
始终紧跟Javascript(ECMAScript)的最新功能是很难的,更难的是找到有用的代码示例。
因此,在本文中,我将介绍在TC39的最终提案中包含的18个功能,这些功能将被添加到ES2016, ES2017, and ES2018 (最终草案)中,并通过有实际用处的示例来展示它们。
这是一篇非常长的贴子,但应该非常容易阅读。把它当作“Netflix狂欢阅读” 读完之后,我保证你将掌握大量有关这些功能的知识。
让我们一个一个地看看这些新功能

1. Array.prototype.includes
includes是Array实例上一个非常简的方法,可以非常容易查找到某一项是否在Array中(包括 NaN 而不像 indexOf不能查找NaN)。

花絮:JavaScript规范制定者想将它命名为
contains,但是这个名字已经明确地被Mootools用了,所他们使用includes。
2. 指数 运算符
数学运算如加法和减法分别有+和- 等中缀运算符。与他们类似,**中缀运算符通常用于指数运算。在ECMAScript 2016中,引入了**来代替Math.pow。


1. Object.values()
Object.values()是一个类似于Object.keys()的新函数,它返回对象自有属性的所有值,而不包括原型链上的任何值。

2. Object.entries()
Object.entries()与Object.keys有关,但不仅仅返回键,而是以数组的形式返回键和值。这使得在循环中使用对象,或将对象转到Maps等变得非常简单。
示例 1:

示例 2:

3. 字符串填充
String新增了两个实例谢谢老婆---String.prototype.padStart 和 String.prototype.padEnd ,它们允许在原始字符串的开始和结尾处添加空字符串或者是其它的字符串。
'someString'.padStart(字符串的总长度 [,填充字符串]);
'5'.padStart(10) // '5' '5'.padStart(10, '=*') //'=*=*=*=*=5'
'5'.padEnd(10) // '5 ''5'.padEnd(10, '=*') //'5=*=*=*=*='
当我们想要漂亮的打印显示或终端打印等场景中对齐输出时,将变得的很方便。
3.1 padStart 示例:
在下面的示例中,有一些不同长度的数字,我们想在它们前面填充“0”,以便所有的项目都将以10位的相同长度用于显示。我们可以使用padStart(10, '0')很容易的实现。

3.2 padEnd 示例:
当我们想右对齐打印多个不同长度的项目时,使用padEnd就非常方便了。
下面是一个非常好实例,它展示了padEnd 、padStart 和 Object.entries如何结合使用产生一个漂亮的输出。

const cars = { 'BMW': '10', 'Tesla': '5', 'Lamborghini': '0'}Object.entries(cars).map(([name, count]) =>{ //padEnd appends '-' until the name becomes 20 characters
//padStart prepends '0' until the count becomes 3 characters.
console.log(`${name.padEnd(20, '-')} Count: ${count.padStart(3, '0')}`)
});//Prints..// BMW - - - - - - - Count: 010// Tesla - - - - - - Count: 005// Lamborghini - - - Count: 000
3.3 Emojis和其他双字节字符上的padStart和padEnd
Emojis和其它双字节字符串使用unicode的多字节表示。所以padStart和padEnd可能无法按照预期的工作。
例如:假设我们尝试用 表示符号填充字符中heart到10个字符,结果如下所示:
//Notice that instead of 5 hearts, there are only 2 hearts and 1 heart that looks odd!'heart'.padStart(10, "");// prints.. 'heart'
这是因为 是2个码长('\u2764\uFE0F')!单词heart是5个字符,所以我仅剩下5个字符用于填充。所以最终JS使用'\u2764\uFE0F'填充了两个心型。最一个的产生是因为JS仅使用了第一个字节\u2764。
所以最后输出: heart
PS:你可通过这个链接查看unicode字符转换。
4. Object.getOwnPropertyDescriptors
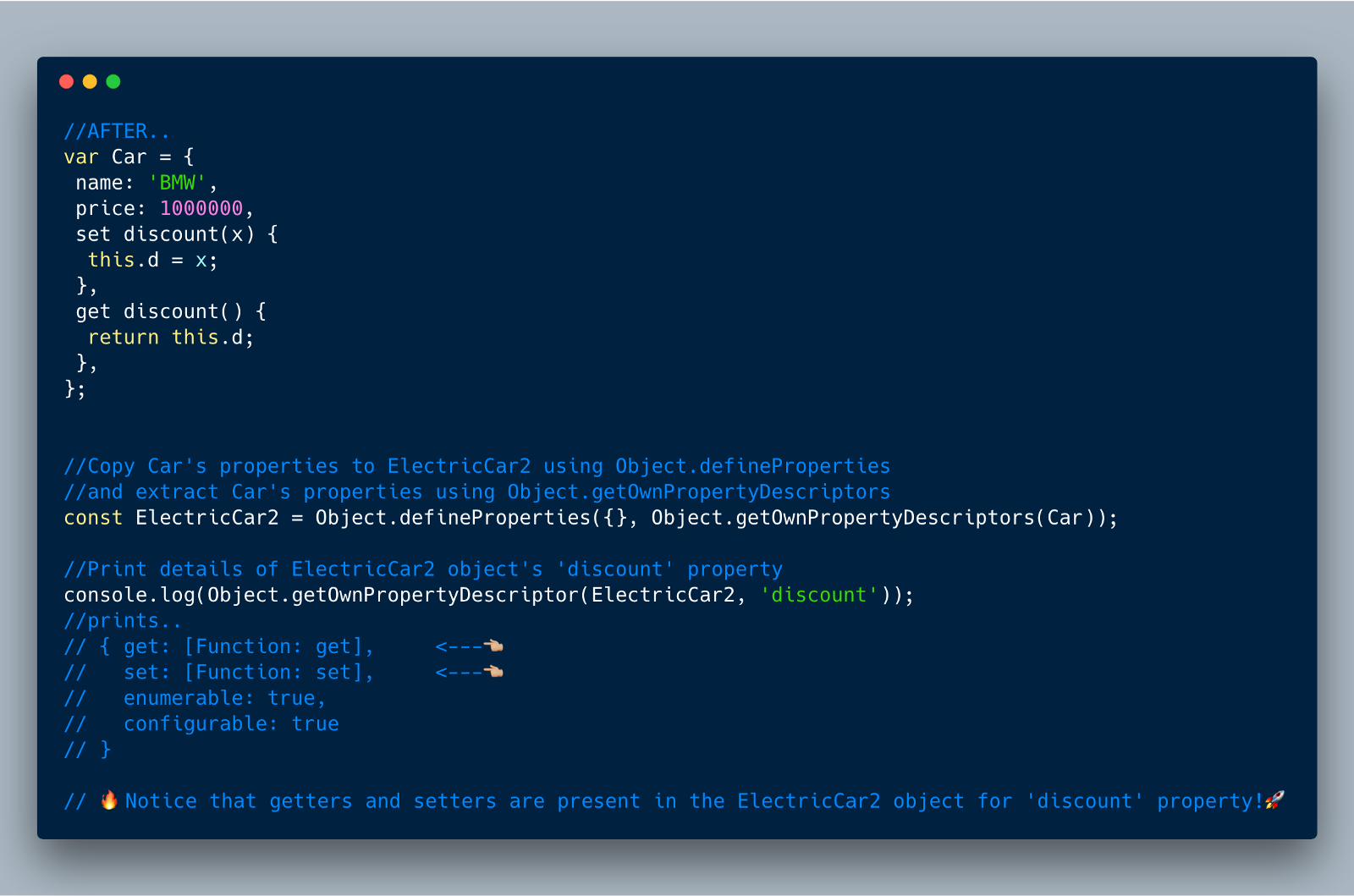
这个方法返回一个对象的所有属性的详细信息(包括get和set方法)。添加这个方法的主要目的是允许浅拷贝/克隆一个对象,包括对象上的getter和setter函数,不同于Object.assign。
Object.assign 允许浅复制源对象上的所有属性的详细信息,除getter和setter函数外。
下面的示例通过拷贝一个原始对象Car到一个新对象ElectricCar,来展示Object.assign和Object.getOwnPropertyDescriptors以及Object.defineProperties之间的区别。你会发现使用Object.getOwnPropertyDescriptors,discount的getter和setter函数同样被拷贝到目标对象。
之前... ...

之后… ...
var Car = {
name: 'BMW',
price: 1000000, set discount(x) { this.d = x;
}, get discount() { return this.d;
},
};//Print details of Car object's 'discount' property
console.log(Object.getOwnPropertyDescriptor(Car, 'discount'));//prints..// {
// get: [Function: get],// set: [Function: set],// enumerable: true,// configurable: true// }//Copy Car's properties to ElectricCar using Object.assignconst ElectricCar = Object.assign({}, Car);//Print details of ElectricCar object's 'discount' propertyconsole.log(Object.getOwnPropertyDescriptor(ElectricCar, 'discount'));//prints..// { // value: undefined,// writable: true,// enumerable: true,// configurable: true // }//Notice that getters and setters are missing in ElectricCar object for 'discount' property !//Copy Car's properties to ElectricCar2 using Object.defineProperties
//and extract Car's properties using Object.getOwnPropertyDescriptors
const ElectricCar2 = Object.defineProperties({}, Object.getOwnPropertyDescriptors(Car));//Print details of ElectricCar2 object's 'discount'propertyconsole.log(Object.getOwnPropertyDescriptor(ElectricCar2, 'discount'));//prints..// { get: [Function: get], // set: [Function: set], // enumerable: true,// configurable: true // }// Notice that getters and setters are present in the ElectricCar2 object for 'discount' property!5. 在函数参数中添加尾随逗号
这是一个小的更新,它允许我们在函数最后一个参数的后面添加尾随逗号。为什么这么做?它可以帮助像git blame这样的工具确认所有的责任都是新的开发者引起的。
下面的示例说明这个问题和解决方法。

注意:你可以尾随逗号来调用函数。
6. Async/Await
如果你问我,我会说这个迄今为止最重要也是最有用的功能。异步函数允许们再也不用处理回调地狱,同时使用整个代码看起来很简单。
async关键字告诉JavaScript编译器,以不同的方式处理这个函数。在函数内执行到await关键字时,编译器将会暂停。它假设在等待之后的表达式返回一个承诺,并等待承诺解决或拒绝后继续执行。
在这个示例中,getAmount函数将调用两个异步的函数getUser 和 getBankBalance。我们可以通过Promise实现,但使用async await会更加的优雅和简单。.

