
最近几年Golang编程语言在系统开发领域非常的火,尤其在DevOps应用上清一色选择Golang,像人人皆知的容器界的Docker和Kubernetes云计算巨头项目,还有InfluxDB、Grafana、Consul等各种大名鼎鼎的应用都是Golang开发的,国内使用Golang来开发的,像Codis,Kingshard,Tidb等中间件和数据库,在国内的很多知名互联网公司,在技术平台领域也纷纷拥抱Golang,像阿里、百度、腾讯、字节跳动、小米、七牛、滴滴、华为、有赞等等。
这里有份使用Go语言的中国公司列表https://github.com/golang/go/wiki/GoUsers#china。
这些也都是得益于Golang天生的高并发、跨平台编译型的静态类型、自动垃圾回收等众多优秀的特性。另外硬件发展的限制,自从2004年90纳米3.8GHZ奔腾4 CPU发布之后,如今的CPU仍然在3.0GHZ附近徘徊,摩尔定律正在失效。通过增加内核数量,仍然是提高CPU性能的主要手段,靠硬件来提升性能终究会受限,使用更高效的编程语言成为主要的优化手段之一,Golang编程语言是编译型语言,是直接编译为机器码运行的,是直接运行在硬件之上,它的性能接近C语言,并且自备垃圾回收,轻量级goroutine为多核并发计算带来了强大的支持,在进程中创建数百万个goroutine是轻而易举的事情。强大的后盾Google,像Adobe、BBC、IBM、英特尔等大公司都在使用。
国内很多云厂商大量使用Golang来开发云平台中间件,Golang开发人员的需求也日益庞大。我这里引用七牛CEO许式伟的一个预测,“Go 语言将会制霸云计算领域”“Go 将统治下一个 10 年”,。最近也鲜有公司从其他编程语言迁移到Golang语言的案例,比如Stream公司把核心代码从Python换成Go语言,提速30倍,在他们的基准测试中,Go的性能表现和Java、C ++相当,比Python快大约30倍。不仅如此,Go干净简洁的语法,可阅读性和可维护性不知要比Python好几条街。
AppsFlyer是一个领先的移动归因和市场分析平台,每天处理近 700 亿次 HTTP 请求,AppsFlyer 已经将 API 网关服务从 Clojure 迁移到 Golang,在他们的基准测试中,Go 比 Clojure 提供了更高的吞吐量。
2019年4月22日B站源代码被泄漏了,短短7个小时就被fork 100多份,随后所有的备份都被GitHub封杀,泄漏同时也被爆出的是B站使用的编程语言是Golang,就有人调戏说:“B站为推广Go语言,做出了不可磨灭的贡献”。名叫“openbilibili”的用户创建的“go-common”代码库,项目描述为“哔哩哔哩bilibili网站后台工程源码”,截至北京时间17:04,该项目已获得6597个标星和6050个代码库分支(fork) ,最终获得9000+的star。
在最近的一项调查结果显示,2019 年程序员最想要学习的编程语言:Go。
参考:https://hackernoon.com/top-3-programming-language-to-watch-out-in-2019-95995e81ad2b
2019 年,程序员最想学习的编程语言 Top 3 分别是 Go、Kotlin 和 Python,其中 Go 以 37.2% 的比例排在首位。Golang 要替代编程界的大V Java显然在短期内是不可实现的,相比Java 20多岁,Golang还年轻,但已经具备了很多非常优秀的特性:静态编译和静态类型的特性可以帮助我们很好的编写代码,专注代码和业务本身,无需关心语法啊、变量和函数命名错误啊,参数传递错误啊这些事情;虽然是编译型语言,但Golang的开发速度不会因这个变慢,要比传统的C/C++好很多;天生自带高并发光环,使用Goroutines跟调用普通函数一样简单。
还有其他特性像自动垃圾回收、交叉编译、代码格式风格一致等等就不一一讲了,各种集成开发工具的支持也很丰富,来自微软的VSCode、大名鼎鼎Jetbrains的Goland、还有国内开发者七叶的LiteIDE X等都是很好的选择。Go非常适合开发微服务分布式系统,在“Go”进入公众视野前,似乎没有真正可以替代 Scala 的语言。Go 语言的适用范围一直在不断地扩大。经过广大开发者的共同努力,它已开始涉足在当前大热的数据科学和机器学习领域。更令人欣慰的是,中国的开发者对于 Go 语言的流行起着至关重要的作用。在谷歌趋势中的统计结果来看点击查看,在过去的一年里,中国对go的的热衷和贡献依然领跑全世界,其实这也不奇怪,Java也是中国领跑全世界!
