

现在一聊到容器技术,大家就默认是指 Docker 了。但事实上,在 Docker 出现之前,PaaS社区早就有容器技术了,以 Cloud Foundry、OpenShift 为代表的就是当时的主流。
那为啥最终还是 Docker 火起来了呢?
因为传统的PaaS技术虽然也可以一键将本地应用部署到云上,并且也是采用隔离环境(容器)的形式去部署,但是其兼容性非常的不好。因为其主要原理就是将本地应用程序和启停脚本一同打包,然后上传到云服务器上,然后再在云服务器里通过脚本启动这个应用程序。
这样的做法,看起来很理想。但是在实际情况下,由于本地与云端的环境差异,导致上传到云端的应用经常各种报错、运行不起来,需要各种修改配置和参数来做兼容。甚至在项目迭代过程中不同的版本代码都需要重新去做适配,非常耗费精力。
然而 Docker 却通过一个小创新完美的解决了这个问题。在 Docker 的方案中,它不仅打包了本地应用程序,而且还将本地环境(操作系统的一部分)也打包了,组成一个叫做「 Docker镜像 」的文件包。所以这个「 Docker镜像 」就包含了应用运行所需的全部依赖,我们可以直接基于这个「 Docker镜像 」在本地进行开发与测试,完成之后,再直接将这个「 Docker镜像 」一键上传到云端运行即可。
Docker 实现了本地与云端的环境完全一致,做到了真正的一次开发随处运行。
一、容器到底是什么?
容器到底是什么呢?也许对于容器不太了解,但我们对虚拟机熟悉啊,那么我们就先来看一下容器与虚拟机的对比区别:
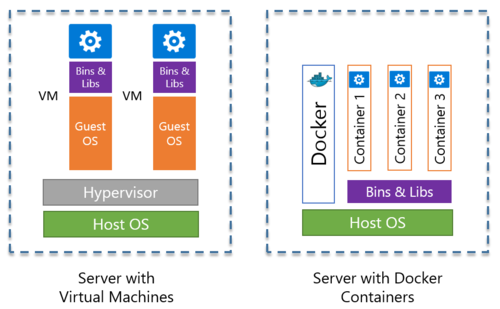
上图的左侧是虚拟机的原理,右侧是Docker容器的原理。
虚拟机是在宿主机上基于 Hypervisor 软件虚拟出一套操作系统所需的硬件设备,再在这些虚拟硬件上安装操作系统 Guest OS,然后不同的应用程序就可以运行在不同的 Guest OS 上,应用之间也就相互独立、资源隔离了,但是由于需要 Hypervisor 来创建虚拟机,且每个虚拟机里需要完整的运行一套操作系统 Guest OS,因此这个方式会带来很多额外资源的开销。
而 Docker容器 中却没有 Hypervisor 这一层,虽然它需要在宿主机中运行 Docker Engine,但它的原理却完全不同于 Hypervisor,它并没有虚拟出硬件设备,更没有独立部署全套的操作系统 Guest OS。
Docker容器没有那么复杂的实现原理,它其实就是一个普通进程而已,只不过它是一种经过特殊处理过的普通进程。
我们启动容器的时候(docker run …),Docker Engine 只不过是启动了一个进程,这个进程就运行着我们容器里的应用。但 Docker Engine 对这个进程做了一些特殊处理,通过这些特殊处理之后,这个进程所看到的外部环境就不再是宿主机的那个环境了(它看不到宿主机中的其它进程了,以为自己是当前操作系统唯一一个进程),并且 Docker Engine 还对这个进程所使用得资源进行了限制,防止它对宿主机资源的无限使用。
那 Docker Engine 具体是做了哪些特殊处理才有这么神奇的效果呢?
二、容器是如何做到资源隔离和限制的?