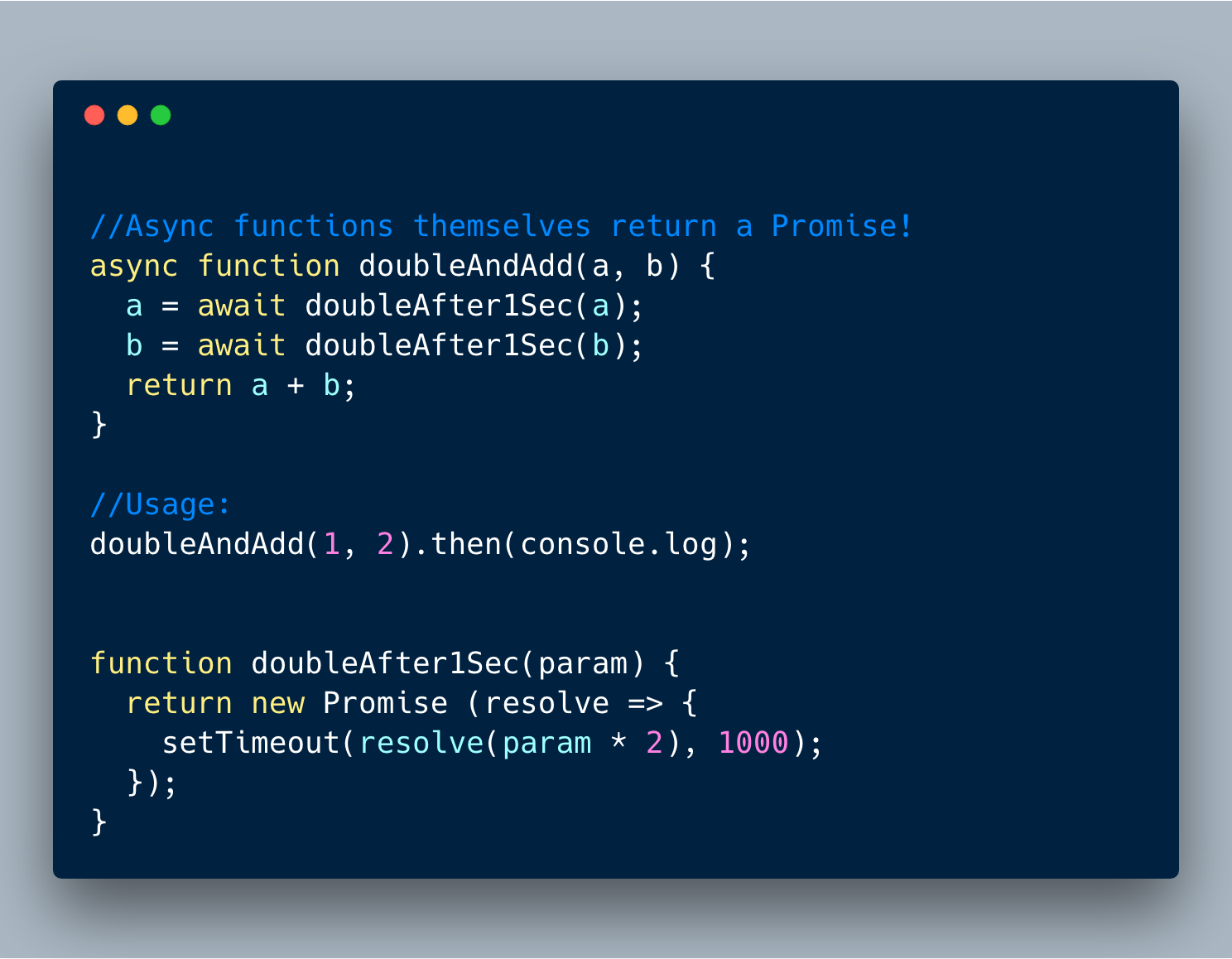
6.1 异步函数本身返回一个Promise.
如果你想等待一个异步函数的返回结果,你需要你需要使用Promise’s then语法来捕获返回结果。
在下面的示例中,我们想通过console.log来打印返回结果,而不是在doubleAndAdd函数内部。所以我们想等函数返回结果并通过then语法将结果传递给console.log 。
6.2 并行调用async/await
在上一个示例中,我们调用了两次await语句,每一次等待1s(共2s)。In the previous example we are calling await twice, but each time we are waiting for one second (total 2 seconds). 相反,我们可以使用Promise.all并行执行两次调用,因为a和b。

6.3 async/await函数的错误处理
使用async await时,有各种方法来处理错误。
选项 1 —在函数中使用try catch

//Option 1 - Use try catch within the functionasync function doubleAndAdd(a, b) { try {
a = await doubleAfter1Sec(a);
b = await doubleAfter1Sec(b);
} catch (e) { return NaN;//return something
}return a + b;
}//Usage:doubleAndAdd('one', 2).then(console.log);// NaNdoubleAndAdd(1, 2).then(console.log);// 6function doubleAfter1Sec(param) { return new Promise((resolve, reject) =>{
setTimeout(function() { let val = param * 2; isNaN(val) ? reject(NaN) : resolve(val);
}, 1000);
});
}Option 2— 捕获每个一个 await 表达式
因为每一个await表达式都返回一个Promise,你可以像下面展示在每一行上捕获错误。
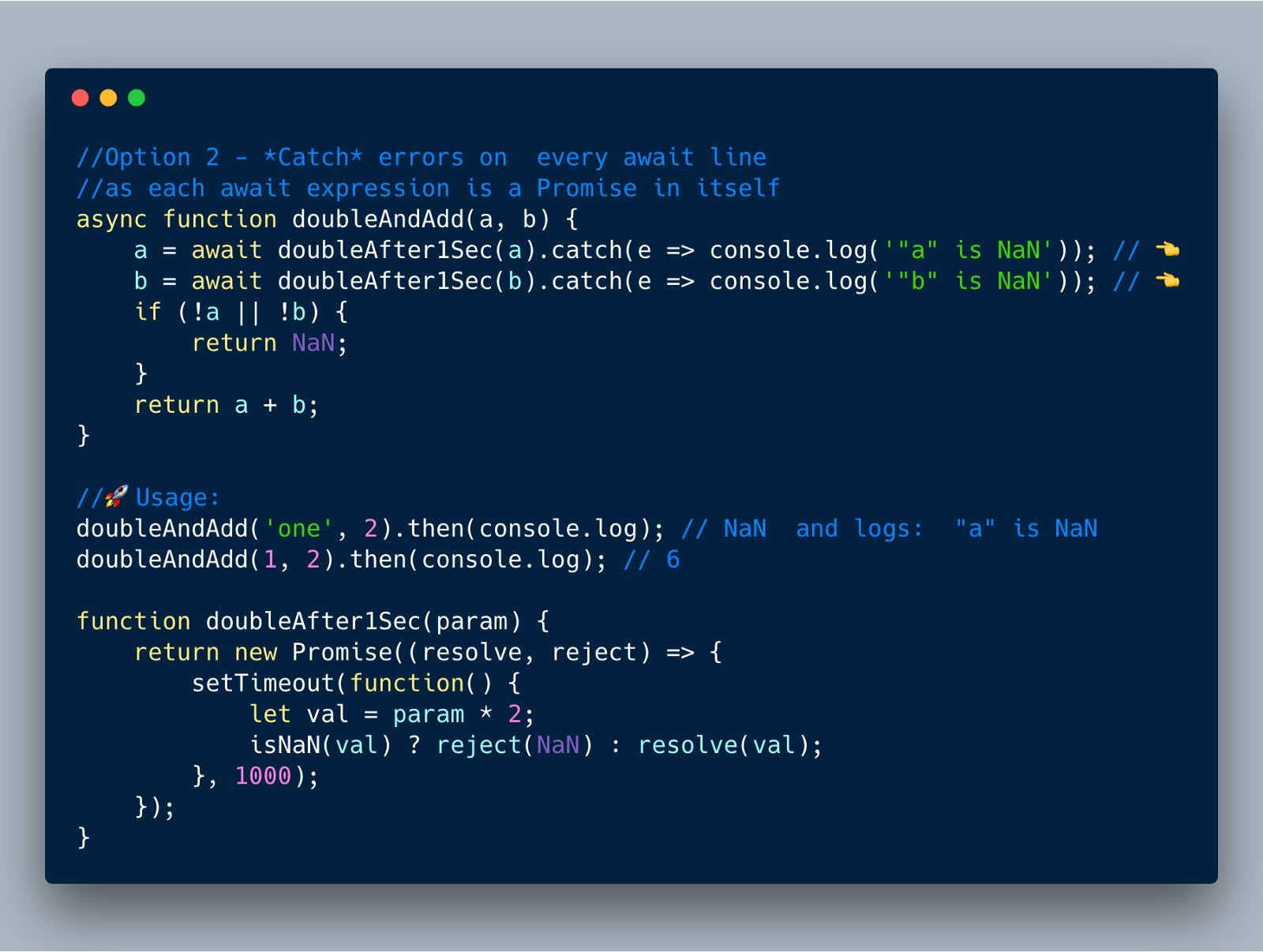
//Option 2 - *Catch* errors on every await line//as each await expression is a Promise in itselfasync function doubleAndAdd(a, b) {
a = await doubleAfter1Sec(a).catch(e => console.log('"a" is NaN')); //
b = await doubleAfter1Sec(b).catch(e => console.log('"b" is NaN')); //
if (!a || !b) { return NaN;
} return a + b;
}//Usage:doubleAndAdd('one', 2).then(console.log);// NaN and logs: "a" is NaNdoubleAndAdd(1, 2).then(console.log);// 6function doubleAfter1Sec(param) { return new Promise((resolve, reject) =>{
setTimeout(function() { let val = param * 2; isNaN(val) ? reject(NaN) : resolve(val);
}, 1000);
});
}Option 3 — 捕获整个 async-await 函数

//Option 3 - Dont do anything but handle outside the function//since async / await returns a promise, we can catch the whole function's errorasync function doubleAndAdd(a, b) {
a = await doubleAfter1Sec(a);
b = await doubleAfter1Sec(b); return a + b;
}//Usage:doubleAndAdd('one', 2)
.then(console.log)
.catch(console.log); // `<------- use "catch"function doubleAfter1Sec(param) { return new Promise((resolve, reject) =>`{
setTimeout(function() { let val = param * 2; isNaN(val) ? reject(NaN) : resolve(val);
}, 1000);
});
}
ECMAScript目前正在最张草案中,将于2018年6月或7月发布。 is currently in final draft and will be out in June or July 2018. 下文函数的所有功能都将在Stage-4中,并将成为ECMAScript 2018的一部分。
1. 共享内存和原子
这是一个伟大的、非常先进的功能,是对JS引擎的核心增强。
它的主要思想是想为JS提供一些多线程的功能,以便JS开发人员可以自己管理内存(代替JS引擎对内存的管理)来编写高性能的并发程序。
这是通过一种叫做SharedArrayBuffer的全局对象来实现的,它实质上是将数据存储在_共享_ 内存空间中。所以这个数据可以在JS主线程和web-worker之间共享。
到现在为止,如果我们想在JS主线程和web-workers之间共享数据,只能先复制数据然后使用postMessage 发送到其它线程。
现在,只需要使用SharedArrayBuffer,主线程和多个web工作线程即可访问共享数据。
但是在线程之间共享内存会引发竞争条件的产生。为了防止条件的产生引入了“Atomics”全局对象。 当一个线程正在使用它的数据时,Atomics 提供了各种方法来锁定共享内存。 它还提供了安全地更新共享内存中的数据的方法。
建议通过某些库来使用这些功能,但是现在还没有构建在此功能上的库。
如果你有兴趣,推荐阅读:
2. 删除标签模板字符的限制
首先,我们要弄清楚“Tagged Template literal”是什么,这样我们才能更好的理解这个特性。
在ES2015+中,有一个叫标签模板的功能,它允许开发人员自定义如何插入字符串。例如,以标签方式插入字符串,如下所示... ...

