
很多Java开发同学经常有一个疑惑,搞Java开发也需要懂算法吗?本文咱们就来谈谈这个问题。
其实如果你开发一个非常复杂而且有挑战的大型系统,那么必然会在系统中使用算法。同理,如果你可以将算法进行合理的优化,那么也可以将系统性能提升几十倍!
空口无凭,下面用真实案例来进行说明。我们一起来看看Hadoop在部署了大规模的集群场景下,大量客户端并发写数据的时候,文件契约监控算法的性能优化。
Hadoop是世界上最复杂的基于Java开发的分布式系统,因此我们选用它来进行举例。从它的算法优化对系统性能的提升,就可以看出算法对于Java程序员们开发系统的重要性。
首先看懂这篇文章需要一些Hadoop的基础知识背景,了解其架构原理,所以还不太了解的同学,先看看之前的文章:《兄弟,用大白话告诉你小白都能听懂的Hadoop架构原理》。
先给大家来引入一个小的背景,假如多个客户端同时要并发的写Hadoop HDFS上的一个文件,大家觉得这个事儿能成吗?
明显不可以接受啊,兄弟们,HDFS上的文件是不允许并发的写的,比如并发的追加一些数据什么的。
所以说,HDFS里有一个机制,叫做文件契约机制
也就是说,同一时间只能有一个客户端获取NameNode上面一个文件的契约,然后才可以写入数据,此时其他客户端尝试获取文件契约的时候,就获取不到,只能干等着。通过这个机制就可以保证同一时间只有一个客户端在写一个文件。
在获取到了文件契约之后,在写文件的过程期间,那个客户端需要开启一个线程来不停的发送请求给NameNode进行文件续约,告诉NameNode:大哥,我这还在写文件呢,你给我一直保留那个契约好吗?
NameNode内部有一个专门的后台线程负责监控各个契约的续约时间,如果某个契约很长时间没续约了,此时就自动过期掉这个契约,让别的客户端来写。
大家看下面的图:
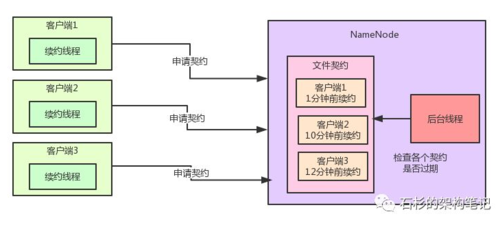
好,问题来了,假如我们有一个大规模部署到hadoop集群,同时存在的客户端可能多达成千上万个,此时NameNode内部维护的那个文件契约列表会非常非常的大。
而监控契约的后台线程又需要每隔一段时间就检查一下所有的契约是否过期,比如每隔几秒钟就遍历大量的契约,那么势必造成性能不佳,明显这种契约监控机制是不适合大规模部署的hadoop集群的。
那Hadoop是如何对文件契约监控算法进行优化的呢?咱们一步一步看一下他的实现逻辑,先一起来看下图:
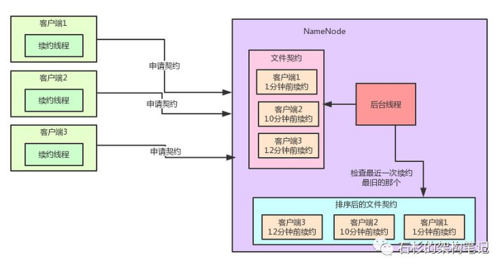
奥秘十分的简单,每次一个客户端发送续约请求之后,就设置这个契约的最近一次续约时间,然后基于一个TreeSet数据结构来根据最近一次续约时间对契约进行排序,每次都把续约时间最老的契约排在最前头,这个排序后的契约数据结构十分的重要。
TreeSet是一种可排序的数据结构,他底层基于TreeMap来实现,而TreeMap底层基于红黑树来实现,可以保证元素没有重复,同时还能按照我们自己定义的排序规则在你每次插入一个元素的时候来进行自定义的排序。
所以这里我们的排序规则,就是按照契约的最近一次续约时间来排序即可。
其实这个优化就是如此的简单,就是维护这么一个排序数据结构而已。然后我们可以看一下Hadoop中的契约监控的源码实现:
Lease leaseToCheck = null;try {leaseToCheck = sortedLeases.first();} catch(NoSuchElementException e) {}while(leaseToCheck != null) {if (!leaseToCheck.expiredHardLimit()) {break;}}
怎么样?是不是不得不佩服那些写出Hadoop、Spring Cloud等优秀开源项目的大牛的技术水平,大量的阅读各种复杂而且优秀的开源项目的源码,确实是可以快速的提升一个人的架构能力、技术能力和技术视野,这也是我平时花费大量时间做的事情。
每次检查契约是否过期的时候,你不要遍历成千上万的契约,那样遍历效率很低下,完全可以就从TreeSet中获取续约时间最老的那个契约
假如说连最近一次续约时间最老的那个契约都还没过期,那么就不用继续检查了啊!因为说明续约时间更近的那些契约绝对不会过期!
举个例子,续约时间最老的那个契约,最近一次续约的时间是10分钟以前,但是我们判断契约过期的限制是超过15分钟不续约就过期那个契约。
这个时候连10分总以前续约的契约都没有过期,那么那些8分钟以前,5分钟以前续约的契约,肯定也不会过期了,就是这个意思!
这个机制对性能的提升是相当有帮助的,因为正常来说,过期的契约肯定还是占少数,所以压根儿不用每次都遍历所有的契约来检查是否过期,只要检查续约时间最旧的那几个契约就可以了。
如果一个契约过期了,那么就删掉那个契约,然后再检查第二旧的契约好了。以此类推。
通过这个TreeSet排序 + 优先检查最旧契约的机制,有效的将大规模集群下的契约监控机制的性能提升至少10倍以上,这个思想,在我们自己进行系统设计时,是非常值得我们学习和借鉴的。
给大家引申一下,在Spring Cloud微服务架构中,Eureka作为注册中心其实也有续约检查的机制,跟Hadoop是类似的(不清楚的同学建议看一下:《拜托,面试请不要再问我Spring Cloud底层原理!》)
但是在Eureka中就没有实现类似的续约优化机制,而是暴力的每一轮都遍历所有的服务实例的续约时间。
假如你是一个大规模部署的微服务系统呢?比如部署了几十万台机器的大规模系统,有几十万个服务实例的续约信息驻留在Eureka的内存中,你难道要每隔几秒钟遍历一下几十万个服务实例的续约信息吗?
相信看到这里,本文开头提出的Java工程师是否也要懂一些算法,大家心里也有答案了吧!
END
石杉的架构笔记(id:shishan100)
作者:中华石杉,多年BAT架构经验倾囊相授
















热门评论
-

慕粉14728657072019-07-23 2
-

慕粉14728657072019-07-23 2
-

guofengio2019-07-23 1
查看全部评论这也能算算法?只能算方法,别往上靠了!
这也能算算法?只能算方法,别往上靠了!
当然不需要??????