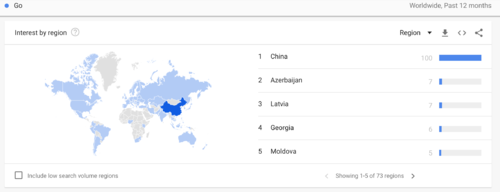
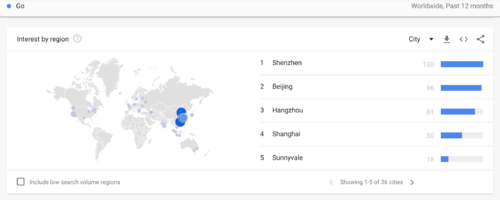
在中国,北京、深圳、杭州、上海等互联网网红城市,也是Golang的网红城市,北京领跑,但领跑Java是却都在印度,第一的是印度的宾布里金杰沃德。
2007年,受够了C++煎熬的Google首席软件工程师Rob Pike纠集Robert Griesemer和Ken Thompson两位牛人,决定创造一种新语言来取代C++, 这就是Golang。出现在21世纪的GO语言,虽然不能如愿对C++取而代之,但是其近C的执行性能和近解析型语言的开发效率以及近乎于完美的编译速度,已经风靡全球。特别是在云项目中,大部分都使用了Golang来开发,不得不说,Golang早已深入人心。而对于一个没有历史负担的新项目,Golang或许就是个不二的选择。
被称为GO语言之父的Rob Pike说,你是否同意GO语言,取决于你是认可少就是多,还是少就是少(Less is more or less is less)。Rob Pike以一种非常朴素的方式,概括了GO语言的整个设计哲学–将简单、实用体现得淋漓尽致。很多人将GO语言称为21世纪的C语言,因为GO不仅拥有C的简洁和性能,而且还很好的提供了21世纪互联网环境下服务端开发的各种实用特性,让开发者在语言级别就可以方便的得到自己想要的东西。
根据一些技术分析专家说,Golang编程语言在未来10年会成为一种通用性编程语言,成为编程界的霸主,是最有可能会替代Java的编程语言。既然Golang语言这么牛掰,那么到底牛掰在哪里,下面就说说,下面是我总结的Golang语言的几个重要特性:
- 简洁 快速 安全
- 并行 有趣 开源
- 内存管理
- 编译迅速
- 交叉编译
- 运行时无依赖
- 可执行码
- 跨平台
这些特性已经说明了分Golang语言的优势,简明扼要,开发效率高。
Golang从语言层面支持并发,这个就是Go最大的特色,天生的支持并发, Go语言引入了goroutine概念,Go语言让并发编程变得非常简单,且更加安全。只需要在函数调用前使用关键字go,就可以让该函数以goroutine方式执行,goroutine是Golang语言级别的协程, 它比线程更轻量、开销更小更省资源,性能更高,切操作起来非常简单。
Golang是编译型编程语言,执行速度很快, 可直接编译成机器码,除了对glibc的版本有一定和操作系统平台有要求外,不依赖其他库,可以编译成一个操作系统平台包,部署时扔一个文件上去就完成了,运行的系统中不需要安装任何运行时或其他组件。同时呢支持交叉编译,不管编译打包的是哪种操作系统平台,都可以编程成支持的任何一种平台包。
除了这些特性之外,golang还具有和java一样的自动垃圾回收,还具备反射。并且内置了大量丰富的标准库,覆盖非常全面,基本上不需要获取第三方库就可以开发应用。golang语言适合服务器端的系统编程、网络、中间件等系统级开发,适合高性能高并发的服务端应用开发。提到高并发,Go是原生支持啊,不得不讲Goroutines和Channels,下面我就带着大家来认识一下Goroutines和Channels。
首先来学习一下Goroutines,Goroutine是一个可执行的轻量级线程,常常被叫做协程。在golang中使用协程非常的简单,只需要在Go函数前面使用go关键字就可以运行协程。下面的例子是一个连续打印时间戳的程序,先来看看
import (
"fmt"
"time"
)
func main() {
t1 := time.Now()
for i := 0; i < 10; i++ {
printTime()
}
t2 := time.Now()
d := t2.UnixNano() - t1.UnixNano()
fmt.Println("完成:", d/int64(time.Millisecond), "ms")
}
func printTime() {
fmt.Println(time.Now().UnixNano())
time.Sleep(100 * time.Millisecond)
}
这段代码运行之后,会将连续的时间打印到控制台,每打印一次,暂停100毫秒,打印10次,预期需要1秒多时间:
1557109955565058000
1557109955668886000
1557109955769397000
1557109955871310000
1557109955976517000
1557109956081232000
1557109956185634000
1557109956290207000
1557109956394777000
1557109956497913000
完成: 1035 ms