在标签中,可以写一个函数来接收字符串常量部分,如[ ‘Hello ‘, ‘!’ ]和要替换的变量,如[ 'Raja'], 把它们作为参数传入自定义的函数(如greet),然后从这个自定义的函数中返回任何所需要的内容。
下面的示例展示了我们自定义的标签函数greet给某个时间附加如“Good Morning!”、“Good afternoon”这些字符串,取决于某个具体的时间并返回一个自定义的字符串。
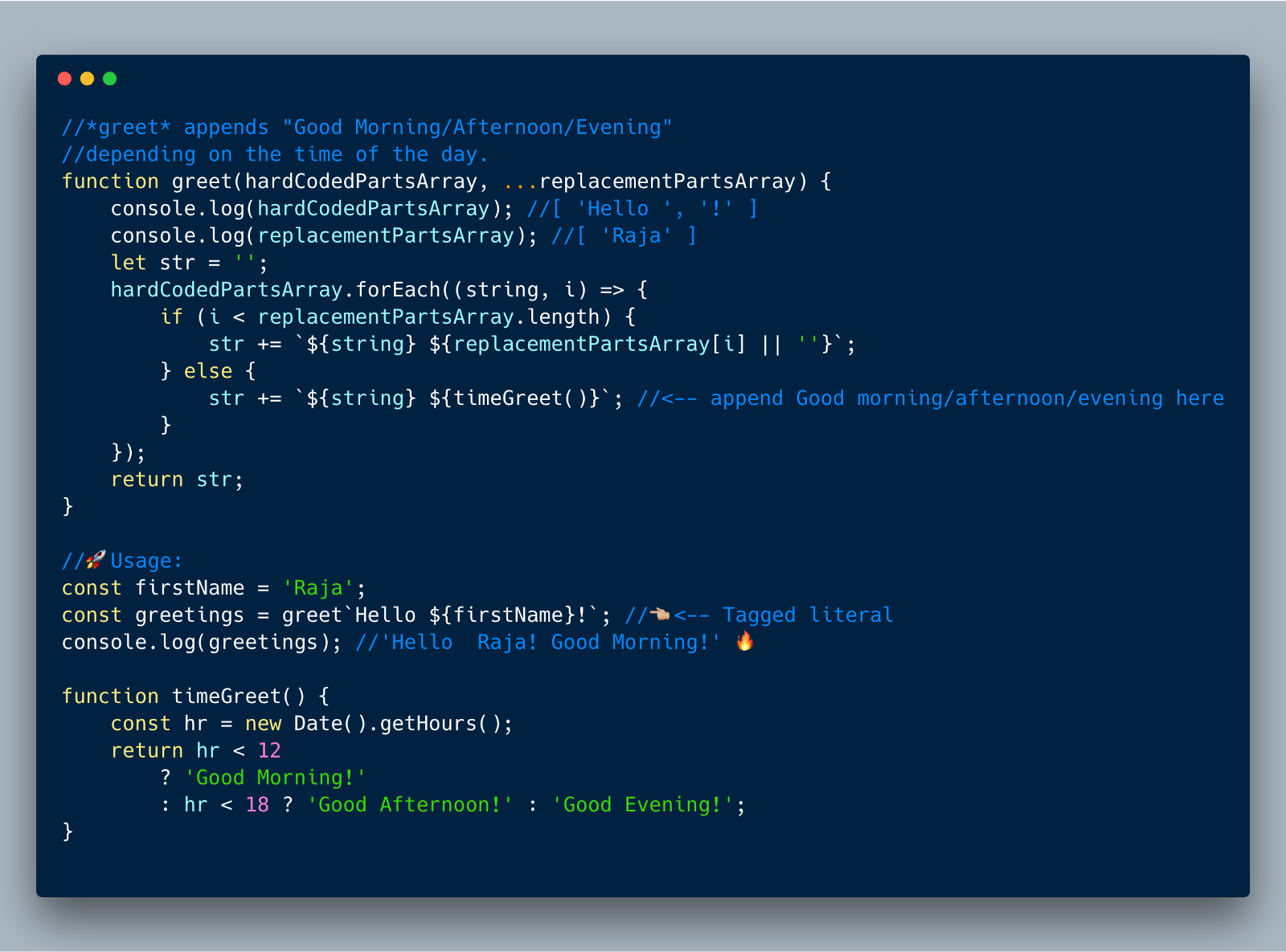
//A "Tag" function returns a custom string literal. //In this example, greet calls timeGreet() to append Good //Morning/Afternoon/Evening depending on the time of the day.
function greet(hardCodedPartsArray, ...replacementPartsArray) {
console.log(hardCodedPartsArray);//[ 'Hello ', '!' ]
console.log(replacementPartsArray);//[ 'Raja' ]let str = '';
hardCodedPartsArray.forEach((string, i) =>{ if (i < replacementPartsArray.length) {
str += `${string} ${replacementPartsArray[i] || ''}`;
} else {
str += `${string} ${timeGreet()}`;//<-- append Good morning/afternoon/evening here
}
}); return str;
}//Usage:const firstName = 'Raja';const greetings = greet`Hello ${firstName}!`;//<-- Tagged literalconsole.log(greetings);//'Hello Raja! Good Morning!'
