
索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就获取到的,很多的技术人员因为不恰当的创建索引,最后使得其效果适得其反,可以说“成也索引,败也索引”。
重点介绍了非聚集索引,在我们的第一个例子中展示了使用非聚集索引从一个表中取得一行数据所带来的潜在好处。在本篇文章中,我们继续研究非聚集索引,本篇文章所研究的内容就要比使用非聚集索引在单表中查询一行所带来的性能提升更深一步了。
本系列文章将要列举的一些例子中介绍的部分理论是关于是非聚集索引的理论,并通过探究索引的内部结构来帮助更好的理解这些理论,在此基础上,我们分别在存在索引和不存在索引的情况下分别执行相同的查询并通过统计数据来比较性能。因此我们就可以体会到索引带来的影响了。
我们继续使用在第一篇文章中曾使用过的AdventureWorks内的部分数据。尤其是Contact表,我们仅仅使用一个我们在上篇文中中使用过的FullName索引。为了更好的测试非聚集索引带来的影响,我将建两个Contact表,其中一个存在FullName非聚集索引,而另一个不存在。总之就是,两个相同的表,一个表中存在非聚集索引,另一个不存在非聚集索引。
注意:本篇文章中的T-SQL代码都可以在文章底部找到下载链接
列表1所示代码创建了Person.Contact表的副本,如果你想恢复到初始测试状态,你可以随时运行这段代码。
IF EXISTS ( SELECT *
FROM sys.tables
WHERE OBJECT_ID = OBJECT_ID('dbo.Contacts_index') )
DROP TABLE dbo.Contacts_index ;
GO
IF EXISTS ( SELECT *
FROM sys.tables
WHERE OBJECT_ID = OBJECT_ID('dbo.Contacts_noindex') )
DROP TABLE dbo.Contacts_noindex ;
GO
SELECT *
INTO dbo.Contacts_index
FROM Person.Contact ;
SELECT *
INTO dbo.Contacts_noindex
FROM Person.Contact ;
Contacts表内的部分数据如下所示:
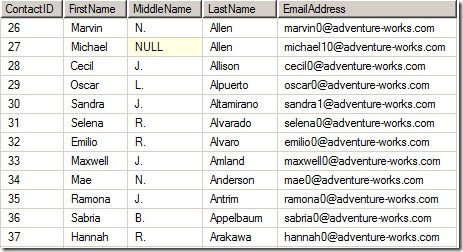
非聚集索引条目
如下代码段在Contacts_index表上创建名为FullName的非聚集索引.
CREATE INDEX FullName ON Contacts_index ( LastName, FirstName ) ;
代码段2.2 -创建非聚集索引
不要忘了非聚集索引按顺序存储索引键。就像书签可以用于直接访问表中的数据那样,你也可以把书签想象成一种指针,在接下来的文章中我们将更详细的讨论书签的组成和用法。
FullName索引的部分数据如下,由LastName和FirstName作为索引键外加一个书签组成。
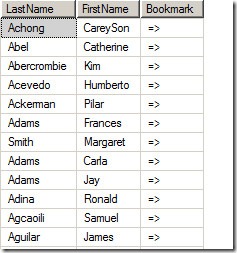
每一个条目都由索引键列和书签值组成。除此之外,SQL Server中非聚集索引条目还包含了一些可选的头数据,用于SQL Server内部使用。这两个非聚集索引条目的组成部分对于理解非聚集索引基础并不重要,所以安排在后续系列文章中进行讲解。
索引条目有序带来的好处
索引条目按照索引键的值有序排列,这样SQL Server就能快速有序的遍历索引条目。对于有序的条目的扫描操作既可以从头到尾,也可以从尾到头,甚至是从任意条目开始。
因此,如果一个查询请求想要得到contacts表中lastname以字母s开头的数据(WHERE LastName LIKE 'S%'),SQL Server会直接找到第一条s开头的条目(“Sabella, Deanna”)并以此为出发点进行扫描,直到扫描到第一条以T开头的条目,这时SQL Server就知道s开头的条目全部扫描完成,然后使用书签访问数据。
上面的请求的列中如果仅仅包含在非聚集索引中,那么这个查询会执行的更快
SELECT FirstName , LastName FROM Contact WHERE LastName LIKE 'S%' ;
SQL Server可以快速的导航到第一条S开头的条目,然后在无视书签的情况下遍历索引条目并直接从索引中取得数据,直到遇到T开头的索引条目时扫描结束。在关系数据库的术语中,这个索引“覆盖”了查询请求。
任何由顺序数据给SQL操作带来的好处也可以同样由索引带来,这些操作包括 ORDER BY, GROUP BY, DISTINCT, UNION (不是UNION ALL), 以及JOIN…ON。
比如,SQL Server使用聚合函数Count根据LastName列来查询Contact表有多少个联系人。就像前面的例子一样,这是一个覆盖索引,SQL Server无视了Contact表,仅仅从索引取得所需数据。
值得注意的是键列的顺序是由左到右的。也就是说前面所建的FullName索引如果按照非聚集索引键第一列LastName列作为查询条件时将会非常有用,而如果以FirstName作为查询条件或许起的作用就不是那么大了。
测试示例查询
如果你想执行下面的查询语句,请确保你首先按照前面的代码创建了dbo.Contacts_index 和dbo.Contacts_noindex这两个表,并创建了顺序为LastName, FirstName 的非聚集索引dbo.Contacts_index.