来改造一下程序,在循环中printTime()调用前加上go关键字,加了go关键字后,程序不在顺序执行,会提交到执行队列中通过协程异步来运行,所以循环结束后程序会自动退出,还来不及打印所有时间戳。这里使用到一个计数的信号量同步结构体sync.WaitGroup,使用的目的是要循环完成后等待所有的goroutine执行完成后再结束,不然这两个goroutine还在运行的时候,程序就结束了,看不到想要的结果。sync.WaitGroup的使用也非常简单,每启动一个goroutine时使用Add 方法增加一个计数,每一个goroutine的函数执行完之后,就调用Done方法减1。使用Wait方法来阻塞等待所有的协程都执行完成,基本逻辑是如果计数器大于0,就会阻塞,下面来看看使用goroutine的程序:
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func main() {
t1 := time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go printTime()
}
wg.Wait()
t2 := time.Now()
d := t2.UnixNano() - t1.UnixNano()
fmt.Println("完成:", d/int64(time.Millisecond), "ms")
}
func printTime() {
fmt.Println(time.Now().UnixNano())
time.Sleep(100 * time.Millisecond)
wg.Done()
}
执行结果是:
1557110361798021000
1557110361798298000
1557110361798333000
1557110361798339000
1557110361798341000
1557110361798342000
1557110361798343000
1557110361798323000
1557110361798344000
1557110361798344000
完成: 114 ms
从执行结果可以看到,没有使用协程时程序顺序执行花费了1000多毫秒,使用协程后程序并发执行,只花费了110多毫秒。实际上在golang中可以创建数百万个协程,可以试试创建10万个协程,100万个协程来运行,在我的电脑上10万个协程运行花费了1300多毫秒,100万个协程运行花费了12900多毫秒,如果没有使用协程,运行10万次需要10000*100=1千万毫秒,。
下面再来看一下goroutines的补充channels,channels是用来连接并发goroutine的管道,可以在一个goroutine中发送数据,并在另一个goroutine中从channel中接受数据。先睹为快:
import (
"fmt"
"time"
)
func main() {
//创建一个string类型的channel
c := make(chan string)
//在协程中发送一个数字到channel
go func() {
fmt.Println(time.Now().UnixNano())
time.Sleep(1000 * time.Millisecond)
fmt.Println("goroutine完成")
c <- "完成"
}()
//在主协程中,从channel中接受数据并打印到控制台
fmt.Println(<-c)
}
从这里例子中可以看到,channel通过内建的make函数来创建,语法是:make(chan type),在创建channel时需要指定数据类型,那么定义好的channel就只能发送和接受指定的数据类型。在这个例子中channel定义为string类型的channel,在一个协程中执行任务,任务完成后,写入消息到channel中,在主协程中来来接受这个channel中的数据,如果在任务协程中还没有完成时,程序会一直阻塞直到有消息发送到通道中。
Channel是双向的,使用<-操作符来接受和发送数据,箭头的方向代表了数据的流入和流出方向,使用chan <-向channel中发送数据,使用<- chan从channel中读取数据,
无缓冲channel
默认情况下,channel是无缓冲的,并且发送与接收默认也是阻塞的,也就是说当把数据发送到channel时,发送数据会发生阻塞,直到有其它 Go 协程从channel中读取数据。无缓冲channel的发送和接受是同时发生的,简单理解为0缓冲,也就是channel中没有多余的空间来缓冲数据,发送者直接将数据交给接受者。从无缓存的 channel 中读取消息会阻塞,直到有 goroutine 向该 channel 中发送消息;同理,向无缓存的 channel 中发送消息也会阻塞,直到有 goroutine 从 channel 中读取消息。
有缓冲channel
在创建channel时,可以指定channel的容量,指定了容量的channel是有缓冲channel。如果容量指定为0就代表无缓冲channel;容量指定为大于0,那么就是有缓冲channel。有缓冲channel通过make函数的第二个参数来指定容量,比如:make(chan int64, 3)。
有缓冲的channel的读写是异步的,有点像一个可阻塞队列,发送消息会先放到channel,接受消息时从channel中按顺序读取消息。如果在channel中缓冲的消息达到容量上限即channel被占满时,发送消息时会被阻塞直到有消息被接受者读取,接受者可以正常读取消息;如果channel为空时,接受者读取消息时会被阻塞,发送者可以正常发送消息。
