
原作 Josh Gordon
栗子 编译
量子位 出品

TensorFlow 2.0有一个很友好的地方,就是提供了多种不同的抽象方式,可以根据自己的需求来选择。这些API分成两种风格:
一是符号式 (Symbolic) ,通过操作分层图来搭建模型。
二是命令式 (Imperative) ,通过扩展一个类别来搭建模型。
TensorFlow官方发布了博客,详解了两种风格各有怎样的优点缺点,适合在怎样的情况下应用。
符号式API:易用,易Debug
我们设想一个神经网络的时候,通常会把心智模型 (Mental Models) 用这样的分层图(Graph of Layers) 来表示:
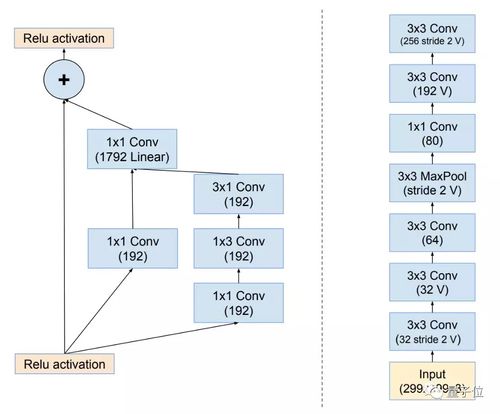
Inception-ResNet的两种表达方式
图可以是有向无环图 (DAG) ,就像图左;也可以是堆栈图 (Stack) ,就像图右。
我们用符号来搭建模型的时候,就需要描述图上的结构。
听起来很陌生?其实只要用过Keras,你应该也做过这样的事。这里有一个简单的示例,借助Keras Squential API,用符号来搭建模型:
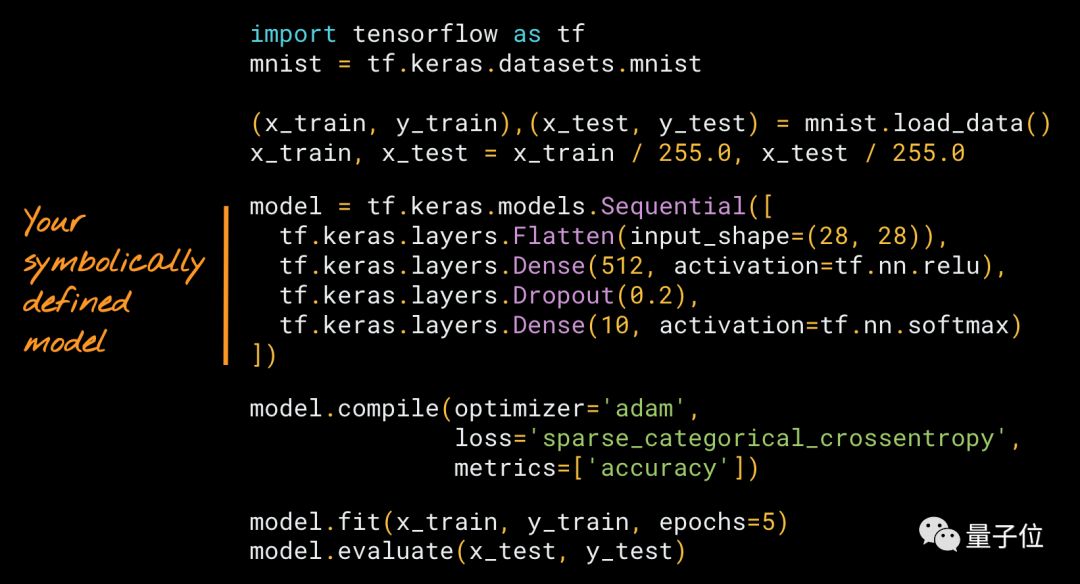
这个例子里面,定义了一个堆栈 (a Stack of Layers) ,然后用一个内置的loop来训练它,model.fit。
用Keras来搭建模型,就像把一块一块乐高插到一起一样。为什么这样讲?除了匹配心智模型 (Mental Model) ,这样搭起来的模型还很容易debug。
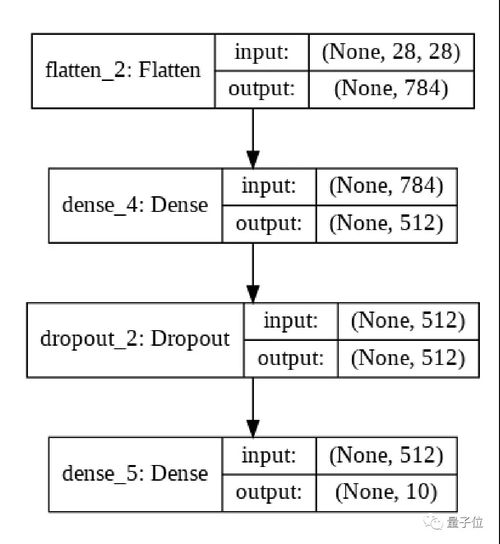
用上文代码搭建的模型,就长这样
TensorFlow 2.0还提供了另一种符号式API,叫Keras Functional。
Sequential是给堆栈图用的API,Functional是给DAG用的API。
用Functional搭建的,多输入多输出模型
Functional API可以用来搭建更灵活的模型。它能搞定非线性拓扑、拥有共享层的模型,、以及拥有多重输入、输出的模型。
简单来说,Functional API就是一组工具,用来生成这些分层图。
优点
这里,模型会有一个类似图形的数据结构。这就表示,模型可以被检查 (Inspected) ,可以被汇总 (Summarized) 。
· 可以当它是一张图 (Image) ,来为它作图 (Plot) ,用keras.utils.plot_model;或者简单一点,用model.summary() 看到各种层、权重和形状的描述。
相似地,当把不同的层拼插到一起的时候,库的设计者可以运行非常繁杂的层兼容性检查 (Layer Compatibility Checks) ,在执行之前检查。
· 这跟编译器里面的类型检查 (Type-Checking) 很相似,可以大幅度减少开发者的错误。
· debug活动大多会在模型定义的阶段发生,而不是在执行过程中。你要确保任何编译的模型都能运行。这样可以加快迭代速度,让模型更容易debug。
符号式的模型会提供一个一致 (Consistent) 的API。这样,重复利用和分享就都会简单一些。比如,在迁移学习里,可以访问中间层的神经元,从现有模型里搭建起新的模型:

