry=-; Apache=1711120851984.973.1564019682028; ULV=1564019682040:7:2:1:1711120851984.973.1564019682028:1563525180101; login_sid_t=8e1b73050dedb94d4996a67f8d74e464; cross_origin_proto=SSL; Ugrow-G0=140ad66ad7317901fc818d7fd7743564; YF-V5-G0=95d69db6bf5dfdb71f82a9b7f3eb261a; WBStorage=edfd723f2928ec64|undefined; UOR=bbs.51testing.com,widget.weibo.com,www.baidu.com; wb_view_log=1366*7681; WBtopGlobal_register_version=307744aa77dd5677; YF-Page-G0=580fe01acc9791e17cca20c5fa377d00|1564363890|1564363890'}
def mayili(page):
mayili = []
for i in range(0, page):
print("page: ", i)
url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4399042567665659&page=%s' % int(i)
req = requests.get(url, headers=Headers).text
html = json.loads(req)['data']['html']
content = BeautifulSoup(html, "html.parser")
# comment = content.find_all('div', attrs={'class': 'list_li S_line1 clearfix'})
comment_text = content.find_all('div', attrs={'class': 'WB_text'})
for c in comment_text:
mayili_text = c.text.split(":")[1]
mayili.append(mayili_text)
time.sleep(5)
return mayili
def wenzhang(page):
wenzhang = []
for i in range(0, page):
print("page: ", i)
url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4399042089738682&page=%s' % int(i)
req = requests.get(url, headers=Headers).text
html = json.loads(req)['data']['html']
content = BeautifulSoup(html, "html.parser")
# comment = content.find_all('div', attrs={'class': 'list_li S_line1 clearfix'})
comment_text = content.find_all('div', attrs={'class': 'WB_text'})
for c in comment_text:
wenzhang_text = c.text.split(":")[1]
wenzhang.append(wenzhang_text)
time.sleep(5)
return wenzhang
if __name__ == '__main__':
print("start")
ma_comment = mayili(1001)
mayili_pd = pd.DataFrame(columns=['mayili_comment'], data=ma_comment)
mayili_pd.to_csv('mayili.csv', encoding='utf-8')
wen_comment = wenzhang(1001)
wenzhang_pd = pd.DataFrame(columns=['wenzhang_comment'], data=wen_comment)
wenzhang_pd.to_csv('wenzhang.csv', encoding='utf-8')
总共 page 页面有 2000 多页,要爬完还真是需要一段时间,我这里配置了 1000,应该是够了。
而且还做了 sleep 5 的操作,主要是因为如果爬取太快,会被微博视为异常请求,会被禁,而且也不会对人家的正常服务产生影响,毕竟盗亦有道嘛!

词云做成
等爬虫跑完之后,我们简单看下数据的内容
马伊琍微博评论
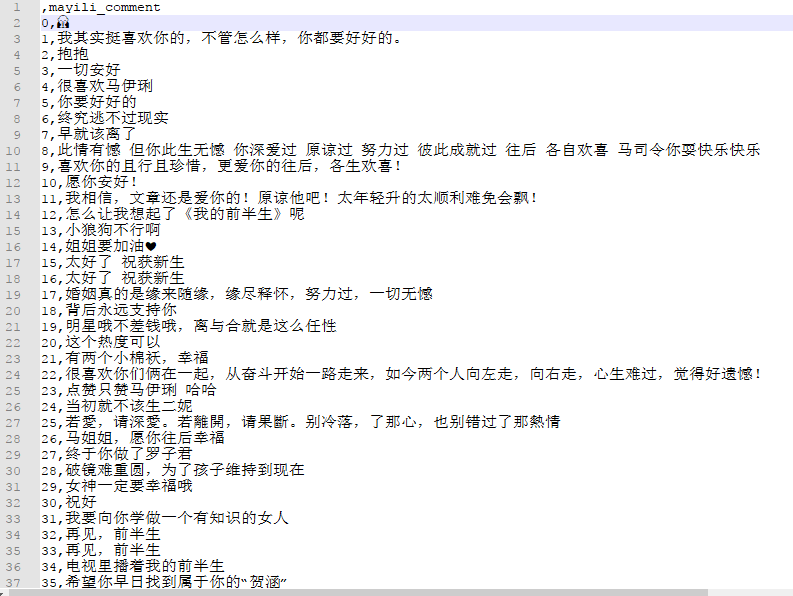
文章微博评论
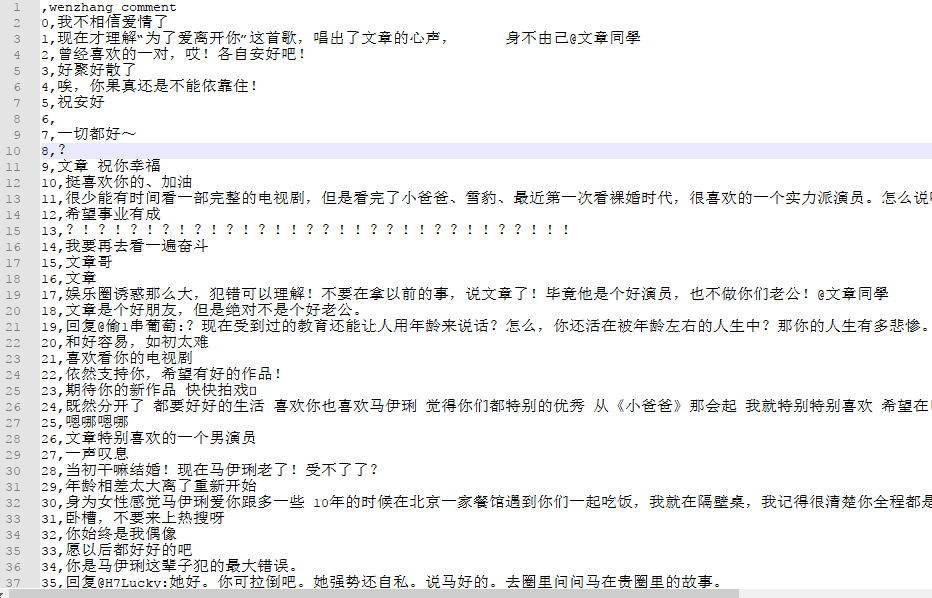
数据都拿到了,下面就做成词云看看各路粉丝的态度吧
这里就不对评论内容做过多置喙了,毕竟说多了都是错

def wordcloud_m():
df = pd.read_csv('mayili.csv', usecols=[1])
df_copy = df.copy()
df_copy['mayili_comment'] = df_copy['mayili_comment'].apply(lambda x: str(x).split()) # 去掉空格
df_list = df_copy.values.tolist()
comment = jieba.cut(str(df_list), cut_all=False)
words = ' '.join(comment)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue')
wc.generate(words)
wc.to_file('m.png')
马伊琍评论词云

文章评论词云

最后,我把所有的代码都上传到 GitHub 上了,需要的可以自取
https://github.com/zhouwei713/data_analysis/tree/master/weibo_mayili_wenzhang