function timeGreet() { const hr = new Date().getHours(); return hr < 12
? 'Good Morning!'
: hr < 18
? 'Good Afternoon!'
: 'Good Evening!';
}现在我们讨论被当作标识名的函数到底是什么,许多人希望在不同的场景中使用这个功能,例如在终端命令和HTTP请求的URI构成中,等。
The problem with Tagged String literal
问题是在ES2015和ES2016规范中不允许使用“\u” (unicode),“\x”(hexadecimal) 等转义字符,除非它们看起来完全像\\u00A9 或 \u{2F804} 或 \xA9。
因此,如果你在一个标记函数内使用其它域的规则(如终端规则),那么可能需要使用\ubla123abla这种规则,它看起来不像\u0049 或 \u{@F804},然后你将会得到一个语法错误。
在ES2018中,使用规则是非常宽松的,甚至无效的转义字符。只要标记函数通过对象返回属性值,如“cooked”(无效字符串是“undefined”)和“raw”(包括任何其它你想要的属性)。
function myTagFunc(str) {
return { "cooked": "undefined", "raw": str.raw[0] }
}
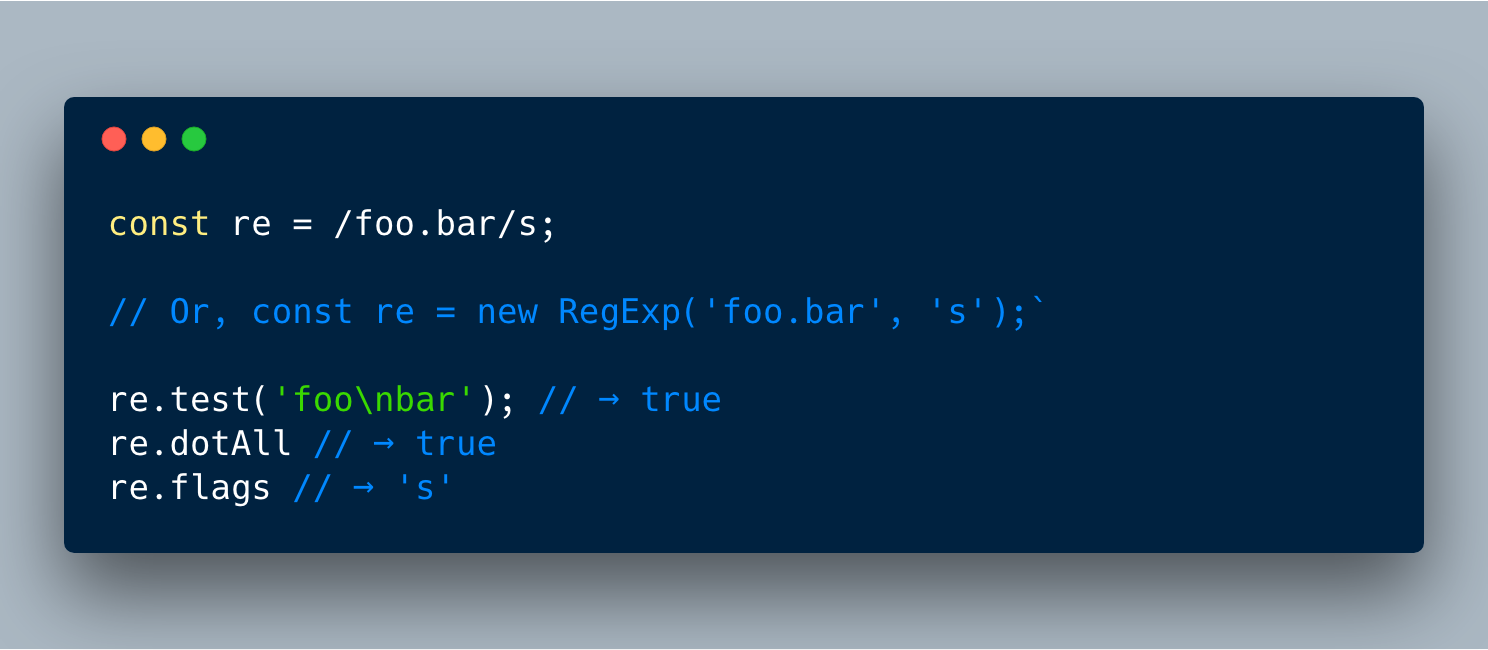
var str = myTagFunc `hi \3. 正则表达式的“dotall”标志
在现在的RegEx中,尽管(“.”)应该匹配单个字符,便它不匹配会产生新的字符,像\n \r \f等。
例如:
//Before/first.second/.test('first\nsecond');//false这个增强的功能可以使点运算符匹配任何单符。为了确保不破坏任何内容,我们需要使用\s标记来创建RegEx表示以使其能正常工作。
//ECMAScript 2018/first.second/s.test('first\nsecond');//true Notice: /s 以下是提案 文档中的全部API:
4. RegEx命名的组捕获
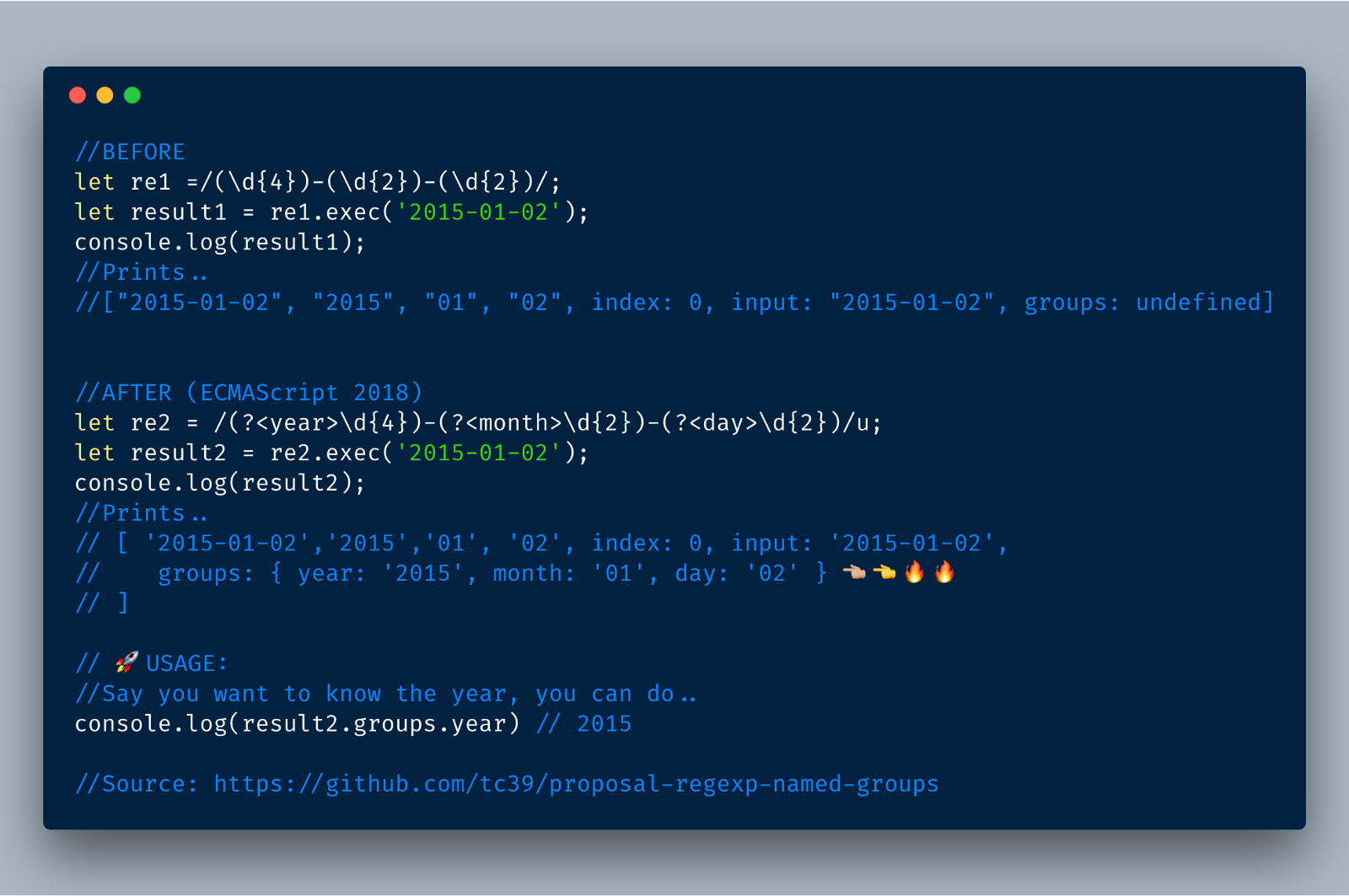