下面这个例子中,创建了一个容量为3的channel,数据类型为int64,用一个协程向channel中连续写入10个时间戳,另一个协程中从channel读取10次并打印到控制台。
import (
"fmt"
"time"
)
func main() {
//缓冲容量为3的channel
c := make(chan int64, 3)
//在协程中向channel中写数据
go func() {
for i := 0; i < 10; i = i + 1 {
c <- time.Now().UnixNano()
}
}()
go func() {
for i := 0; i < 10; i = i + 1 {
s := <-c
fmt.Println(s)
}
}()
fmt.Scanln()
fmt.Println("完成")
}
下面就来改造一下前面打印时间戳的例子,这里不用sync.WaitGroup,使用channel来完成同样的事情,先上代码:
import (
"fmt"
"time"
)
var messages chan int64
func main() {
t1 := time.Now()
//初始化一个int64类型,size容量的channel
size := 6
messages = make(chan int64, 10)
//循环size次,向channel中写入时间戳
for i := 0; i < size; i++ {
go sendTime()
}
sync := make(chan string, 1) //等待答应完成
//用main协程从channel中读取时间戳并打印出来
//如果channel中无消息时会阻塞
go func() {
for i := 0; i < size; i++ {
fmt.Println(<-messages)
}
sync <- "完成"
}()
fmt.Println("等待所有的go协程完成执行")
fmt.Println(<-sync)
t2 := time.Now()
d := t2.UnixNano() - t1.UnixNano()
fmt.Println("完成:", d/int64(time.Millisecond), "ms")
}
func sendTime() {
time.Sleep(100 * time.Millisecond)
messages <- time.Now().UnixNano()
}
这个例子中,创建了2个channel:
messageschannel用来在不同协程之间传递消息,并且在messages 被定义为一个有缓冲的,容量为10的channel,在多个协程中向messages发送消息,并在1个协程中接受消息并打印到控制台。syncchannel用来跨goroutine同步执行,这是一个使用阻塞接收等待goroutine完成的示例,在主协程中等待所有的协程任务执行完成后,计算任务执行时间并打印且完成。sync被定义为一个容量为1的channel,当sync channel中无数据时会被阻塞,直到有数据进入。
有缓冲channel的同步
容量为1的channel是有缓冲channel的特殊情况,可以用在2个goroutine之间同步状态,或者其中一个等待另一个完成时才继续执行任务的情况。有点类似无缓冲channel,但他们之间也是有区别的,无缓存的 channel 的容量始终未0,发送者发送数据和接受者接受数据时同时的,无任何中间态,不能缓冲任何数据。容量为1的channel是可以缓冲1个数据,发送者和接受者之间可以不同时进行,可以发送者可以先把数据放进去,接受者可以过会儿再读取数据。无缓存的 channel 的发送者和接受者是相互等待,发送者等待接受者就备才能发送数据,接受者等待发送者就备才能接受数据,如果无缓存的 channel 在同一个协程中既发送又接受就会造成死锁而报错。
channel还可以使用Range来遍历channel
使用for range来遍历channel,会自动等待channel的操作,一直到channel被关闭,下面来看看使用Range来遍历channel的例子,程序中使用了2个协程,一个用来向channel中写入时间戳,另一个协程通过Range来遍历和读取channel中的数据,并打印到控制台:
import (
"fmt"
"time"
)
func main() {
//缓冲容量为3的channel
c := make(chan int64, 3)
//在协程中向channel中写数据
go func() {
for i := 0; i < 10; i++ {
c <- time.Now().UnixNano()
}
}()
//通过range来打印数据,直到channel被关闭
go func() {
for i := range c {
fmt.Println(i)
}
}()
fmt.Scanln()
fmt.Println("完成")
}
