

相信很多人对于 Hadoop 领域近期发生的事件都有所耳闻,先是曾估值 10 亿美元的 MapR 向加州就业发展局提交文件,称如果找不到新的投资人,公司将裁员 122 人,并关闭位于硅谷的总部公司,再是 Cloudera 在 6 月 6 日美股开盘之后,股价暴跌 43%,公司估值从 41 亿美元缩水为 14 亿美元。
从 2006 年 1 月诞生以来,Hadoop 就以黑马之姿一路开挂成为了火爆整个技术圈的“明星”技术,为什么现在 Hadoop 领头羊商业公司突然都不同程度的遭遇到了挫折?这是否意味着 Hadoop 发行版已经几近无路可走?Hadoop 商业公司的颓势是否能够反映 Hadoop 技术、生态的发展情况?Hadoop 的竞争对手到底是谁?…为了回答上述问题,我们和星环科技研发总监刘汪根进行了长达一小时的对话。
Hadoop 是 ASF 旗下的分布式系统基础架构,我们现在看到的 Hadoop 生态有很多组件,但在刘汪根看来,大部分组件产品化程度不够,真正有技术生命力的组件只有两个 HDFS 和 Zookeeper。并且,这种技术生命力是长久的,至少在如今的科技类企业和互联网公司中,HDFS 和 Zookeeper 等已经成为了标配。
1开源 Hadoop 产品化程度不足是 Cloudera、MapR 商业模式存在的主要问题
Hadoop 是个开源软件,那么围绕 Hadoop 的商业公司都是如何盈利的呢?Cloudera 主要是依靠发布 Hadoop 商业版和商用工具、商业组件,同时提供企业生产环境中必需的运维功能;Hortonworks 采用 100% 完全开源的策略,盈利方式是技术服务支持;MapR 的盈利主要是通过用户购买软件许可。
虽然三家公司实现盈利的方式有所出入,但是本质上都是靠提供 Hadoop 相关的服务来盈利。而服务模式本身就存在很多问题,一是它需要依赖人员的扩张,二是其价值一定要高,能够刺激企业不断基于 Hadoop 产品开发新的应用。
服务带动产品的销售模式必然要面临成本和投入产出的问题,刘汪根认为:“这三家公司存在的最大问题不是单子不够多,而是单子太多,但每个单子都不挣钱,拖累整个业绩不好。”具体来讲,就是它们产品的标准化不足,其提供了各种组件的底层 API 给开发者,缺少一个统一的开发标准,导致很难形成标准的开发体验。社区的状态很松散,想要达成某个标准化的事情往往需要很长的时间,以大数据产品的安全为例,这在标准化产品中应该是标配,而在社区中可能花费一个月的时间都搞不起来,这就导致了这个产品是不可持续的,对于用户来说,持续产品的价值太少,导致用户不愿意继续追加投资。
产品化程度低又会连锁反应导致销售成本的增高,因为缺少成功的项目和持续的收入来源,所以企业只能加大销售力度,招聘非常多的销售和售前工程师,在有些公司中这些人员甚至会超过总员工数的一半。
产品化程度低不只是 Hadoop 商业公司面临的问题,也是所有基于开源软件的商业公司面临的问题。不过也有一些开源软件的商业公司在产品化方面做得不错,例如 Spark 商业公司 Databricks 的销售人员占比没那么高。这是因为 Databricks 商业化的思路不同,第一是它做了云化,第二是它很简单,并且做了两个件事情让 Spark 变得更加简单,一是 SparkSQL,这使得所有会写 SQL 的人都可以使用,二是通过 DataFrame 接口和 Python 让数据分析人员可以更好的编程。
如果你准备入坑大数据开发,可以关注ID:IT资讯科技 会有最前沿的学习资讯。
“成功的商业模式一定是可复制的!”
2Hadoop 发行版是否还有前景?