这个增强的功能模仿其它语言,如Python,Java等中带来一个非常有用的特性叫“命名组”。此特性允许开发人员编写RegExp时,为RegExp中的组的不同部分提供格式为“(<name>...)”的名称(标识符)。 然后,他们可以使用该名称轻松获取他们需要的任何组。
4.1 基本的命名组示例
在下面的示例中,我们使用(?<year>) (?<month>) and (?year)名称对日期RegEx的不同部分进行分组。 结果对象现在将包含一个具groups属性,它有year,month和year属性及相应的值。
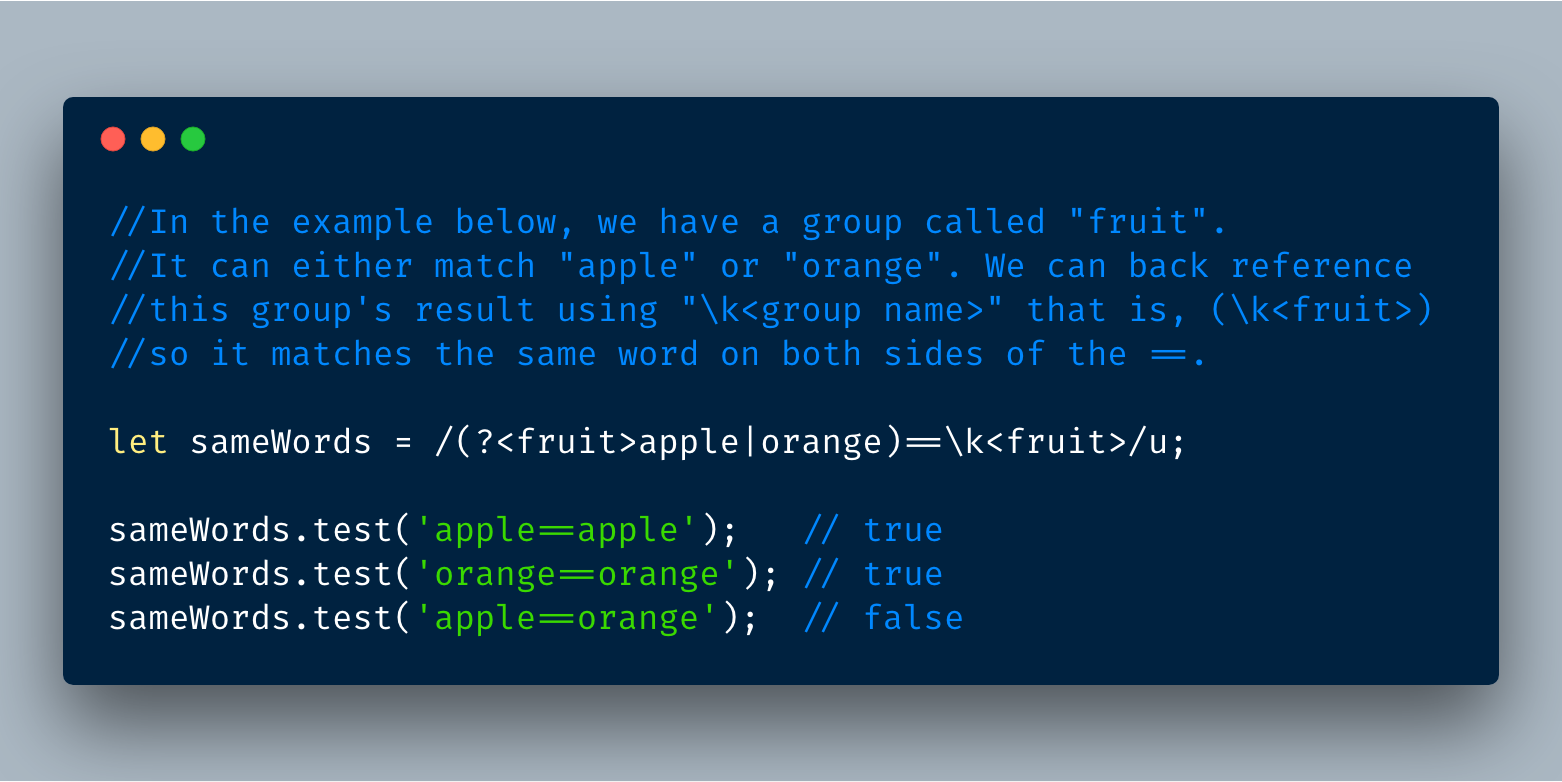
4.2 在正则表达式本身内使用命名组
我们可以使用\k <组名>这种格式在正则表达式本身反向引用该组。 下面的例子展示它的工作原理:
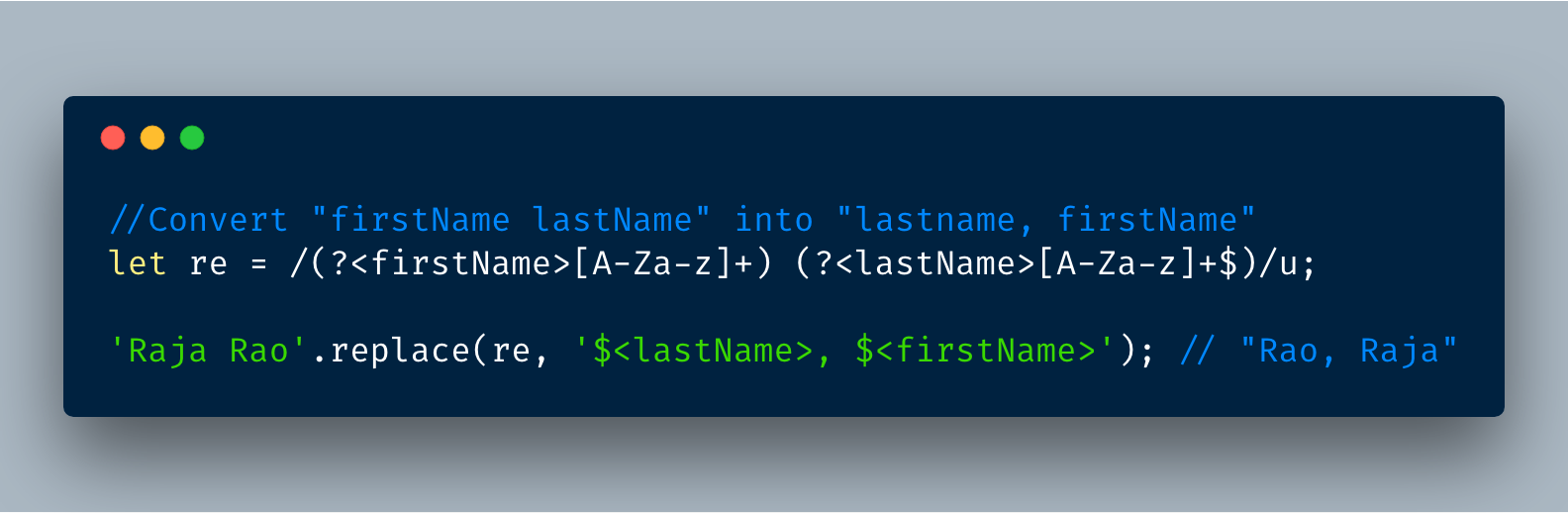
4.3 在String.prototype.replace中使用命名组
现在,命名组这个特性已经可以在字符串的实例方法replace中使用了,所以我们可以很容易地替换字符串的单词。
例如,把“firstName, lastName”替换成“lastName, firstName”。
5. 对象的解构属性
解构操作符 ... (三个...)允许我们提取对象中沿未提取的属性。
5.1 你可以使用解构来只提取你想要的属性
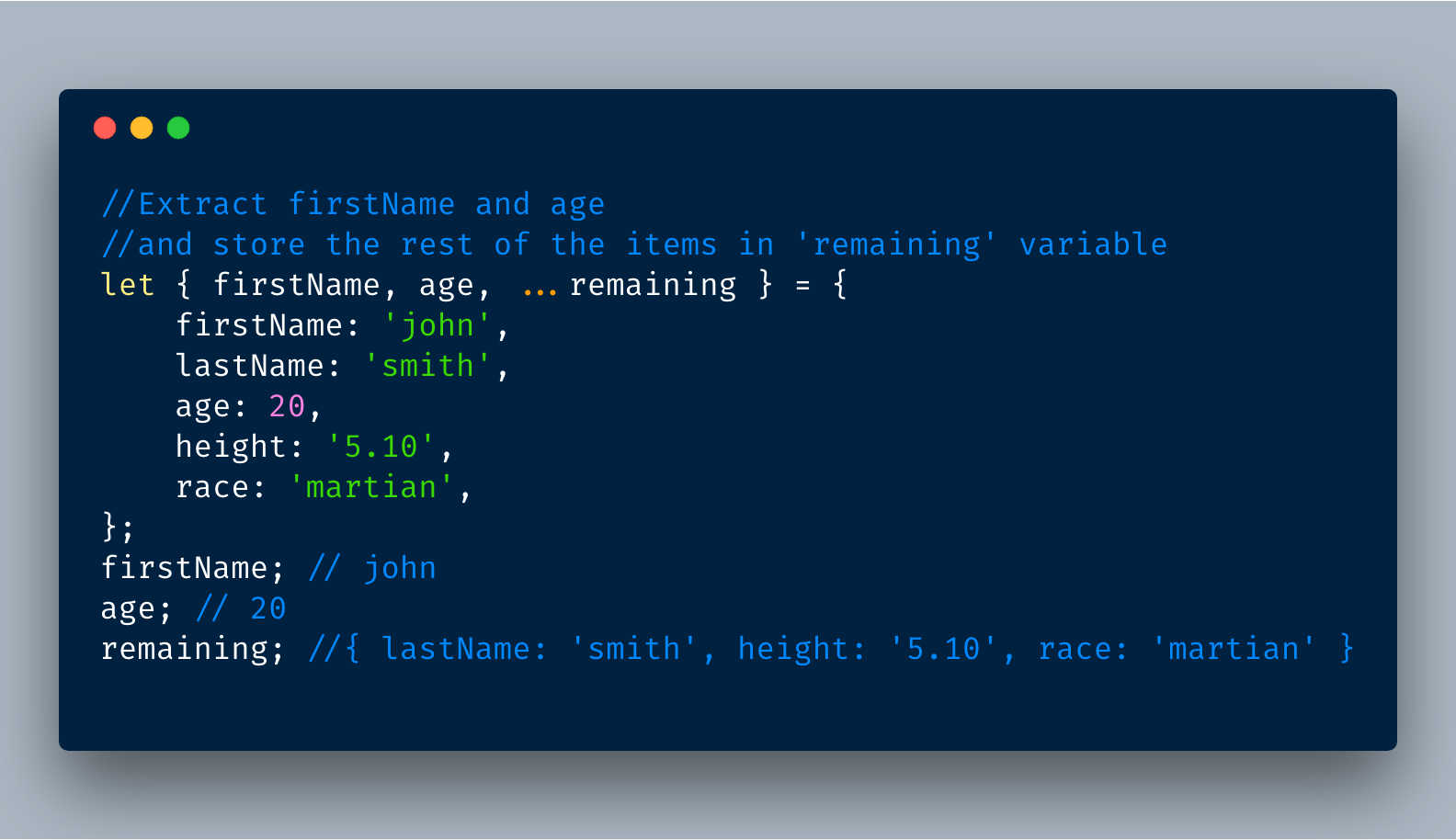
5.2 更方便的是你可以删除你不想要的属
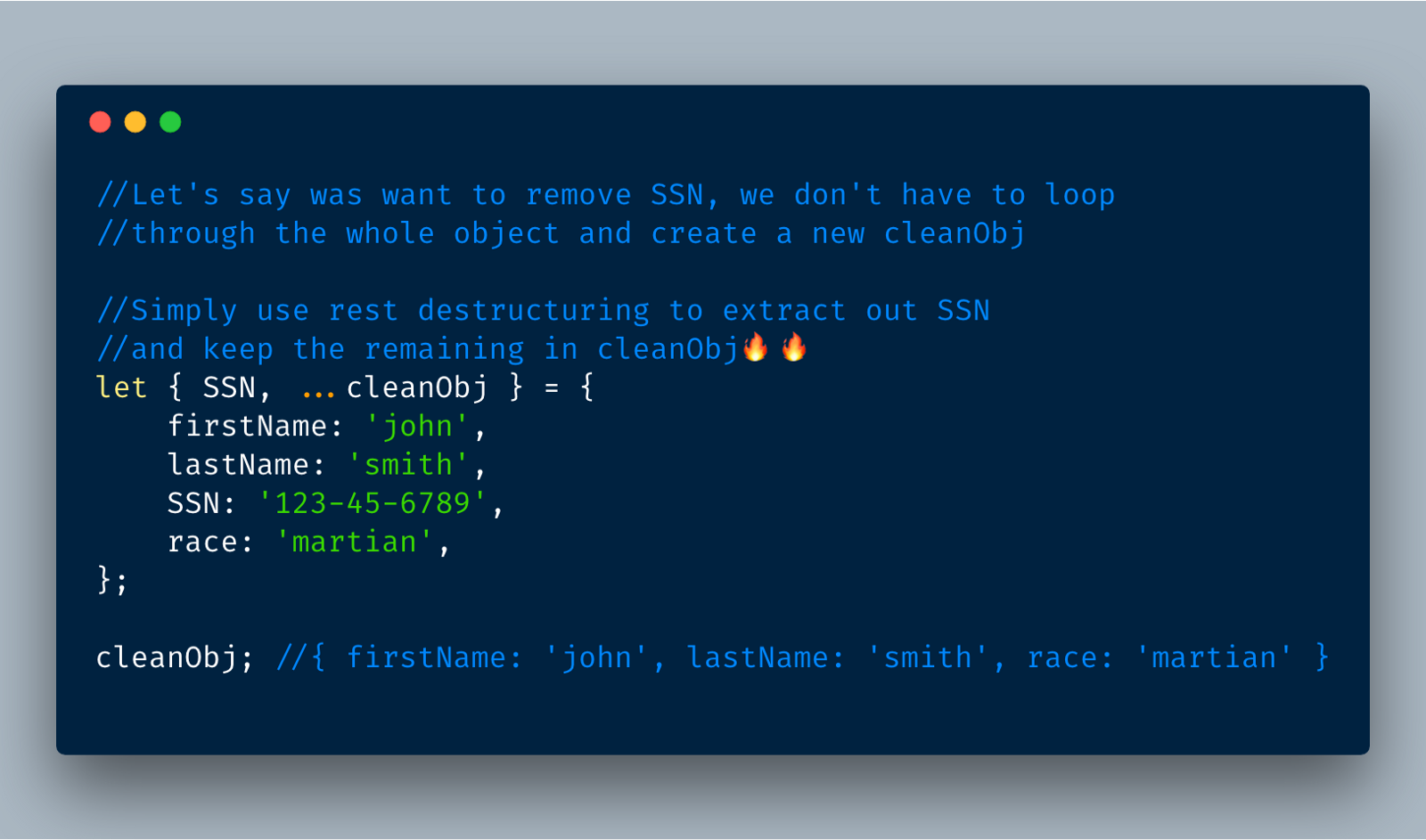
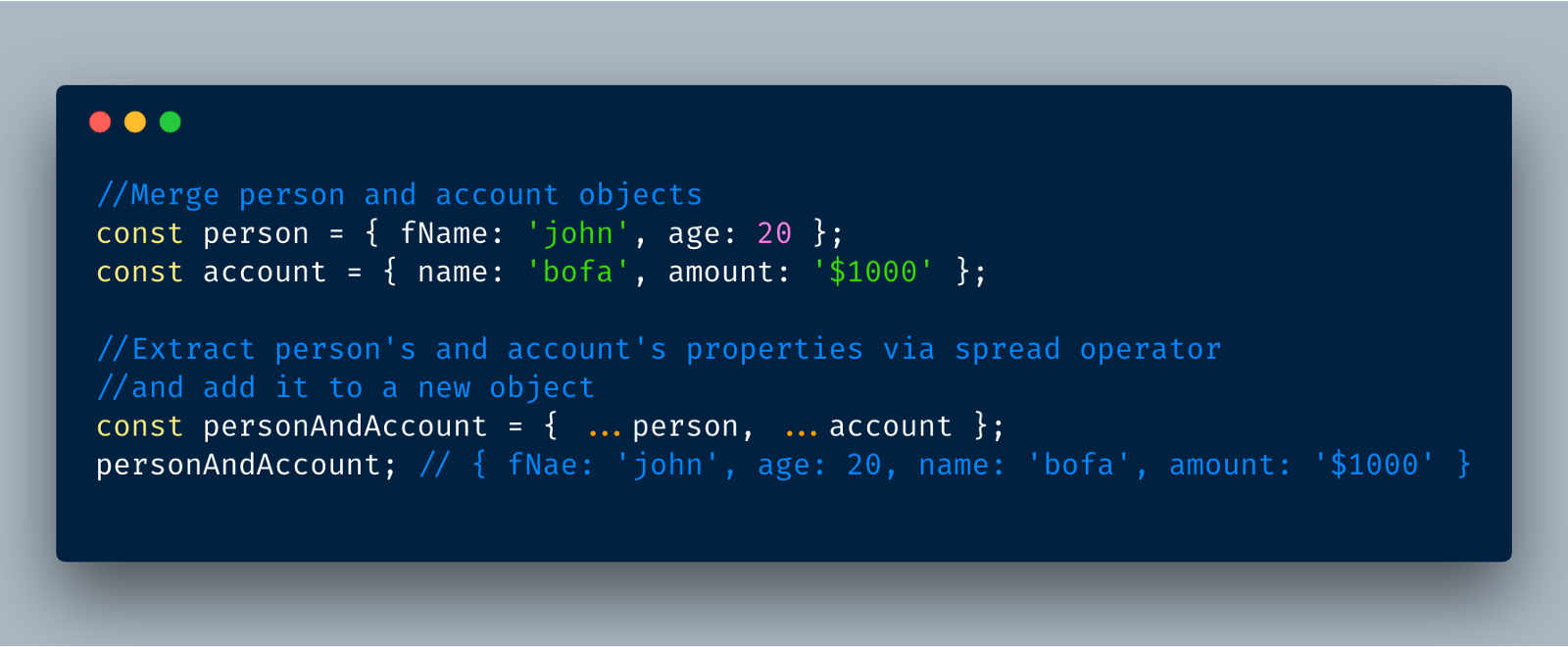
6. 对象的属性扩展
扩展属性也是使用三个点 ...,解构属性,不同的是使用扩展创建(重新构建)的是新的对象。
提醒:展开运算符用于等号的右侧,解构运算符用于等号的左侧。
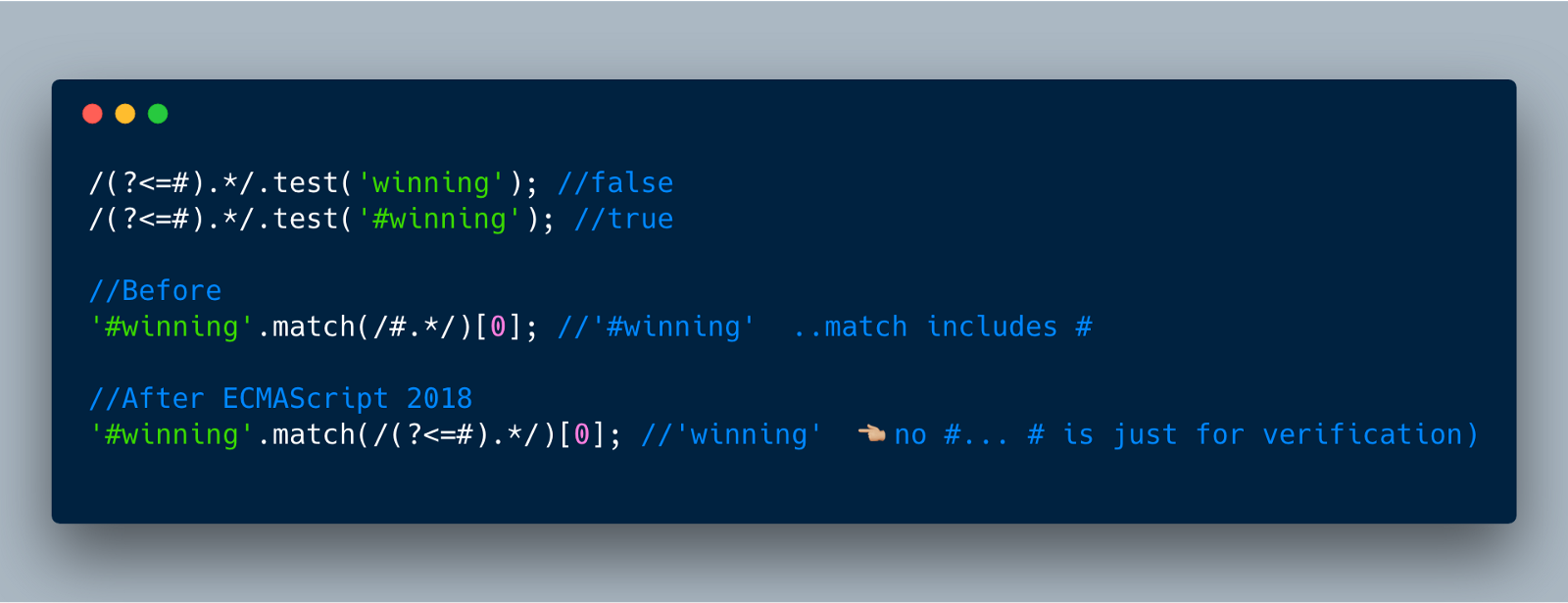
7. RegExp Lookbehind Assertions
这是RegEx的一个增强的功能,它可以使我们确保某些字符串一定在其它的字符中之前。
您现在可以使用一个组(?<= ...) (问号,小于,等于)来查找肯定的断言。