上面的例子中使用了fmt.Scanln()通过控制台输入扫描来hold住控制台,不让程序退出。实际上上面也提到range会一直等待channel被关闭才会退出循环,所以这个例子可以稍微改造一下, 第一个协程发送完数据之后关闭channel,使用range遍历读取channel中的数据,当channel被关闭后会退出循环结束程序:
import (
"fmt"
"time"
)
func main() {
//缓冲容量为3的channel
c := make(chan int64, 3)
//在协程中向channel中写数据
go func() {
for i := 0; i < 10; i++ {
c <- time.Now().UnixNano()
}
close(c)
}()
//通过range来打印数据,直到channel被关闭
for i := range c {
fmt.Println(i)
}
fmt.Println("完成")
}
关闭Channel
例子中可以看到,关闭channel使用了内建的函数close,对于关闭channel需要注意如下几点:
- 如果向已经关闭的channel写数据就会导致
panic: send on closed channel; - 从已经关闭的channel中读取数据是不会导致panic的,可以继续读取已经发送的数据,但如果已经发送的数据读取完成时继续读取,就会会读取到类型默认值或者零值;
- 如果通过
range读取数据,channel关闭后就会跳出for循环; - 如果重复再关闭已经关闭的channel,也会导致panic。
使用Select处理多个channel
Golang中的select 可以等待和处理多个通道。将goroutines、channel和select相结合是Go的一个非常强大功能。使用select可以在case语句中选择一组channel中未阻赛的channel。select只会执行一次不会循环,只会选择一个case来处理,如果要一直处理channel,通常要结合一个无限for循环一起来使用:
import "time"
import "fmt"
func main() {
//创建2个channel
c1 := make(chan string)
c2 := make(chan string)
//通过2个协程分别往2个channel中写数据
go func() {
for i := 0; i < 9; i++ {
time.Sleep(100 * time.Millisecond)
c1 <- fmt.Sprintf("c1: %d", i+1)
}
}()
go func() {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
c2 <- fmt.Sprintf("c2: %d", i+1)
}
}()
//通过1个协程从2个channel中读取数据,如果没有数据则阻塞
go func() {
for {
select {
case msg1 := <-c1:
fmt.Printf("received %d: %s \n", time.Now().Unix(), msg1)
case msg2 := <-c2:
fmt.Printf("received %d: %s \n", time.Now().Unix(), msg2)
}
}
}()
fmt.Scanln()
}
在这个例子中创建了2个channel,分别使用2个协程往这2个channel中写数据,专门使用了1个协程,在这个协程中使用for 无限循环+select来选择和读取2个channel中的数据,如果2个channel都无数据可读时,会阻塞;如果其中只要有一个有数据,就会选择,继续执行。在default case存在的情况下,如果没有case需要处理,则会选择default去处理;如果没有default case,则select语句会阻塞,直到某个case需要处理。
需要注意的是,如果在使用for 无限循环+select来操作多个channel,当channel被关闭后,会一直读取类型默认值,这样会导致进入无限死循环,下面的例子中2个channel都被关闭,就会形成一个无限死循环:
import "time"
import "fmt"
func main() {
//创建2个channel
c1 := make(chan string)
c2 := make(chan string)
//通过2个协程分别往2个channel中写数据
go func() {
for i := 0; i < 9; i++ {
time.Sleep(100 * time.Millisecond)
c1 <- fmt.Sprintf("c1: %d", i+1)
}
close(c1)
}()
go func() {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
c2 <- fmt.Sprintf("c2: %d", i+1)
}
close(c2)
}()
//通过1个协程从2个channel中读取数据,如果没有数据则阻塞