众所周知,Cloudera、Hortonworks 和 MapR 这三家公司都是 Hadoop 发行版公司,但是大家可能不知道星环科技最早在国内也是做 Hadoop 发行版,当时的技术架构组成为 HDFS+HBase+YARN+Spark,主要的客户群体是运营商,但是在做的过程中就发现项目同质化太严重了,客户项目开发的成本比较高,因此竞争非常激烈。
2014 年,星环不得不开始思考一个现实的问题:“如何才能活下去?”创始人孙元浩先生最终下定决心,星环科技的产品必须要解决企业的痛点问题才能更好的成长。当时数据仓库是个痛点问题,但原来的数据库都是单机的,所以星环科技就开始琢磨利用分布式、内存计算等技术打造一个分布式数据库来解决数据仓库的问题。这个数据库就是后来我们熟知的国际上首个通过了 TPC-DS 基准测试的 Inceptor 数据库。
后来,刘汪根在演讲中回忆这段经历时,也感叹到:“如果星环科技只是将技术打包,推出 Hadoop 发行版,就失去了创新性和独特性。”
Cloudera、Hortonworks 和 MapR 面临窘境,星环科技从 Hadoop 发行版公司转型成为了大数据与人工智能基础软件的公司,这是否意味着 Hadoop 发行版已经失去了价值,没有发展前景了?
对此,刘汪根表示:“这个问题现在还很难讲,但是我目前看到的情况,数据在公有云中的渗透率远没有大家想象的那么高,所有人都觉得私有化环境或私有云里面的数据更安全,所以都愿意把数据掌握在自己的服务器上。对象存储之所以在公有云中获得了比较好的发展有两个原因,一是因为其中大部分数据都是冷数据或者非结构化数据,真正重要的、结构化的数据还是存储在私有云中。这种情况在中国比例极高,在美国也不会低。第二个原因是成本,HDFS 和对象存储各有特点,对象存储天生是 1.4 倍副本,而 HDFS 是 3 倍副本,光是这一项就有至少 2 倍的成本差异,所以公有云上对象存储相对于 HDFS 有很好的竞争力。但是私有云不一样,私有云的场景下更加业务价值导向,追求速度和性能,想向私有云渗透的云产品往往都会需要补充技术实力,所以 Hadoop 技术对于私有云来说还是非常有必要的,也是非常有用的。”
3Hadoop 商业公司走了“下坡路”,那社区呢?
毫无疑问,Hadoop 三大商业公司与之前相比,已经走了“下坡路”,那么 Hadoop 技术、Hadoop 社区的发展如何呢?刘汪根坦言:“原来 Hadoop 社区的大佬很多都转向其他项目了,整个社区的创新速度减缓了,对于大数据用户来说,可能 Hadoop 社区的创新速度已经无法满足需求了。”
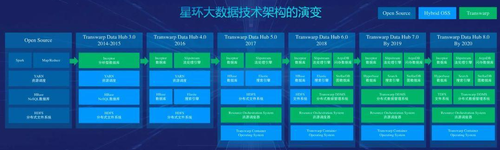
上图是星环科技大数据技术架构的演变历程,其完成了从 Hadoop 平台初期的“纯蓝”软件栈到现在基本“全绿”软件栈的转变,即完成了自研产品和软件对开源软件的替代。为什么要做这种转变呢?首先,是因为 HDFS 和 YARN 等核心组件在实际应用中存在痛点,例如 HDFS 天生在海量小文件存储方面就存在缺陷,YARN 只能用来调用长生命周期的任务(如批处理任务)。二是因为 Hadoop 社区的创新能力有点后劲不足,所以星环科技基于自己的思路进行了重新设计。以 HDFS 为例,星环科技正在实现自己的存储系统 TDFS,在原有的分布式管理系统基础上做了一套通用的 HDFS。
在刘汪根看来这一系列改造、替换的操作都是因为需求,“HDFS 在设计之初主要解决了两个问题,一是相对廉价的分布式解决了存储可扩展性的问题,二是分析性能比较均衡,支持用户在此基础上做很多创新来解决性能问题。这两件事情保证了 HDFS 技术能够维持其生命力,”
从图中我们可以看到,在整个星环科技技术架构的演化过程中,其对 Hadoop 核心组件 HDFS、YARN 等都做了一定程度的技术改造,在我们询问是否有将这些改变贡献给 Hadoop 社区时,刘汪根无奈表示:“早期我们也尝试过贡献给社区,但由于当时星环科技的精力有限,并没有完成。后续会根据公司自身的情况来决定。”
4Hadoop 不代表全部的大数据技术,那下一代大数据技术该如何发展?
