
在现有的所有互联网招聘网站上,岗位信息里的所有条目都是在同一级标签下。因此,岗位信息作为一个整体,就需要额外的操作把要求与职责分离开。鉴于岗位信息里数据格式的不统一,因此博主放弃了使用正则表达式的方法,而是选择了模糊匹配+结构化匹配,将字符串比较的问题转化成了概率问题。
一、数据存储结构
在之前写的爬虫里,岗位信息一栏使用Xpath的String()方法抓取,作为一个大的字符串,所有信息都位于一个单元格中。现在计划在爬虫运行时,得到岗位信息后就将其分离,再写入硬盘中。所以,爬取数据时的格式会极大的影响分离的方法,字符串适合使用正则表达式,但是在格式混乱的岗位信息中,这显然不是完美的解法,如'岗位职责',与之类似的还有'工作内容','职位描述'等等,这些词的各种排列组合会极大的增加正则表达式的长度。
所以我决定将每一行信息都转化为数组的一个元素,再通过上下文信息与其自身的词汇信息判断其归属。在我爬取的51job移动端中,岗位信息的条目都在标签<article>下,因此使用//text()方法,将<article>标签下每一行的信息都转化为一个数组元素。
info = selector.xpath('//*[@id="pageContent"]/div[3]/div[2]/article//text()')

图表 1 数据在源码中的位置
二、数据的上下文关系
上图所示的数据格式是最完美的,只需要正则表达式就能匹配成功。每一条数据都含有信息,'岗位职责'与'岗位要求'预示下文的数据与这个主题相关,其余信息则属于某一个主题。所以对这类结构化非常明显的信息,只需要匹配出'职责'与'要求'即可完成数据的分离。
另一种情况如下所示,职位描述里包含了一眼就能看出来的岗位职责与要求,但是职责头信息缺失,通过上下文无法得出该信息的归属。因此,对于这类上下文无关的信息,就需要单独进行处理。

图表 2 缺少主题的jd
通过上述分析,就得出了这样一个处理流程:如果现在处理的信息属于头部信息(职责、要求等),则进入结构化处理流程,否则单独处理。
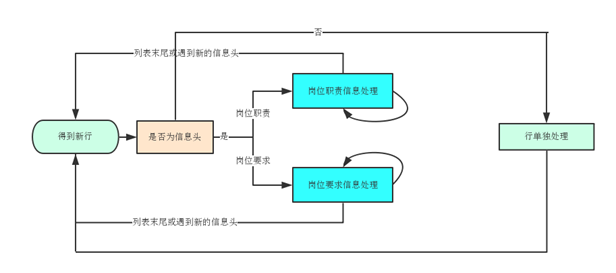
图表 3 流程图
三、模糊匹配
由于对相同意思的不同表述,以及输入过程中可能会出现的错误,因此使用模糊匹配来近似地查找与字符串匹配的字串。
字符串模糊匹配( fuzzy string matching)是一种近似地(而不是精确地)查找与模式匹配的字符串的技术。换句话说,字符串模糊匹配是一种搜索,即使用户拼错单词或只输入部分单词进行搜索,也能够找到匹配项。因此,它也被称为字符串近似匹配。
先导入第三方库fuzzywuzzy:
from fuzzywuzzy import fuzz
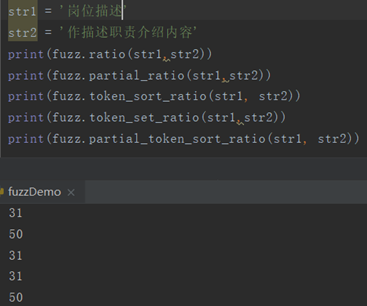
fuzz有五个常用的函数,先做一个简单的测试来看看区别。

函数功能就像它们的名称一样,通俗易懂。再换一个长一点儿的:

所以我选择partial_token_sort_ratio()的值作为判断的依据。
通过分析ratio函数的源码,可以发现ratio()函数的求值公式:

M是匹配的元素个数,T是字符串长度。所以针对partial的函数,我们可以用2/(len(thisStr))*100来判断字符串是否满足模糊匹配。
另外有一个小问题,