为了证实我前面的理论,我通过下面代码开启统计数据并在有非聚集索引和没有非聚集索引存在的情况下执行相同的数据。
SET STATISTICS io ON SET STATISTICS time ON
因为AdventureWorks数据库的Contact表中仅有19972行数据,因此很难从时间统计中看出倪端,测试的大部分执行语句CPU时间都是0,因此就不再显示CPU时间了。仅仅显示能反映出可能读取的页数的IO统计。这个值可以帮助我们对比同样查询在存在非聚集索引和不存在非聚集索引的情况下比较同样查询语句的性能。如果你想做一些更接近实际的CPU时间测试,在文章的末尾可以找到百万级别的Contact表的创建代码。下面的结论仅仅是针对标准的19972行的Contact表。
测试查询覆盖
第一条查询是取出Contact表中LastName列以S开头的数据,仅仅取出FirstName列和LastName列,因此可以被索引覆盖,如表2.1所示。
| SQL语句 | SELECT FirstName, LastName
|
| 没有非聚集索引 | (2130 行受影响) |
| 有非聚集索引 | (2130 行受影响) |
| 索引影响 | IO从568次降低到14次 |
| 评注 | 覆盖索引对性能提升巨大,如果没有索引,需要扫描整张表来找到所需数据,“2130 行”意味着以S开头的姓还是挺多的,占到整个Contact表的10% |
表2.1 运行覆盖查询后的执行结果
测试非覆盖查询
接下来,和上面语句类似,只是执行语句中包含的列更多了,查询的执行信息如表2.2所示
| SQL语句 | SELECT *
|
| 没有非聚集索引 | (2130 行受影响) |
| 有非聚集索引 | (2130 行受影响) |
| 索引影响 | 完全没有影响 |
| 评注 | 索引在查询执行期间完全没有被用到! 因为使用书签查找的成本远远高于整表扫描,因此SQL Server决定使用整表扫描. |
表2.1 运行非覆盖查询后的执行结果
测试非覆盖索引,但是选择更少的列
| SQL语句 | SELECT *
|
| 没有非聚集索引 | (107行受影响) |
| 有非聚集索引 | (107行受影响) |
| 索引影响 | IO由568降低到111 |
| 评注 | SQL Server访问了107条索引内连续的”Ste”条目。通过每个索引条目中的书签找到对应原表中的行,原表中的行并不连续。 非聚集索引减少了这个查询的IO,但是根据测试结果可以看出,带来的好处并不如覆盖查询,尤其是这条查询还需要很多IO来获取原表中的行。 你可能会认为107个索引条目加上107行应该是107+107个IO读,但仅仅111个IO读的原因会在后续文章中提到,你现在只要知道只有少部分读用于访问索引条目,大部分IO读都用在了访问原表。 根据表2.2,也就是那个返回2130行数据的查询,是不能够从索引中获益的,而这条索引只读取107行,是可以从索引中获益的,你也许会有疑问“那SQL Server如果知道索引是否能够给查询带来增益呢”,这部分我们会在后续文章中讲解。 |
表2.3 执行返回更少的数据的非覆盖查询后的执行结果
测试聚合覆盖查询
我们最后的例子是聚合查询,也就是查询中使用了聚合。下面的查询根据LastName和FirstName进行分组来找到姓名完全相同的人.
部分查询结果如下:
Steel Merrill 1
Steele Joan 1
Steele Laura 2
Steelman Shanay 1
Steen Heidi 2
Stefani Stefano 1
Steiner Alan 1
查询执行的详细信息见表2.4
| SQL语句 | SELECT LastName, FirstName, COUNT(*) as 'Contacts' |
| 没有非聚集索引 | (104行受影响) |
| 有非聚集索引 | (104行受影响) |
| 索引影响 | IO由568降低到4 |
| 评注 | 查询所需的所有信息读包含在索引中,并且这些条目在索引中还是按顺序存放,所有以Ste开头的条目都在索引中按顺序进行存放。查询按FirstName和LastName的值进行了聚合分组。 既不需要访问表,也不需要进行排序操作,还是那句话,覆盖索引性能提升巨大。 |
表2.4 覆盖聚集查询的执行结果
测试非覆盖聚合查询
我们在上面查询的基础上加入索引中不包含的列,得到了表2.5中的测试数据
| SQL语句 | SELECT LastName, FirstName, MiddleName, COUNT(*) as 'Contacts' --分别执行在Contacts_noindex表和Contacts_index表上 WHERE LastName LIKE 'Ste%' |
| 没有非聚集索引 | (105行受影响) |
| 有非聚集索引 | (105行受影响) |
| 索引影响 | IO由568次降为111次,和前面非覆盖查询的性能一致。 |
| 备注 | 比如像使用内存和TempDB的中间工作过程有时候不再统计信息所包含的范围之内,实际上,索引带来的好处很多时候要比统计信息显示的还要多。 |
表2.5 运行非覆盖聚合查询后的执行结果
总结
我们知道非聚集索引有如下特点,非聚集索引是
实体的有序集合
每一行都有一个对应所在表的入口指针
包含索引键和书签
由用户创建
由SQL Server维护
被SQL Server用来减少查询所付出的代价
目前为止,文中所演示的查询既可以仅仅索引获取数据,也可以仅仅通过表获取,又或者是二者结合。
当一个查询被传到数据引擎时,SQL Server可以通过三种路径获取数据来满足这个查询。
不需要访问表仅需要访问索引本身,这种情况必须是索引覆盖了请求所包含的列
使用索引键值去访问非聚集索引,然后使用书签访问非聚集索引所在表
无视非聚集索引扫描基本表来获取数据
通常情况下,第一种方式是最理想的,第二种方式好于第三种。在接下的文章中我会讲述如何提高索引覆盖的概率以及如何知道指定非覆盖查询如何从非聚集索引获益。但是这需要对索引的内部的结构有更深入的了解,这已经超越了本篇文章的内容。