此外,您可以使用(?<!...)(问号,小于,感叹号)来查看否定断言。从本质上讲,只要-ve断言通过,就会匹配。
肯定的断言: 比如说,我们希望确保#在单词winning之前(即:#winning),并希望正则表达之返回字符串“winning”,下面展示它的写法。
否定的断言: 比方说,我们希望获取€而不是$字符之后的数字。
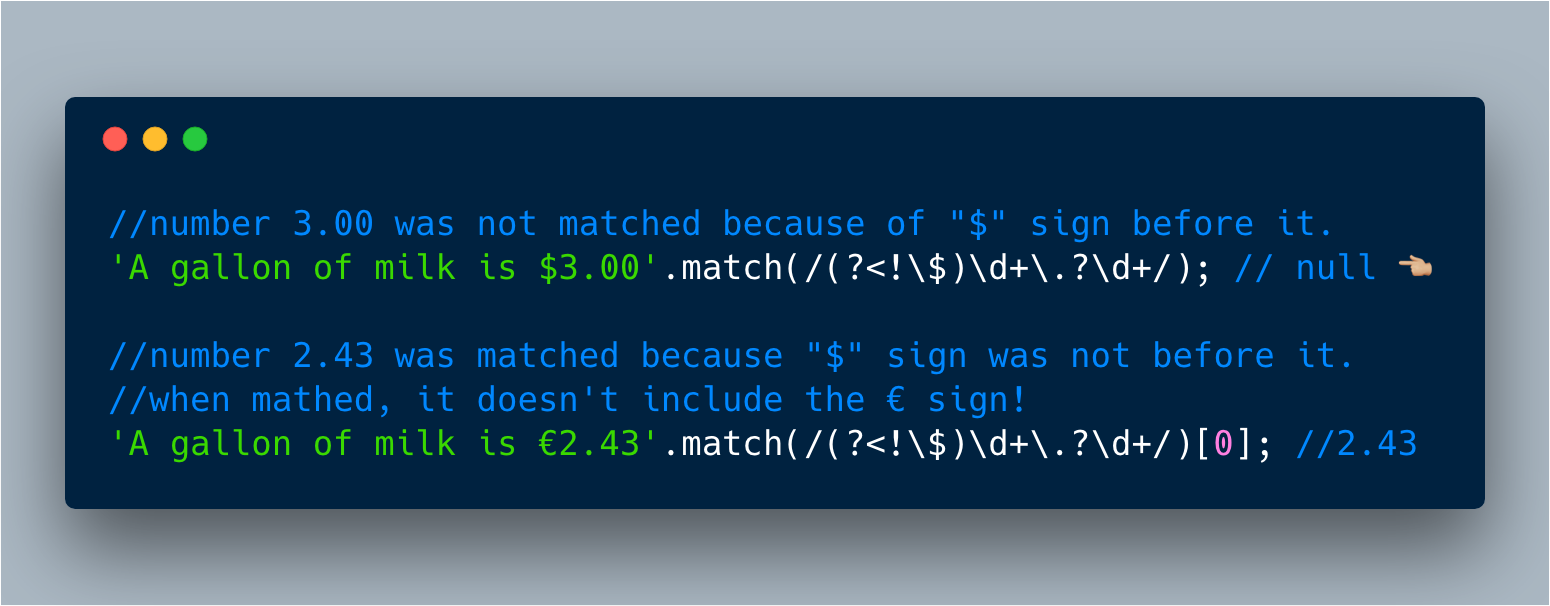
8. RegExp Unicode 转义
要编写RegEx来匹配各种Unicode字符是很难的。诸如\ w,\ W,\ d等只能匹配英文字符和数字。 但是对于印度语,希腊语等其他语言的数字呢?
这就是Unicode Property Escapes的用武之地。结果是,Unicode为每个符号(字符)添加了元数据属性,并使用它来对各种符号进行分组或表征。
例如,Unicode数据库将所有印地语字符(हिन्दी)分组在一个key为Script、值为Devanagari的属性下,另一个key为Script_Extensions的属性值也为Devanagari。所以我们可以搜索Script = Devanagari并获得所有的印地文字符。
` Devanagari 可用于马拉地语,北印度语,梵语等各种印度语言。
从ECMAScript 2018开始,我们可以使用\ p转义字符和{Script = Devanagari}来匹配所有印度字符。 也就是说,我们可以在RegEx中使用: \ p {Script = Devanagari} 来匹配所有Devanagari字符。
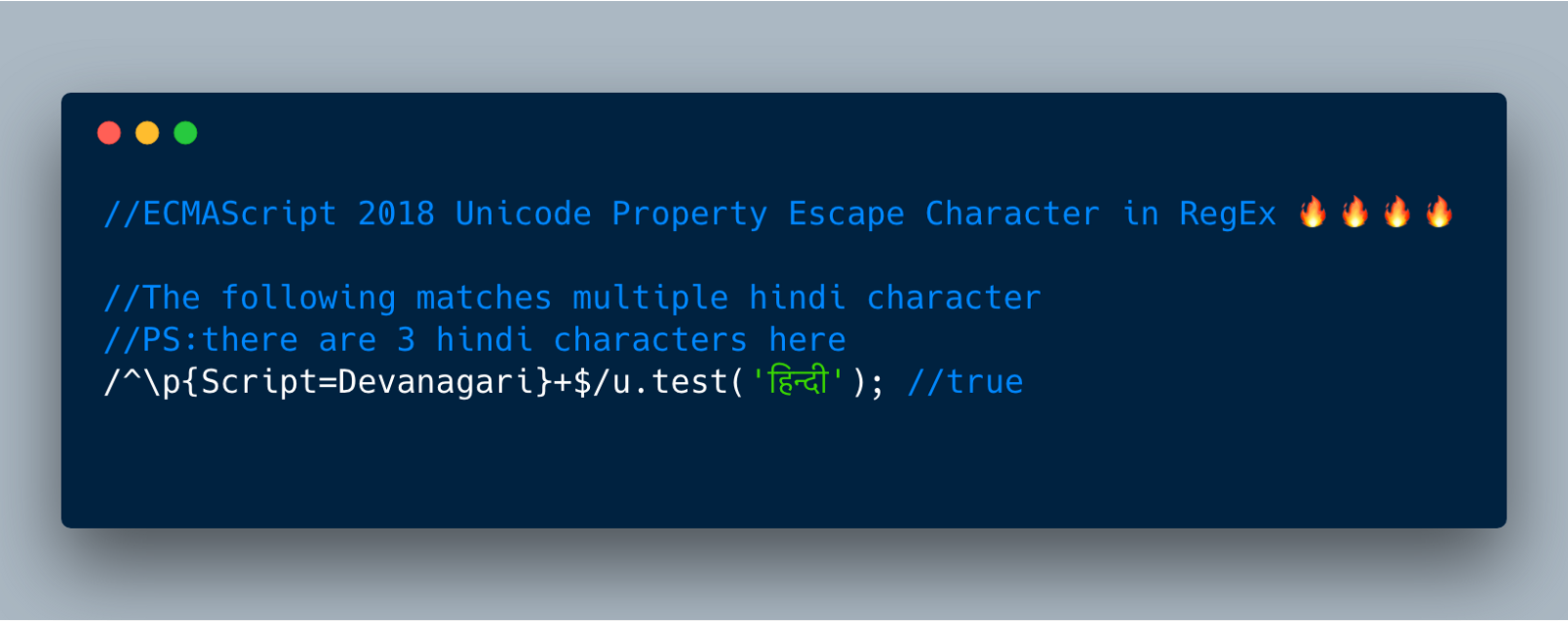
//The following matches multiple hindi character/^\p{Script=Devanagari}+$/u.test('हिन्दी');//true //PS:there are 3 hindi characters h同样,Unicode数据库将所有希腊字符组合为Script_Extensions(和Script)属性,其值为Greek。 所以我们可以使用Script_Extensions = Greek或Script = Greek来搜索所有希腊字符。
也就是说,我们可以在RegEx中使用: \ p {Script = Greek} 以匹配所有Greek字符。