符号式的模型,是由一个自然且易于复制的数据结构来定义的。
· 比如,Sequential和Functional这两个API都会给你model.get_config(),model.to_json(), model.save(), clone_model(model) ,可以根据数据结构,重新搭建个一样的模型。
缺点
现在的这一代符号式API,最适合有向无环图 (DAG) 的模型开发。其实这样已经可以满足大部分应用了,但还是有一些特殊情况,不适合用这种方式来抽象:
比如,树形循环神经网络 (Tree-RNN) 和递归神经网络 (Recursive Network) 这样的动态网络。
正因如此,TensorFlow才要同时提供命令式API (如Subclassinng)。
而两类API是完全可以互操作的。这样,就可以混合搭配,把一种模型嵌套在另一种模型里。
命令式API:高度灵活,但不易Debug
命令式的方法,需要像写NumPy一样写模型。这就像面向对象的Python开发一样。先举一个子类化模型的例子看看:

用命令式API搭建的,给图像加字幕的模型
从开发者的视角来看,这个方法的工作原理是来扩展一个 (由框架定义的) 模型类别,把层 (Layers) 实例化,然后用命令式的方法写出网络的前向 (Forward Pass) ,反向是自动生成的。
TF 2.0是直接支持Keras Subclassing API (子类化API) 。与Sequential、Functional一样,这个API也是官方推荐的模型开发方式。
虽然,这类方法对TensorFlow来说是新的,但Chainer早在2015年就介绍过了。从那时起,许多框架都用过类似的方法,包括Gluon和PyTorch。
令人惊讶的是,在不同的框架里用这种方法写的代码,看上去都非常相似,甚至分辨不出是哪个框架里的代码。
优点
前向 (Forward Pass) 是用命令式的方法写的,想拿自己的实现,把库中的实现替换掉 (比如替换一层,一个神经元,或者一个损失函数) ,是很容易的。
这种编程的过程非常自然,也是深入了解深度学习基本要点的一个好方法。
· 可以快速地尝试新的想法,对研究人员来说尤其有帮助。
· 在前向里面,可以很容易地指定某个控制流。
命令式的API给了你最大的灵活性,但是是有代价的:
缺点
用命令式API的时候,模型是由某个类别来定义的。这里没有一个很清晰的数据结构,是不透明的字节码 (Bytecode) 。灵活性,是可用性 (Usability) 和重用性 (Reusability) 的牺牲换来的。
Debug发生在执行 (Execution) 过程中,不是在搭建模型的时候。
· 几乎不会对输入或层兼容性做检查,所以Debug的压力从框架上转移到了开发者身上。
命令式的模型,很难重复利用。比如,你是没办法用一个一致的API,去访问中间层或神经元的。
· 所以,要提取神经元,就要写一种新类别,它的调用方法也是新的。开始的时候,可能会觉得有趣又简单,但慢慢就会累积成技术债 (Technical Dept) 。
命令式的模型,也很难检查 (Inspect) ,很难复制 (Copy) ,很难克隆 (Clone) 。
· 比如,model.save(), model.get_config() 以及 clone_model 对子类化的模型是不管用的。而model.summary() 也只会给你列出各种层的列表,不会告诉你它们是怎么相互连接的。
训练Loop
不论是用Squential、Functional还是Subclassing的方法写的模型,都可以用两种方法进行训练。
一种是用内置的训练路径和损失函数来训练,就像上文举的第一个例子那样 (model.fit和model.compile) ;
另外一种,是定制更复杂的Loop和损失函数,可以这样做:
pix2pix训练用的Loop和损失函数
要让两种方法都可用,这一点很重要,还可以轻松地降低代码的复杂程度,降低维护成本。
简单地说,如果增加复杂性有帮助的话,就增加;如果没必要增加复杂性,就用内置的Loop。
总结一下
TF 2.0会直接支持符号式API和命令式API,所以可以自由选择。
如果,你的目标是易用性、低预算,而且你习惯把模型想成分层图;就用Sequential和Functional这样的符号式API,以及拿内置的Loop来训练。这样的方法适用大多数问题。
如果,你习惯把模型想成面向对象的Python开发者,并且优先考虑模型的灵活性和可破解性;Subclassing这样的命令式API就很适合你了。
关于TensorFlow 2.0
今年1月,谷歌放出了TensorFlow 2.0的一个Nightly版本,以供开发者尝鲜。
官方表示,2.0会更加注重简单性和易用性,主要更新如下:
· 使用 Keras 和 eager execution,轻松构建模型
· 在任意平台上实现生产环境的稳健模型部署
· 为研究提供强大的实验工具
· 通过清理废弃API和减少重复来简化API
虽然,正式版还没有发布,但已经有人早早发布了用TensorFlow做深度学习的入门教程,并被TF官推翻了牌。
你要不要去看看?
正文博客原文传送门:
https://medium.com/tensorflow/what-are-symbolic-and-imperative-apis-in-tensorflow-2-0-dfccecb01021
深度学习教程传送门:
https://mp.weixin.qq.com/s/FhK1qfT5m9gTjTUlm9471Q
— 完 —





