
假设服务器的硬件资源“充裕”,那么提高服务器性能的一个很直接的方法就是空间换时间,即“浪费”服务器的硬件资源,以换取其运行效率。提升服务器性能的一个重要方法就是采用“池”的思路,即对一组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源分配。当服务器进入正式运行阶段,即开始处理客户端请求时,如果它需要相关资源就可以直接从池中获取,无需动态分配。很显然,直接从池中取得所需要资源比动态分配资源的速度快得多,因为分配系统资源的系统调用都是很耗时的。当服务器处理完一个客户端连接后,可以把相关资源放回池中,无须执行系统调用释放资源。从最终效果来看,资源分配和回收的系统调用只发生在服务器的启动和结束,这种“池”的方式避免了中间的任务处理过程对内核的频繁访问,提高了服务器的性能。我们常用的线程池和内存池都是基于以上“池”的优势所设计出来的提升服务器性能的方法,今天打算以C++98设计一个基于Linux系统的简单线程池。
为什么要采用线程池?
首先想一想,我们一般的服务器都是动态创建子线程来实现并发服务器的,比如每当有一个客户端请求建立连接时我们就动态调用pthread_create去创建线程去处理该连接请求。这种模式有什么缺点呢?
动态创建线程是比较费时的,这将到导致较慢的客户响应。
动态创建的子线程通常只用来为一个客户服务,这将导致系统上产生大量的细微线程,线程切换也会耗费CPU时间。
所以我们为了进一步提升服务器性能,可以采取“池”的思路,把线程的创建放在程序的初始化阶段一次完成,这就避免了动态创建线程导致服务器响应请求的性能下降。
线程池的设计思路
以单例模式设计线程池,保证线程池全剧唯一;
在获取线程池实例进行线程池初始化:线程预先创建+任务队列创建;
创建一个任务类,我们真实的任务会继承该类,完成任务执行。
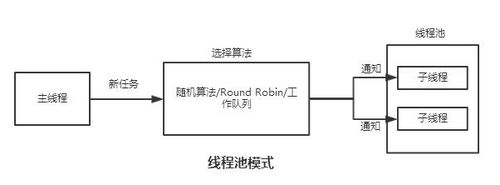
根据以上思路我们可以给出这么一个线程池类的框架:
class ThreadPool
{private: std::queue<Task*> taskQueue; //任务队列
bool isRunning; //线程池运行标志
pthread_t* pThreadSet; //指向线程id集合的指针
int threadsNum; //线程数目
pthread_mutex_t mutex; //互斥锁
pthread_cond_t condition; //条件变量
//单例模式,保证全局线程池只有一个
ThreadPool(int num=10); void createThreads(); //创建内存池
void clearThreads(); //回收线程
void clearQueue(); //清空任务队列
static void* threadFunc(void* arg); Task* takeTask(); //工作线程获取任务public: void addTask(Task* pTask); //任务入队
static ThreadPool* createThreadPool(int num=10); //静态方法,用于创建线程池实例
~ThreadPool(); int getQueueSize(); //获取任务队列中的任务数目
int getThreadlNum(); //获取线程池中线程总数目
};下面开始讲解一些实现细节。
1.单例模式下的线程池的初始化
首先我们以饿汉单例模式来设计这个线程池,以保证该线程池全局唯一:
构造函数私有化
提供一个静态函数来获取线程池对象
//饿汉模式,线程安全ThreadPool* ThreadPool::createThreadPool(int num)
{ static ThreadPool* pThreadPoolInstance = new ThreadPool(num); return pThreadPoolInstance;
}
ThreadPool* pMyPool = ThreadPool::createThreadPool(5);线程池对象初始化时我们需要做三件事:相关变量的初始化(线程池状态、互斥锁、条件变量等)+任务队列的创建+线程预先创建
ThreadPool::ThreadPool(int num):threadsNum(num)
{ printf("creating threads pool...\n");
isRunning = true;
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&condition, NULL);