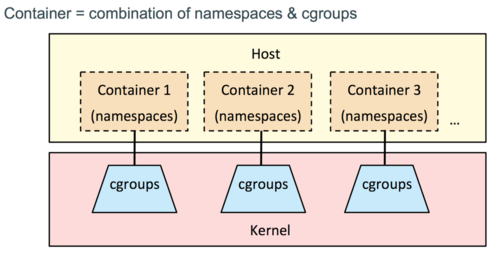
Docker容器对这个进程的隔离主要采用2个技术点:
Namespace 技术
Cgroups 技术
弄清楚了这两个技术点对理解容器的原理非常重要,它们是容器技术的核心。
下面来详细解释一下:
Namespace 技术
Namespace 并不是一个什么新技术,它是Linux操作系统默认提供的API,包括 PID Namespace、Mount Namespace、IPC Namespace、Network Namespace等等。
以 PID Namespace 举例,它的功能是可以让我们在创建进程的时候,告诉Linux系统,我们要创建的进程需要一个新的独立的进程空间,并且这个进程在这个新的进程空间里的PID=1,也就是说这个进程只看得到这个新进程空间里的东西,看不到外面宿主机环境里的东西,也看不到其它进程(不过这只是一个虚拟空间,事实上这个进程在宿主机里PID该是啥还是啥,没有变化,只不过在这个进程空间里,该进程以为自己的PID=1)。
打个比方,就像是一个班级,每个人在这个班里都有一个编号,班里有90人,然后来了一位新同学,那他在班里的编号就是91,可是老师为了给这位同学特别照顾,所以在班里开辟了一块独立的看不到外面的小隔间,并告诉这个同学他的编号是1,由于这位同学在这个小空间里隔离着,所以他真的以为自己就是班上的第一位同学且编号为1,当然了,事实上这位同学在班上的编号依然是91。
另外,Network Namespace 的技术原理也是类似的,让这个进程只能看到当前Namespace空间里的网络设备,看不到宿主机真实情况。同理,其它 Mount、IPC等 Namespace 也是这样。
Namespace 技术其实就是修改了应用进程的视觉范围,但应用进程的本质却没有变化。
不过,Docker容器里虽然带有一部分操作系统(文件系统相关),但它并没有内核,因此多个容器之间是共用宿主机的操作系统内核的。这一点与虚拟机的原理是完全不一样的。
Cgroups 技术
Cgroup 全称是 Control Group,其功能就是限制进程组所使用的最大资源(这些资源可以是 CPU、内存、磁盘等等)。
既然 Namespace 技术 只能改变一下进程组的视觉范围,并不能真实的对资源做出限制。那么为了防止容器(进程)之间互相抢资源,甚至某个容器把宿主机资源全部用完导致其它容器也宕掉的情况发生。因此,必须采用 Cgroup 技术对容器的资源进行限制。
Cgroup 技术也是Linux默认提供的功能,在Linux系统的 /sys/fs/cgroup 下面有一些子目录 cpu、memory等,Cgroup技术提供的功能就是可以基于这些目录实现对这些资源进行限制。
例如:在 /sys/fs/cgroup/cpu 下面创建一个 dockerContainer 子目录,系统就会自动在这个新建的目录下面生成一些配置文件,这些配置文件就是用来控制资源使用量的。例如可以在这些配置文件里面设置某个进程ID对CPU的最大使用率。
Cgroup 对其它内存、磁盘等资源也是采用同样原理做限制。
三、容器的镜像是什么?
一个基础的容器镜像其实就是一个 rootfs,它包含操作系统的文件系统(文件和目录),但并不包含操作系统的内核。
rootfs 是在容器里根目录上挂载的一个全新的文件系统,此文件系统与宿主机的文件系统无关,是一个完全独立的,用于给容器进行提供环境的文件系统。
对于一个Docker容器而言,需要基于 pivot_root 指令,将容器内的系统根目录切换到rootfs上,这样,有了这个 rootfs,容器就能够为进程构建出一个完整的文件系统,且实现了与宿主机的环境隔离,也正是有了rootfs,才能实现基于容器的本地应用与云端应用运行环境的一致。
另外,为了方便镜像的复用,Docker 在镜像中引入了层(Layer)的概念,可以将不同的镜像一层一层的迭在一起。这样,如果我们要做一个新的镜像,就可以基于之前已经做好的某个镜像的基础上继续做。
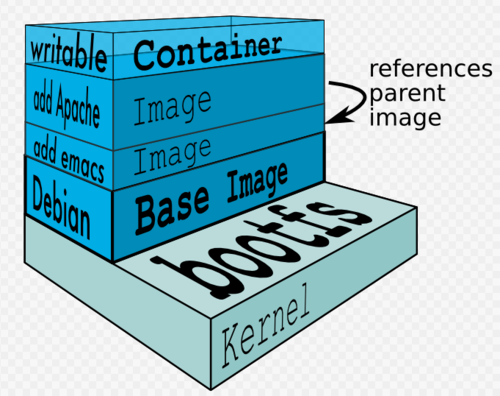
如上图,这个例子中最底层是操作系统引导,往上一层就是基础镜像层(Linux的文件系统),再往上就是我们需要的各种应用镜像,Docker 会把这些镜像联合挂载在一个挂载点上,这些镜像层都是只读的。只有最上面的容器层是可读可写的。
这种分层的方案其实是基于 联合文件系统UnionFS(Union File System)的技术实现的。它可以将不同的目录全部挂载在同一个目录下。举个例子,假如有文件夹 test1 和 test2 ,这两个文件夹里面的文件 有相同的,也有不同的。然后我们可以采用联合挂载的方式,将这两个文件夹挂载到 test3 上,那么 test3 目录里就有了 test1 和 test2 的所有文件(相同的文件有去重,不同的文件都保留)。
这个原理应用在Docker镜像中,比如有2个同学,同学A已经做好了一个基于Linux的Java环境的镜像,同学S想搭建一个Java Web环境,那么他就不必再去做Java环境的镜像了,可以直接基于同学A的镜像在上面增加Tomcat后生成新镜像即可。
以上,就是对微服务架构之「 容器技术 」的一些思考。
码字不易啊,喜欢的话不妨转发朋友,或点击文章右下角的“在看”吧。?
本文原创发布于「 不止思考 」,欢迎关注。涉及 思维认知、个人成长、架构、大数据、Web技术 等。