后来发现,str2 = 'word1word2word3'时,word1出现在str1中,则匹配失败。所以在str2前加入一个字,取'工作'后一字,则解决问题。
四、模糊匹配自定义数据集
正如正则表达式需要自己定义匹配的字符一样,模糊匹配也需要自己定义一个类似的字符集。我们总共需要四个字符集,分别是岗位要求与职责头的字符集,以及具体要求的字符集。
str_responsibility = '作职责描述介绍内容'
str_requirement = '能力要求需求资格条件标准'
str_line_res = '负责基于构建根据制定规范需求'
str_line_req = '经验熟悉熟练掌握精通优先学历专业以上基础知识学习交流年龄编程了解'
五、代码实现
函数parse()作为信息处理的入口,接收一个含有岗位信息的数组,返回一个数组,数组元素分别是岗位职责与要求。
由于爬取的信息含有大量制表符与空字符,所以需要排除无效的信息,并用一个新的数组'ls_jd'存储岗位信息。
def parse(ls):
if len(ls) == 0:
return ['null','null']
ls_jd = []
result_res = []
result_req = []
str_responsibility = '作职责描述介绍内容'
str_requirement = '能力要求需求资格条件标准'
for i in range(len(ls)):
str_line = str(ls[i]).strip()
if len(str_line.strip()) < 2:
continue
else:
ls_jd.append(str_line)
再声明一个变量Index,用来记录现在读取到数组元素的下标。
使用一个循环,从第一个元素开始,依次读取数组元素,并求得其与'岗位职责'字串、'岗位要求'字串的相似度,再分别进行匹配。
另外,由于需要对循环元素进行操作,所以不能使用for循环,因此此处使用了while()。
index = 0
while int(index) < len(ls_jd):
str_line = ls_jd[index]
if len(str_line) < 10:
fuzz_res = fuzz.partial_token_sort_ratio(str_line, str_responsibility)
fuzz_req = fuzz.partial_token_sort_ratio(str_line, str_requirement)
else:
parse_line(str_line,result_res,result_req)
index += 1
continue
if fuzz_res > fuzz_req and fuzz_res >= (2/len(str_responsibility)*100):
index = parse_res(index,ls_jd,str_requirement,result_res)
elif fuzz_req > fuzz_res and fuzz_req >= (2/len(str_requirement)*100):
index = parse_req(index,ls_jd,str_responsibility,result_req)
else:
print('warn: '+ str_line)
index += 1
基于结构的信息提取会修改当前读取数组的下标,所以需要将当前函数内读取到的下标返回。参数里传列表,实际上传的是地址,所以结果不需要额外操作。
def parse_res(index,ls,str_break,result_res):
# print('岗位职责()Start')
while index < len(ls)-1:
index += 1
fuzz_break = fuzz.partial_token_sort_ratio(ls[index], str_break)
if fuzz_break < 49:
result_res.append(ls[index])
else:
return index-1
return index
def parse_req(index,ls,str_break,result_req):
# print('岗位要求()Start')
while index < len(ls)-1:
index += 1
fuzz_break = fuzz.partial_token_sort_ratio(ls[index], str_break)
if fuzz_break < 49:
result_req.append(ls[index])
else:
return index-1
return index
def parse_line(line,result_res,result_req):
str_res = '负责基于构建根据制定规范需求'
str_req = '经验熟悉熟练掌握精通优先学历专业以上基础知识学习交流年龄编程了解'
fuzz_res = fuzz.partial_token_sort_ratio(line, str_res)
fuzz_req = fuzz.partial_token_sort_ratio(line, str_req)
if fuzz_res-1 >= (2/len(str_res)*100):
result_res.append(line)
elif fuzz_req-1 >= (2/len(str_req)*100):
result_req.append(line)
六、结果

可以看出还是有一些小问题的。
七、改进与设想
基于概率匹配的信息分解受制于自定义匹配数据的完整性,尽管目前给出的几个关键词囊括了大部分的情况,不过仍然有相当多的漏网之鱼。
另外,fuzz库的模糊匹配并不能完美适配此次字符匹配,除了第三大点后给出的问题外,对长句中不同词语应该有不同的权重,以避免长居中词太多导致匹配失败。
不过最可喜的应该是,这次有了相对统一的数据,回头可以用这些数据去Spark上跑个模型,亲自操刀一下机器学习了,哈哈哈。
原文出处:https://www.cnblogs.com/magicxyx/p/10339702.html
作者:Magic激流