createThreads(); printf("created threads pool successfully!\n");
}线程池的数目根据对象创建时输入的数目来创建,如果不指定数目,我们就是使用默认数目10个。
void ThreadPool::createThreads()
{
pThreadSet = (pthread_t*)malloc(sizeof(pthread_t) * threadsNum); for(int i=0;i<threadsNum;i++)
{
pthread_create(&pThreadSet[i], NULL, threadFunc, this);
}
}2.任务添加和线程调度
对于每一个服务请求我们都可以看作是一个任务,一个任务来了我们就将它送进线程池中的任务队列中,并通过条件变量的方式通知线程池中的空闲线程去拿任务去完成。那问题来了,这里的任务在编程的层面上看到底是什么?我们可以将任务看成是一个回调函数,将要执行的函数指针往任务队列里面送就可以了,我们线程拿到这个指针后运行该函数就等于完成服务请求。基于以上的考虑,我们设计了一个单独的抽象任务类,让子类继承。类里面有个纯虚函数run(),用于执行相应操作。
考虑到回调函数需要传参数进来,所以特意设置了个指针arg来存储参数地址,到时候我们就可以根据该指针解析出传入的函数实参是什么了。
任务基类
class Task
{public:
Task(void* a = NULL): arg(a)
{
} void SetArg(void* a)
{
arg = a;
} virtual int run()=0;protected: void* arg;
};typedef struct{ int task_id; std::string task_name;
}msg_t;class MyTask: public Task
{public: int run()
{ msg_t* msg = (msg_t*)arg; printf("working thread[%lu] : task_id:%d task_name:%s\n", pthread_self(),
msg->task_id, msg->task_name.c_str());
sleep(10); return 0;
}
};真正使用该类时就自己定义一个子类继承Task类,并实现run()函数,并通过SetArg()方法去设置传入的参数。比如可以这么用:
msg_t msg[10];MyTask task_A[10];
//模拟生产者生产任务
for(int i=0;i<10;i++)
{
msg[i].task_id = i;
sprintf(buf,"qq_task_%d",i);
msg[i].task_name = buf;
task_A[i].SetArg(&msg[i]);
pMyPool->addTask(&task_A[i]);
sleep(1);
}现在来到线程池设计中最难搞的地方:线程调度。一个任务来了,究竟怎么让空闲线程去拿任务去做呢?我们又如何保证空闲的线程不断地去拿任务呢?
抽象而言,这是一个生产者消费者的模型,系统不断往任务队列里送任务,我们通过互斥锁和条件变量来控制任务的加入和获取,线程每当空闲时就会去调用takeTask()去拿任务。如果队列没任务那么一些没获得互斥锁的线程就会拥塞等待(因为没锁),获得互斥锁的那个线程会因为没任务而拥塞等待。一旦有任务就会唤醒这个带锁线程拿走任务释放互斥锁。看看代码层面是如何操作的:
加入一个任务
void ThreadPool::addTask(Task* pTask)
{
pthread_mutex_lock(&mutex);
taskQueue.push(pTask);
printf("one task is put into queue! Current queue size is %lu\n",taskQueue.size());
pthread_mutex_unlock(&mutex);
pthread_cond_signal(&condition);
}取走一个任务
Task* ThreadPool::takeTask()
{
Task* pTask = NULL; while(!pTask)
{
pthread_mutex_lock(&mutex); //线程池运行正常但任务队列为空,那就等待任务的到来
while(taskQueue.empty() && isRunning)
{
pthread_cond_wait(&condition, &mutex);
} if(!isRunning)
{
pthread_mutex_unlock(&mutex); break;