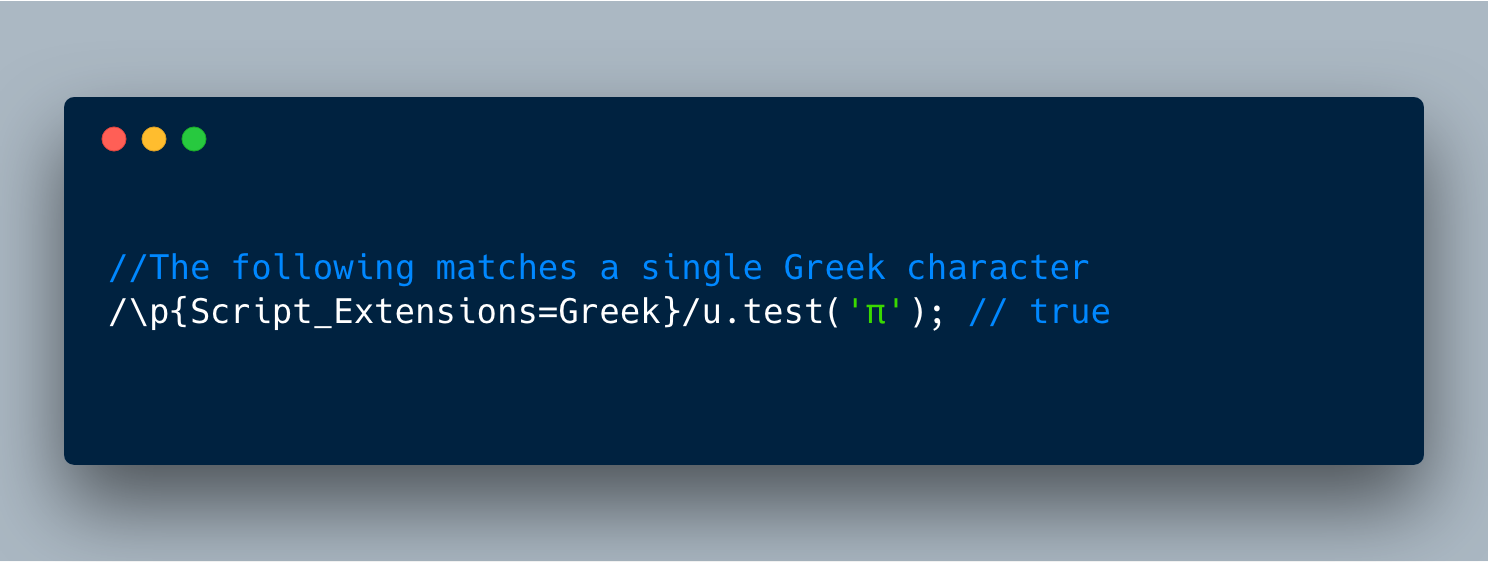
//The following matches a single Greek character/\p{Script_Extensions=Greek}/u.test('π'); // true此外,Unicode数据库将各种类型的表情符号存储在属性值为“真”的布尔属性Emoji,Emoji_Component,Emoji_Presentation,Emoji_Modifier和Emoji_Modifier_Base下。所以我们可以通过简单的选择“Emoji”来搜索所有的表情符号。
也就是说,我们可以使用: \ p {Emoji} , \ Emoji_Modifier 等来匹配各种表情符号。
下面的例子将会说明的更清晰一点。
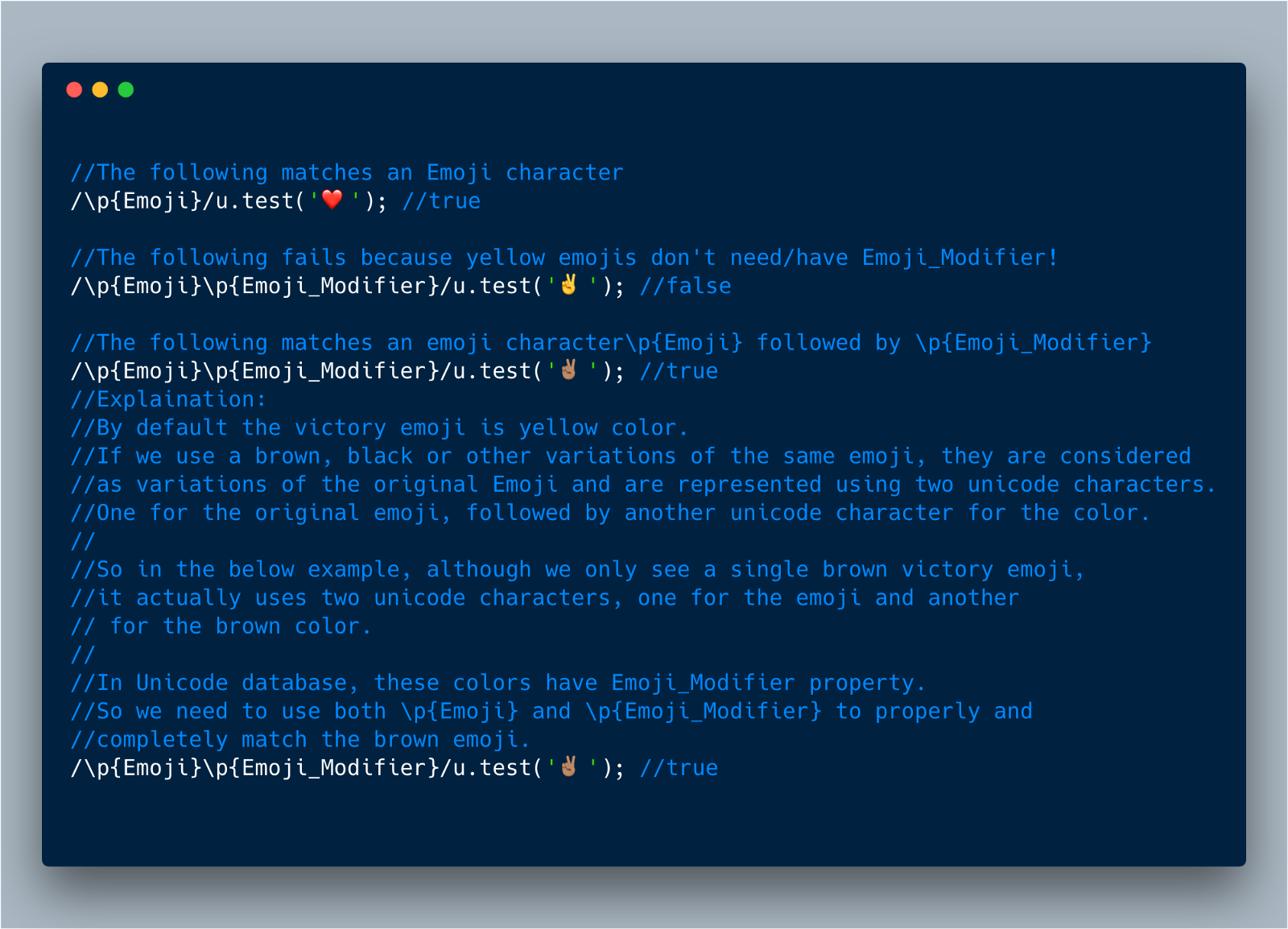
//The following matches an Emoji character/\p{Emoji}/u.test('');//true//The following fails because yellow emojis don't need/have Emoji_Modifier!/\p{Emoji}\p{Emoji_Modifier}/u.test('');//false//The following matches an emoji character\p{Emoji} followed by \p{Emoji_Modifier}/\p{Emoji}\p{Emoji_Modifier}/u.test('');
//true//Explaination:
//By default the victory emoji is yellow color.
//If we use a brown, black or other variations of the same emoji, they are considered
//as variations of the original Emoji and are represented using two unicode characters.
