
需要用到PDF文档时,我们通常可以借助工具,通过文档转换的形式来得到想要的PDF,但除此之外,我们也可以通过最直接的方式来写入内容,包括文本、图片、表格等等元素实现PDF文档的创建。由此,在本篇文章中,将介绍如何通过C#来创建带图、文元素的PDF文档。同理,对于需要读取PDF文档的情况,也将分情况来读取想要的文档内容,包括文本、图片等。在下面的示例中将做详细介绍。
示例要点梳理:
一、创建PDF文档(可支持中文)
1. 写入文本(包括页边距、字体、字号等设置)
2. 绘入图片
二、读取PDF文档
1. 读取文本
1.1 读取全部文本
1.2 读取指定区域文本
2. 读取图片
注:实现以上操作,需要借助于类库Free Spire.PDF for .NET,可自行在官网上或者在Nuget上下载最新免费版本。在编辑代码前,注意引用Spire.Pdf.dll,dll文件可在安装路径下的Bin文件夹中获取。
一、创建PDF文档
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace CreatePDF_PDF
{
class Program
{
static void Main(string[] args)
{
//初始化一个PdfDocument类实例
PdfDocument document = new PdfDocument();
//声明 PdfUnitConvertor和PdfMargins类对象
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
PdfMargins margins = new PdfMargins();
//设置页边距
margins.Top = unitCvtr.ConvertUnits(2.54f, PdfGraphicsUnit.Centimeter, PdfGraphicsUnit.Point);
margins.Bottom = margins.Top;
margins.Left = unitCvtr.ConvertUnits(3.17f, PdfGraphicsUnit.Centimeter, PdfGraphicsUnit.Point);
margins.Right = margins.Left;
//新添加一个A4大小的页面
PdfPageBase page = document.Pages.Add(PdfPageSize.A4, margins);
//自定义PdfTrueTypeFont、PdfPen实例,设置字体类型、字号和字体颜色
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("楷体", 11f),true);
PdfPen pen = new PdfPen(Color.Black);
//调用DrawString()方法在指定位置写入文本
string text = ("《蝶恋花 送春》 \n 楼外垂杨千万缕,欲系青春,少住春还去。犹自风前飘柳絮,随春且看归何处?\n 绿满山川闻杜宇,便作无情,莫也愁人苦。把酒送春春不语,黄昏却下潇潇雨。");
page.Canvas.DrawString(text, font, pen, 15, 13);
//加载图片,并调用DrawImage()方法在指定位置绘入图片
PdfImage image = PdfImage.FromFile("image1.jpg");
float width = image.Width * 0.55f;
float height = image.Height * 0.55f;
float y = (page.Canvas.ClientSize.Width - width) / 3;
page.Canvas.DrawImage(image, y, 60, width, height);
//保存并打开文档
document.SaveToFile("PDF创建.pdf");
System.Diagnostics.Process.Start("PDF创建.pdf");
}
}
}PDF文档创建结果:
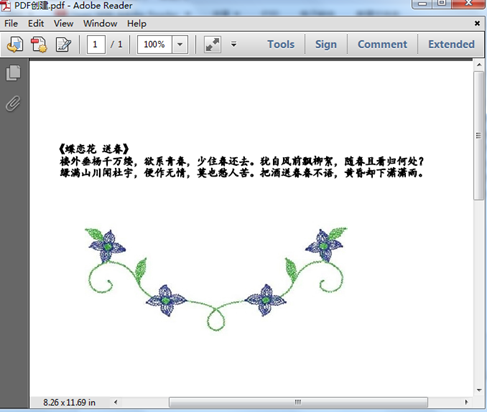
Spire.PDF支持文本、图片、图形、水印、表格、页眉页脚、页码、印章等元素,这里示例代码以添加文本、图片为例。
二、读取PDF文档
测试文档:
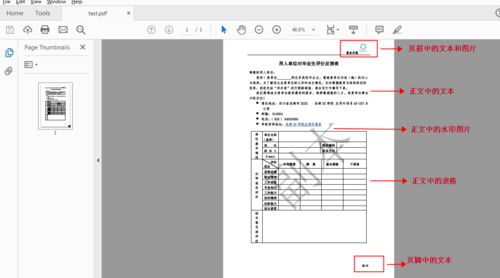
1. 读取PDF文本
1.1读取全部文本
using Spire.Pdf;
using System;
using System.IO;
using System.Text;