} else if(taskQueue.empty())
{
pthread_mutex_unlock(&mutex); continue;
}
pTask = taskQueue.front();
taskQueue.pop();
pthread_mutex_unlock(&mutex);
} return pTask;
}线程中的回调函数。这里注意的是,如果取到的任务为空,我们认为是线程池关闭的信号(线程池销毁时我们会在析构函数中调用pthread_cond_broadcast(&condition)来通知线程来拿任务,拿到的当然是空指针),我们退出该线程。
void* ThreadPool::threadFunc(void* arg)
{
ThreadPool* p = (ThreadPool*)arg; while(p->isRunning)
{
Task* task = p->takeTask(); //如果取到的任务为空,那么我们结束这个线程
if(!task)
{ //printf("%lu thread will shutdown!\n", pthread_self());
break;
} printf("take one...\n");
task->run();
}
}3.使用例子和测试
下面给出一个线程池的一个使用例子。可以看出,我首先定义了msg_t的结构体,这是因为我们的服务响应函数是带参数的,所以我们定义了这个结构体并把其地址作为参数传进线程池中去(通过SetArg方法)。然后我们也定义了一个任务类MyTask继承于Task,并重写了run方法。我们要执行的服务函数就可以写在run函数之中。当需要往任务队列投放任务时调用addTask()就可以了,然后线程池会自己安排任务的分发,外界无须关心。所以一个线程池执行任务的过程可以简化为:createThreadPool() -> SetArg() -> addTask -> while(1) -> delete pMyPool
#include <stdio.h>#include "thread_pool.h"#include <string>#include <stdlib.h>typedef struct{ int task_id; std::string task_name;
}msg_t;class MyTask: public Task
{public: int run()
{ msg_t* msg = (msg_t*)arg; printf("working thread[%lu] : task_id:%d task_name:%s\n", pthread_self(),
msg->task_id, msg->task_name.c_str());
sleep(10); return 0;
}
};int main(){
ThreadPool* pMyPool = ThreadPool::createThreadPool(5); char buf[32] = {0}; msg_t msg[10];
MyTask task_A[10]; //模拟生产者生产任务
for(int i=0;i<10;i++)
{
msg[i].task_id = i; sprintf(buf,"qq_task_%d",i);
msg[i].task_name = buf;
task_A[i].SetArg(&msg[i]);
pMyPool->addTask(&task_A[i]);
sleep(1);
} while(1)
{ //printf("there are still %d tasks need to process\n", pMyPool->getQueueSize());
if (pMyPool->getQueueSize() == 0)
{ printf("Now I will exit from main\n"); break;
}
sleep(1);
} delete pMyPool; return 0;
}程序具体运行的逻辑是,我们建立了一个5个线程大小的线程池,然后我们又生成了10个任务,往任务队列里放。由于线程数小于任务数,所以当每个线程都拿到自己的任务时,任务队列中还有5个任务待处理,然后有些线程处理完自己的任务了,又去队列里取任务,直到所有任务被处理完了,循环结束,销毁线程池,退出程序。
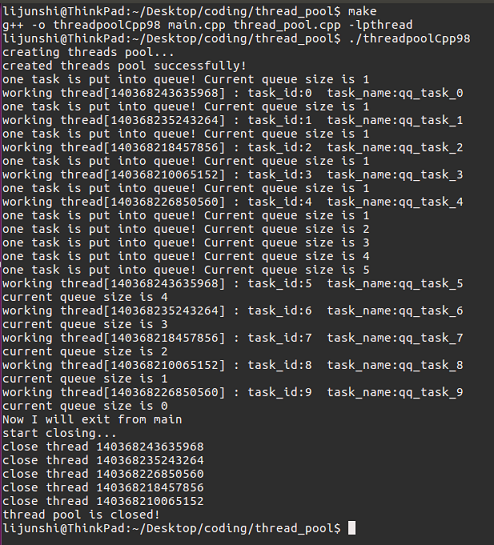
完整的内存池框架和测试例子在我的github。





热门评论
-

慕哥03610592018-04-25 0
查看全部评论题目是内存池,内容讲的是线程池?!