//One for the original emoji, followed by another unicode character for the color.
//
//So in the below example, although we only see a single brown victory emoji,
//it actually uses two unicode characters, one for the emoji and another
// for the brown color.
//
//In Unicode database, these colors have Emoji_Modifier property.
//So we need to use both \p{Emoji} and \p{Emoji_Modifier} to properly and//completely match the brown emoji.
/\p{Emoji}\p{Emoji_Modifier}/u.test('');
//true最后,我们可以使用大写的“P”(\ P )转义字符而不是小p(\ p)来否定匹配。
参考:
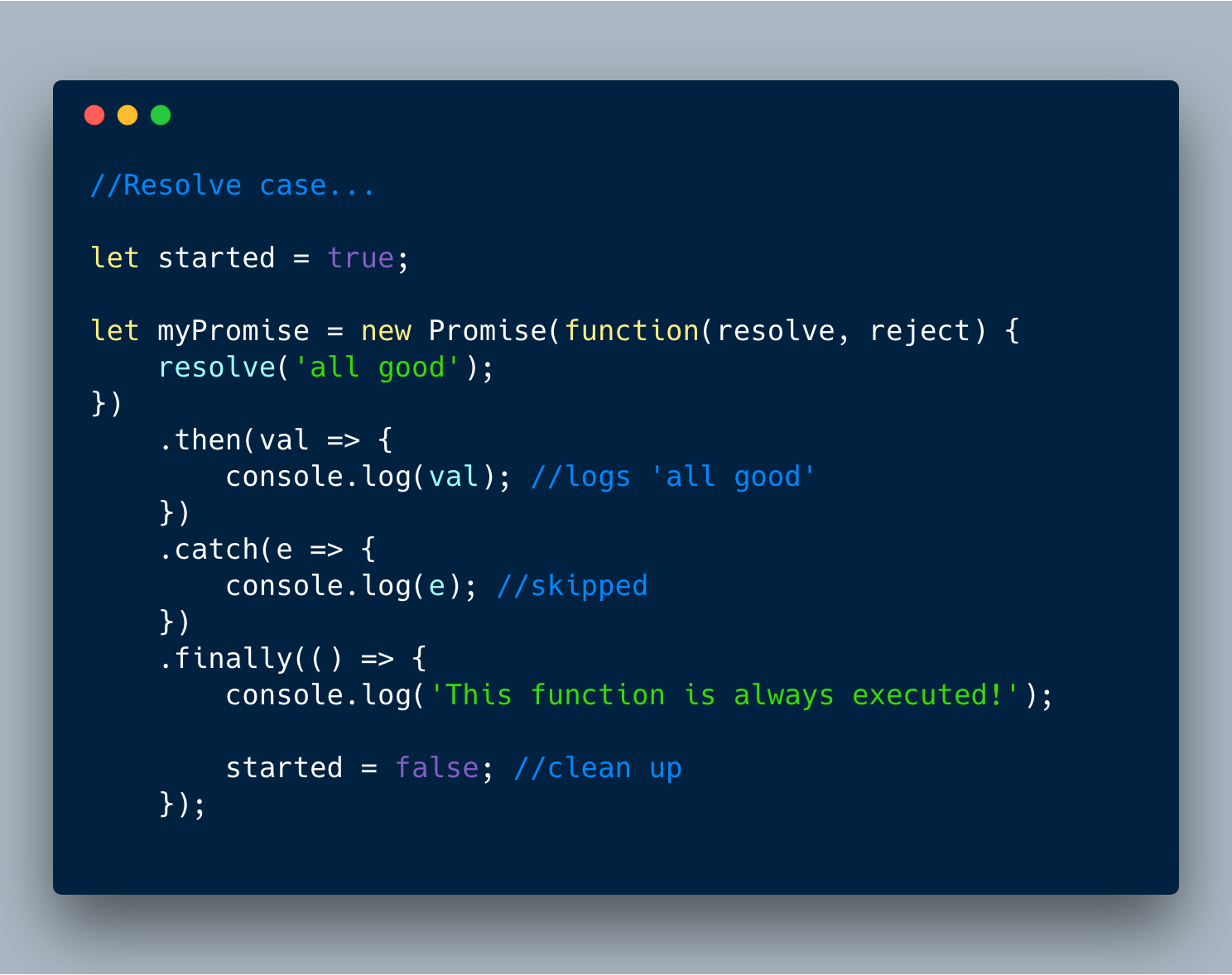
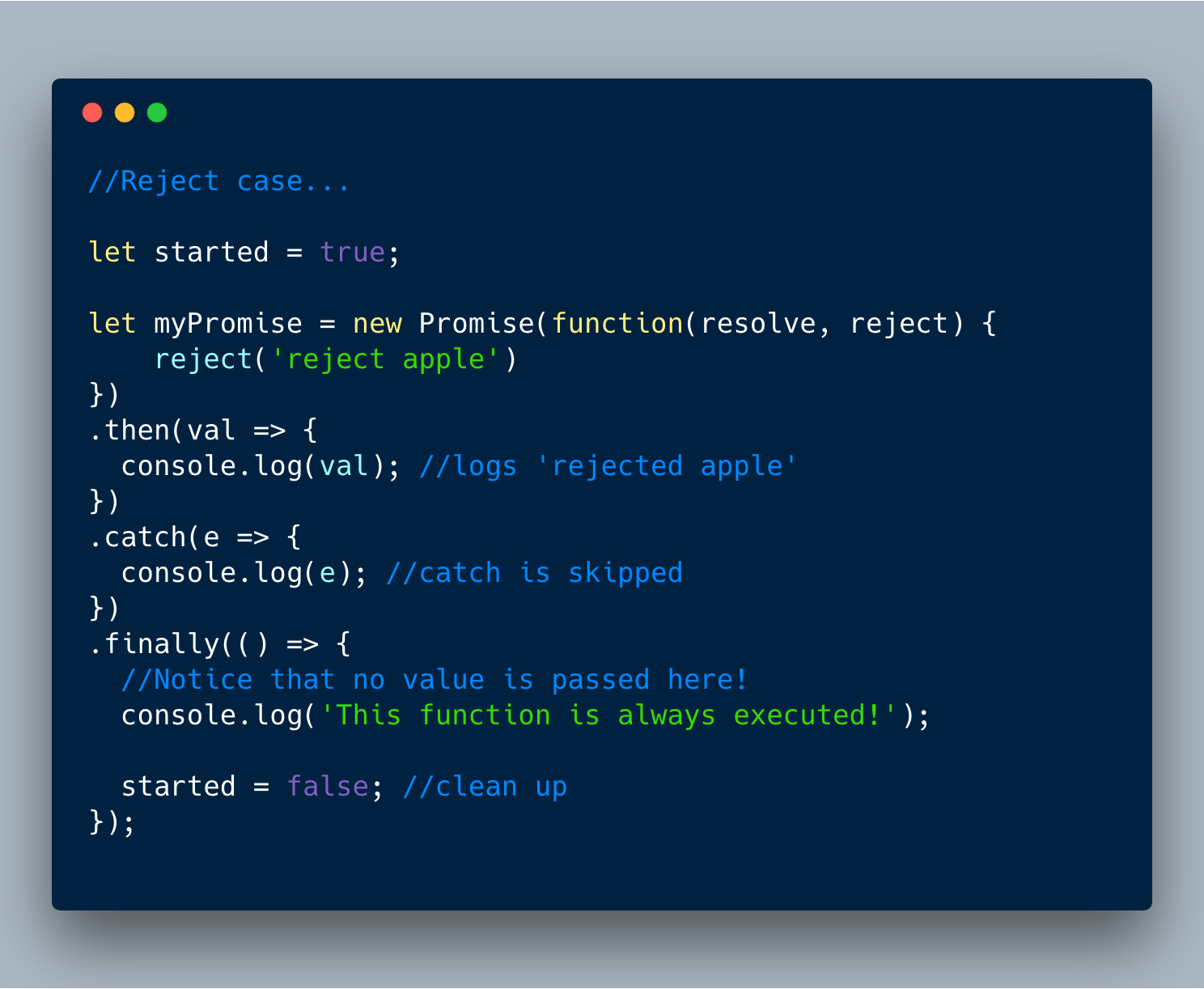
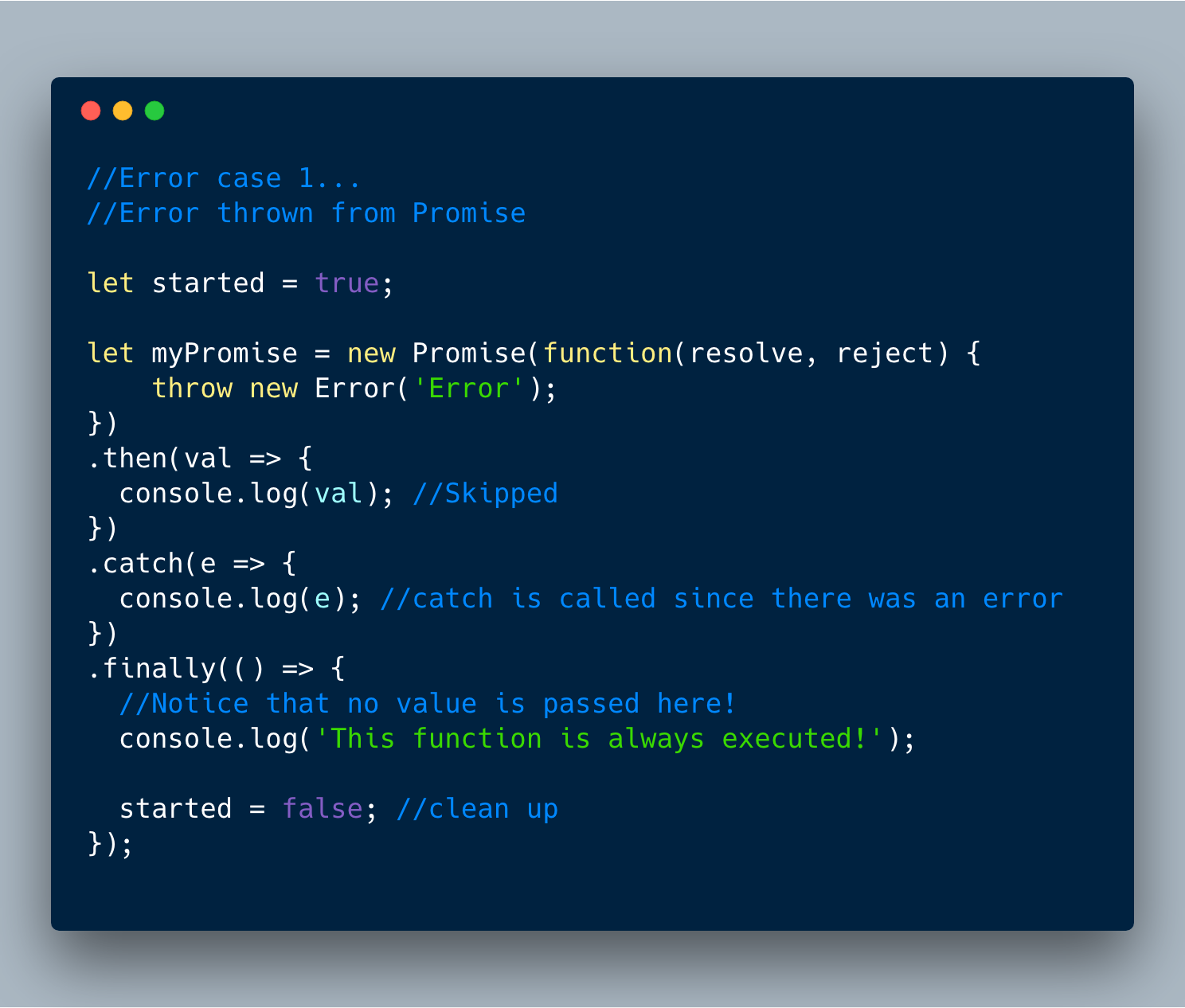
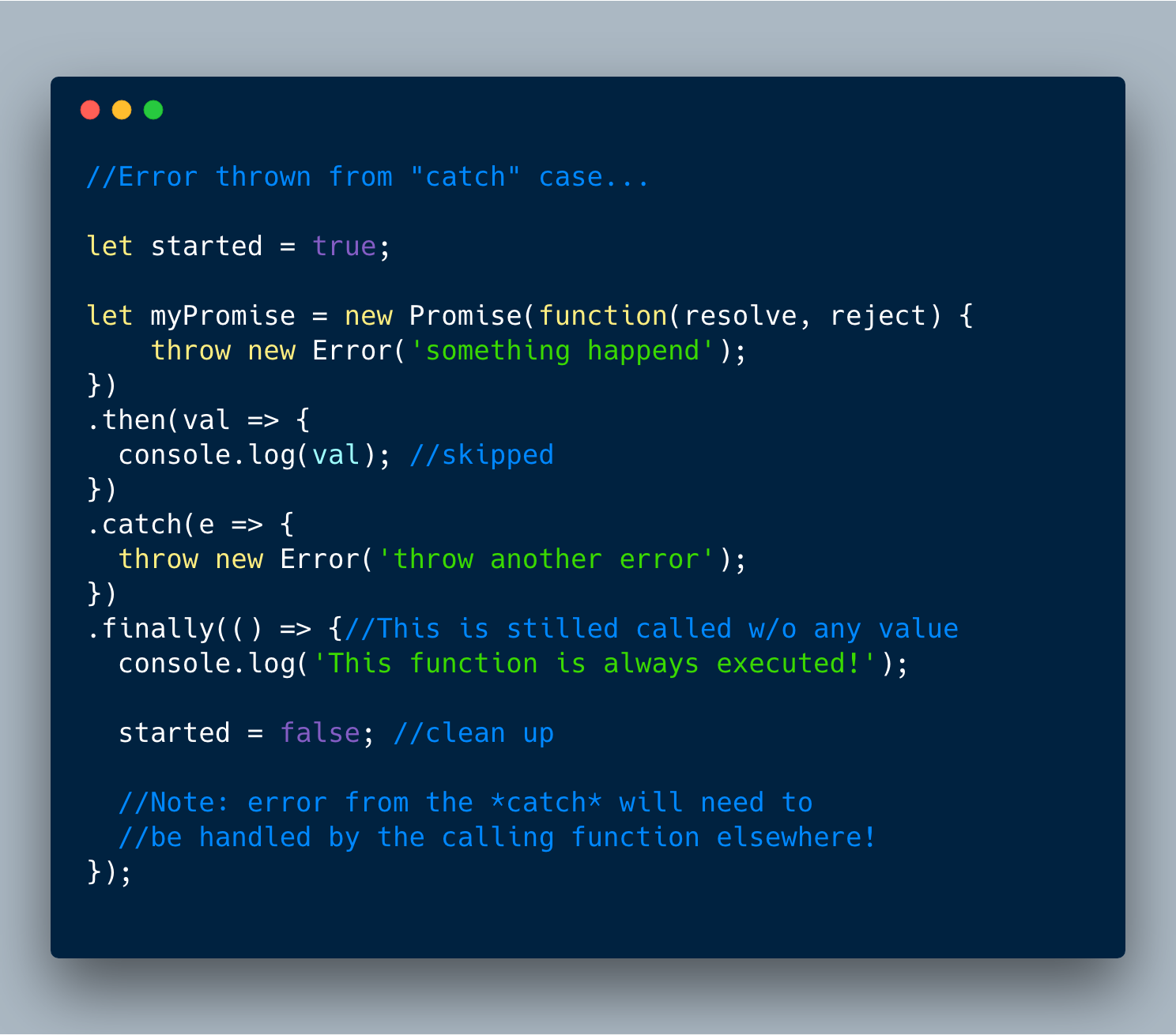
8. Promise.prototype.finally()
finally() 是Promise新添加的实例方法。主要想法是允许在“resolve”或“reject”之后运行回调来处理其它逻辑。** finally ** **回调被调用时没有任何价值,并且无论如何总是被执行。
看看不同的情况。
9. 异步迭代
这是一个*非常*有用的功能。 基本上它允许我们轻松创建异步代码循环!
这个特性增加了一个新的“for-await-of”循环,允许我们调用异步函数来返回承诺(或带有一系列承诺的数组)。比较的酷的事情是,在下一个循环执行之前当前循环都会等待所有Promise返回承诺。
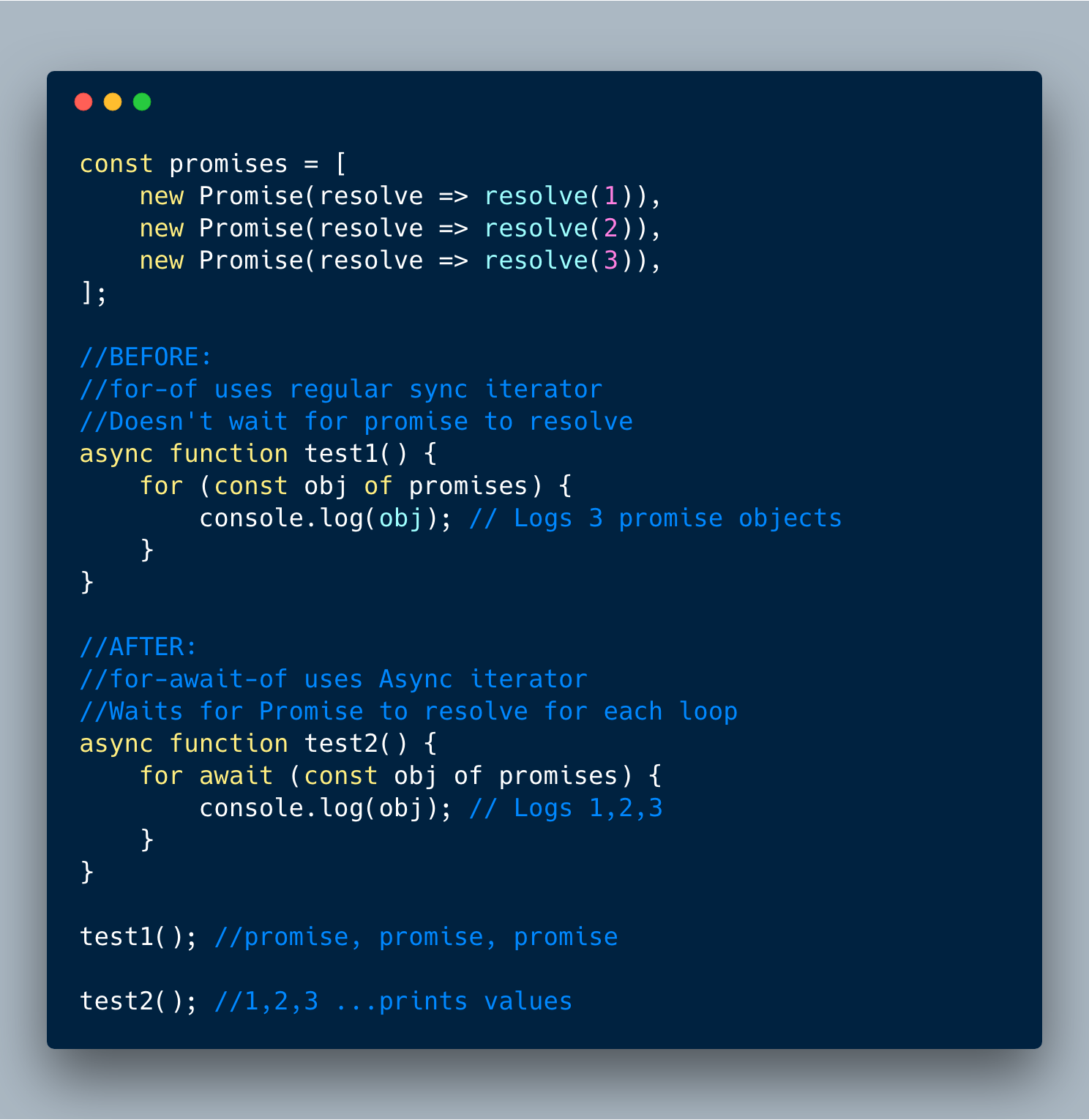
这就是这个特性。