namespace ExtractText_PDF
{
class Program
{
static void Main(string[] args)
{
//实例化PdfDocument类对象,并加载PDF文档
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("test.pdf");
//实例化一个StringBuilder 对象
StringBuilder content = new StringBuilder();
//遍历文档所有PDF页面,提取文本
foreach (PdfPageBase page in doc.Pages)
{
content.Append(page.ExtractText());
}
//将提取到的文本写为.txt格式并保存到本地路径
String fileName = "获取文本.txt";
File.WriteAllText(fileName, content.ToString());
System.Diagnostics.Process.Start("获取文本.txt");
}
}
}全部文本读取结果:
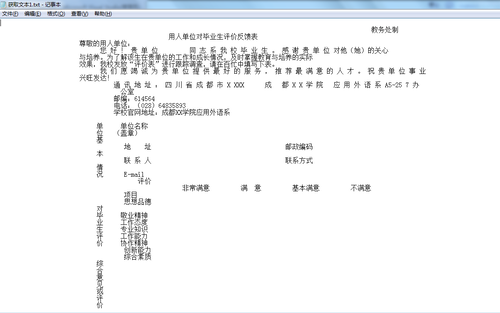
1.2 读取指定区域文本
using Spire.Pdf;
using System.IO;
using System.Text;
using System.Drawing;
namespace ExtractText1_PDF
{
class Program
{
static void Main(string[] args)
{
//创建PdfDocument类实例,并加载PDF文档
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("test.pdf");
//获取PDF第一页
PdfPageBase page = pdf.Pages[0];
//从第一页的指定矩形区域内提取文本
string text = page.ExtractText(new RectangleF(50, 50, 500, 170));
//保存文本到.txt文件,并打开文档
StringBuilder sb = new StringBuilder();
sb.AppendLine(text);
File.WriteAllText("Extract.txt", sb.ToString());
System.Diagnostics.Process.Start("Extract.txt");
}
}
}指定区域文本读取结果:
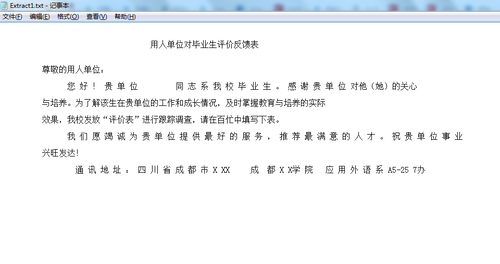
2. 读取PDF图片
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
namespace ExtractImages_PDF
{
class Program
{
static void Main(string[] args)
{
//创建一个PdfDocument类对象,加载PDF测试文档
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("test.pdf");
//声明List类对象
List<Image> ListImage = new List<Image>();
//遍历PDF文档所有页面
for (int i = 0; i < doc.Pages.Count; i++)
{
//获取文档所有页,并提取页面中的所有图片
PdfPageBase page = doc.Pages[i];
Image[] images = page.ExtractImages();
if (images != null && images.Length > 0)
{
ListImage.AddRange(images);
}
}
//将获取到的图片保存到本地路径
if (ListImage.Count > 0)
{
for (int i = 0; i < ListImage.Count; i++)
{
Image image = ListImage[i];
image.Save("image" + (i + 1).ToString() + ".png", System.Drawing.Imaging.ImageFormat.Png);
}
//打开获取到的图片
System.Diagnostics.Process.Start("image1.png");
}
}
}
}图片读取结果:
材料扩展:关于C# 如何读取PDF文档的详细操作,可以查看此视频教程。
(本文完)