其实,媒体很早就在接受这样一个观念,那就是“Hadoop 不代表大数据”。时至今日,Hadoop 在大数据领域到底扮演着什么样的角色呢?刘汪根认为:“Hadoop 不代表大数据, 它是大数据技术实现的一个分支,且这个分支中有部分技术变成了通用的技术,成为大数据技术的标配。但是,大数据技术还有很多其它分支,它们最终会演化成为新的大数据实现方式。”
早在 2013 年,Gartner 研究总监 Svetlana Sicular 就曾发文称 Hadoop 过时了,在《2017 年数据管理技术成熟度曲线》报告中,Gartner 更是用极其显眼的红色标识出 Hadoop 在到达“生产成熟期”之前即被淘汰。当然,其它唱衰 Hadoop 的声音也不在少数,但是刘汪根认为 Hadoop 技术是有长久生命力的,很多技术已经成为了大数据领域教科书般的存在,例如 2003 年 Google 连续发表的三篇论文奠定了大数据的框架基础,并基于此理论形成了 Hadoop 原始的“3+1”式软件栈:即分布式文件系统 HDFS、分布式计算 MapReduce、Hbase NoSQL 数据库,以及 YARN 资源调度。
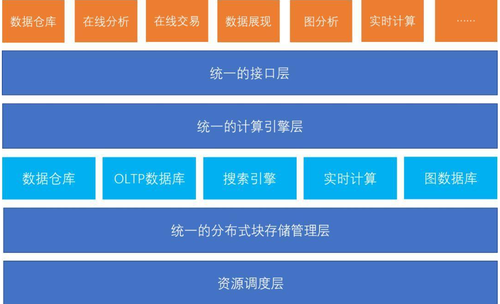
当 Hadoop 不能再成为大数据的代名词,下一代大数据技术将如何发展呢?通常来讲,大数据技术栈总共包含有四层,分别是资源调度层、统一的分布式块存储管理层、统一的计算引擎层和统一的接口层,所以下一代的大数据技术一定是基于这四层进行改造,以适应新的应用场景和需求。
资源调度层的改造:为了解决上层应用对资源调度管理的问题,出现了很多新的技术,例如很多企业开始研究利用容器编排技术来代替 YARN 进行资源管理;
统一的分布式块存储管理层:过去的观点认为 HDFS 具有较好的通用性并在此之上搭载了各种引擎,实践证明 HDFS 无法实现高效的数据库,新一代的大数据体系需要一个统一的分布式块存储管理层,以支持不同的数据库类型。
统一的计算引擎层:过去常见的观点是数据量小的时候可以采用混合架构,数据量大的时候采用 Hadoop,但是这种选择存在效率低下的问题,所以我们需要一个统一的计算引擎层来应对数据仓库、OLTP 数据库、搜索引擎、实时计算、图数据库等多种需求。
统一的接口层:多年前,通过统一的 SQL 接口层来降低大数据技术的使用门槛,就已经达成了共识。如今,SQL 的支持度在不断提升。
5谈谈 Hadoop 的两大“竞争对手”
有关最近 Hadoop 事件的解读,国内外媒体都已经做了不少的报道(我们也基于此做了一个合集,感兴趣的小伙伴可以点击查看)。如果总结一下大家的观点,不难发现大家普遍认为 Hadoop 的“竞争对手”主要有两个,一是 MongoDB、Elasticsearch 等其它开源大数据相关产品,二是公有云。下面,我们就分别来谈谈这两个“Hadoop”的竞争对手。
MongoDB、Elasticsearch 等蚕食了 HDFS 的市场
之所以得出了 MongoDB 、 Elasticsearch 等技术挑战了 Hadoop 技术及相关产品的结论,是因为外媒观察到这样一个情况:在 Hadoop 三大商业公司遭遇挫折的时候,MongoDB 数据库产品受欢迎程度一直在增长,现在的受欢迎指数大约是 Oracle 和 MySQL 的三分之一,而五年前只有十分之一。这种受欢迎程度反过来良性地推动 MongoDB 公司的收入增长,最近收入已经跃升了 78%。同样的,Elasticsearch 分布式搜索和分析引擎背后的公司 Elastic 在去年员工数量翻了一番,最近一个季度的收入增长了 70%。许多公司已经转用 Elastic 的产品进行传统的文本搜索和其他更多的搜索,比如英国伦敦的 Stansted 机场就使用 Elastic 工具来追踪和可视化机场内的人员和行李流量,并提供实时分析。