go func() {
for {
select {
case msg1 := <-c1:
fmt.Printf("received %d: %s \n", time.Now().Unix(), msg1)
case msg2 := <-c2:
fmt.Printf("received %d: %s \n", time.Now().Unix(), msg2)
}
}
}()
fmt.Scanln()
}
对于读取已经关闭的channel时,可以使用返回值来判断channel是否被关闭,下面的例子中如果返回的ok为false,就说明channel已经被关闭:
i, ok := <-c
if !ok {
//channel已经被关闭
}
那么为了防止死循环,可以在读取channel数据时判断是否被关闭,使用break语句跳出循环:
import "time"
import "fmt"
func main() {
//创建2个channel
c1 := make(chan string)
c2 := make(chan string)
//通过2个协程分别往2个channel中写数据
go func() {
for i := 0; i < 9; i++ {
time.Sleep(100 * time.Millisecond)
c1 <- fmt.Sprintf("c1: %d", i+1)
}
close(c1)
}()
go func() {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
c2 <- fmt.Sprintf("c2: %d", i+1)
}
close(c2)
}()
//通过1个协程从2个channel中读取数据,如果没有数据则阻塞
loop:
for {
select {
case msg1, ok := <-c1:
if !ok {
break loop
}
fmt.Printf("received %d: %s \n", time.Now().Unix(), msg1)
case msg2, ok := <-c2:
if !ok {
break loop
}
fmt.Printf("received %d: %s \n", time.Now().Unix(), msg2)
}
}
}
Select超时
在select中还可以处理超时,超时在处理外部资源或需要绑定执行时间的程序非常重要,通过channel和select,在Go中可以很容易且优雅的实现超时机制。在下面的例子中使用一个协程来模拟任务处理,利用sleep 5秒钟来模拟任务执行时间,任务完成后向channel中写入结果;在select语句中实现超时,第一个case来读取channel中的数据,等待结果写入;第二个channel中使用time.After(3 * time.Second)来等待3秒超时时间。由于实际任务执行时间是5秒钟,超时时间是3秒钟,所以等待3秒钟后,time.After返回的channel中会写入一个时间,select语句就选择第二个case执行,然后结束程序:
import "time"
import "fmt"
func main() {
c1 := make(chan string, 1)
go func() {
fmt.Println("开始时间", time.Now().Unix())
time.Sleep(5 * time.Second)
c1 <- "result 1"
}()
select {
case res := <-c1:
fmt.Println(res)
case <-time.After(3 * time.Second):
fmt.Println("timeout 3")
}
fmt.Println("完成时间:", time.Now().Unix())
}
总之来说,Golang中的并发goroutines和channels是Go语言中的2大马车,goroutine被设计的如此简单,channel被设计为通过通信来共享数据的方式。使用共享变量来共享数据使得并发编程变得困难,在Go语言中采用了一种不同的方法,在这种方法中,共享数据被放在channel中传递,实际上,在特定时间点,只有一个goroutine可以访问该值。在设计中,数据竞争绝不会发生。所以将这个设计简化为一个口号是:
不要通过共享内存进行通信; 相反,要通过通信来共享内存。
goroutines和channels为Go语言中提供了一种优雅而独特的结构化并发开发的方法。建议使用Channel在goroutine之间传递对数据的引用,而不是显式地使用锁来处理共享数据的访问,这种方法可以确保同一时间只有一个goroutine可以访问数据。学好如何使用channels对于golang并发编程的第一步。
参考:
















热门评论
-

CYW好好学习2019-05-10 1
-

华Oliver2019-05-10 0
查看全部评论我不知道算不算用错词,“最近也鲜有公司从其他编程语言迁移到Golang语言的案例”,“鲜有”是很少有,几乎没有的意思。
总结得不错,感谢楼主的归纳整理分享。