Hadoop 与 MongoDB、Elasticsearch 是否存在外媒描述的此消彼长的情况呢?刘汪根表示这种情况是存在的,但是比例不会很高。大数据应该包括分析数据库、交易数据库以及 NoSQL 四大类数据,刚刚提到的 MongoDB 属于文档数据库,Elasticsearch 属于检索数据库,而 HBase 属于列存数据库,它们是按照业务场景划分的,本来是平行的,但是每个东西之间都有一定的边界,HBase 和 Elasticsearch 之间场景非常明确,但是 HBase 和 MongoDB 是有一定冲突的,HBase 并发度高,但是很多人也用它来处理 JSON 的数据,而 MongoDB 也在处理非结构化的 JSON 数据。HBase 的优势在于存储,而 MongoDB 的优势在于可以修改 JSON 中的字段。但是重合的点真的非常少,仅限于处理 JSON 数据。
但是 HDFS 就比较尴尬了,HDFS 强调通用性,没有比较突出的优势,所有方向都是均衡的,所以市场份额很容易被其它大数据产品蚕食。例如,企业历史数据既可以存在 MongoDB 中,也可以存在 HDFS 中。虽然,HDFS 的存储成本会比较低,但如果企业一直是使用 MongoDB,且不太在乎成本差异,那么就会一直使用 MongoDB。不仅限于 MongoDB 和 Elasticsearch,如果企业有比较明确的数据处理需求,其它数据库也会切掉 HDFS 的市场份额。当然,如果出现了一个统一的分布式块存储管理层能够解决各种类型的存储需求管理,那么它将覆盖 HDFS 原有的市场,以及 MongoDB 和 Elasticsearch 的市场。
MongoDB 和 Elasticsearch 是否挑战了 Hadoop 的地位?这个结论现在还不好确定,但是从营收状况来看,MongoDB 和 Elastic 两家公司的营收之和仅相当于合并之前的 Cloudera 单家公司营收,这说明 MongoDB 和 Elasticsearch 还只是大数据生态里的一小部分。
公有云与 Hadoop 不是天生对手
为什么很多人都把公有云看作是 Hadoop 的竞争对手?Hadoop 的主要应用场景是廉价的存储,而有了云之后,存储变得更加廉价,AWS、微软 Azure 和谷歌云打造的一站式云原生服务提供了完全集成的产品系列,获取成本更低,扩容更便宜。
但其实 Hadoop 与公有云并不是天生对手,只是大家使用 Hadoop 的方式基本只有三种,要么找这三大商业公司,要么自己搭建,要么找公有云厂商。如果这已经是饱和市场,那么大家都是在切同一块蛋糕,公有云难免会切到 Hadoop 商业公司原有的部分。不过,从目前的情况来看,类似于 AWS 这样的公司,其 Hadoop 的收入占比是非常小的。
在刘汪根看来,相比于竞争关系,公有云厂商和 Hadoop 商业公司更多的是合作关系。以 AWS 为例,其 Hadoop 研发团队的规模非常小,当出现搞不定的问题时,就必须要去找 Hadoop 商业公司来解决。AWS 相当于是个大渠道,拥有更强的溢价能力,但渠道的溢价能力再强,最终还是需要背后公司的支持。而这对于 Hadoop 商业公司来说,不是坏事,反而是好事,因为公有云上的模式是可复制的,可以帮助 Hadoop 商业公司触探到更多用户,Databricks 就是一个很好的例子。
6写在最后
关于 Hadoop 及其商业公司最近的发展颓势,我们已经进行了多方面、深层次的探索。总体来看,公有云、其它大数据产品与 Hadoop 竞争的外因固然存在,但是 Hadoop 自身存在的问题、社区创新能力不足以及其商业公司的盈利模式才是更主要的原因。
Hadoop 的技术偏底层,使用场景需要比较专业的技术基础,因此虽然是很好的技术,但只能定位给有比较强技术能力的企业来使用,缺乏我们常说的应用创新或者模式创新。如果将其更好的产品化,譬如通过 SQL on Hadoop 的技术打造完整的数据库的体验,那么其开发者群体和视野将大大拓宽,技术的盘子就可以做得更大一点,现阶段的对手都会变盟友。
推荐阅读:大数据学习线路:https://www.imooc.com/article/259721
大数据hadoop的13个开源工具:https://www.imooc.com/article/264971





