

前言:由于之前没有接触过Hibernate框架,但是最近看一些博客深深被它的“效率”所吸引,所以这就来跟大家一起就着一个简单的例子来尝尝Spring全家桶里自带的JPA的鲜
Spring-DATA-JPA 简介
JPA(Java Persistence API)是Sun官方提出的Java持久化规范。它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合ORM技术,结束现在Hibernate,TopLink,JDO等ORM框架各自为营的局面。值得注意的是,JPA是在充分吸收了现有Hibernate,TopLink,JDO等ORM框架的基础上发展而来的,具有易于使用,伸缩性强等优点。从目前的开发社区的反应上看,JPA受到了极大的支持和赞扬,其中就包括了Spring与EJB3.0的开发团队。
注意:JPA是一套规范,不是一套产品,那么像Hibernate,TopLink,JDO他们是一套产品,如果说这些产品实现了这个JPA规范,那么我们就可以叫他们为JPA的实现产品。
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!(spring data jpa让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现)
Hibernate 和 MyBatis 简单对比
由于JPA底层干活的仍然是Hibernate框架,而我们之前学习的只有MyBatis相关的东西,所以在尝鲜之前还是有必要简单了解一下两者的区别:
Hibernate的优势:
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。
MyBatis的优势:
MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
MyBatis容易掌握,而Hibernate门槛较高。
简单总结:
MyBatis:小巧、方便、高效、简单、直接、半自动化
Hibernate:强大、方便、高效、复杂、间接、全自动化
CRUD + 分页后台实例
下面我们来快速搭建一个使用Spring-DATA-JPA的CRUD+分页后台实例,并且我们会直接使用到RESTful API(不熟悉的同学戳这里)
第一步:新建SpringBoot项目
打开IDEA新建一个SpringBoot项目,不熟悉SpringBoot的同学请右转:【传送门】,然后在pom.xml中添加以下依赖:
<!-- mysql--><dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.21</version></dependency><!-- jpa--><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId></dependency>
然后把application.properties弄成这个样子:
#数据库spring.datasource.url=jdbc:mysql://127.0.0.1:3306/testdb?useUnicode=true&characterEncoding=utf-8 spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.jpa.properties.hibernate.hbm2ddl.auto=update#显示SQL语句spring.jpa.show-sql=true#不加下面这句则默认创建MyISAM引擎的数据库spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect#自己重写的配置类,默认使用utf8编码spring.jpa.properties.hibernate.dialect=com.wmyskxz.demo.config.MySQLConfig
spring.jpa.properties.hibernate.hbm2ddl.auto是hibernate的配置属性,其主要作用是:自动创建、更新、验证数据库表结构。该参数的几种配置如下:
create:每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。
create-drop:每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。
update:最常用的属性,第一次加载hibernate时根据model类会自动建立起表的结构(前提是先建立好数据库),以后加载hibernate时根据model类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等应用第一次运行起来后才会。
validate:每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。
然后新建一个【config】包,创建一个【MySQLConfig】类(上面的spring.jpa.properties.hibernate.dialect属性就要配置这里的类全路径):
package com.wmyskxz.demo.config;import org.hibernate.dialect.MySQL5InnoDBDialect;public class MySQLConfig extends MySQL5InnoDBDialect { @Override
public String getTableTypeString() { return "ENGINE=InnoDB DEFAULT CHARSET=utf8";
}
}第二步:创建好需要的数据库
打开SQL服务,建表语句也很简单啦:
create database testdb;
第三步:创建实体类
实体类映射的实际上是数据库表的结构,在适当的包目录下(例如【entity】)下创建好实体类:
package com.wmyskxz.demo.entity;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.Id;@Entity // 表明这是个实体类public class User { @Id // 表明这个属性是主键
@GeneratedValue // 自增长
private long id; @Column(nullable = false, unique = true) // 不允许为空,属性唯一
private String username; @Column(nullable = false) // 不允许为空
private String password; // getter and setter}第四步:DAO层
新建一个【repository】包,然后新建一个【UserRepository】接口,并继承JpaRepository类:
package com.wmyskxz.demo.repository;import com.wmyskxz.demo.entity.User;import org.springframework.data.jpa.repository.JpaRepository;public interface UserRepository extends JpaRepository<User, Long> {
}继承JpaRepository需要传入两个参数,一个是实体类User一个是主键的类型Long,而凡是继承了JpaRepository类的就会自动实现很多内置的方法,包括增删改查,以及使用默认支持的Pageable对象来进行分页,默认的方法大致如下:
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> { List<T> findAll(); List<T> findAll(Sort var1); List<T> findAllById(Iterable<ID> var1);
<S extends T> List<S> saveAll(Iterable<S> var1); void flush();
<S extends T> S saveAndFlush(S var1); void deleteInBatch(Iterable<T> var1); void deleteAllInBatch(); T getOne(ID var1);
<S extends T> List<S> findAll(Example<S> var1);
<S extends T> List<S> findAll(Example<S> var1, Sort var2);
}第五步:Controller层
新建【controller】包,新建一个【UserController】类,编写简单的增删改查代码:
package com.wmyskxz.demo.controoler;import com.wmyskxz.demo.entity.User;import com.wmyskxz.demo.repository.UserRepository;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.domain.PageRequest;import org.springframework.data.domain.Sort;import org.springframework.web.bind.annotation.*;import java.util.Optional;@RestController // 表明这是一个Controller并返回JSON格式public class UserController { @Autowired
private UserRepository userRepository; @GetMapping("/getOne") public Optional<User> getOneUserById(@RequestParam long id) { return userRepository.findById(id);
} @GetMapping("/all") public Iterable<User> getAllUsers(@RequestParam(value = "page", defaultValue = "0") int page,
@RequestParam(value = "size", defaultValue = "5") int size) {
page = page < 0 ? 0 : page;// 如果page为负数则修改为0,防止在首页点击上一页发生错误
Sort sort = new Sort(Sort.Direction.DESC, "id");// 按id倒叙排列
return userRepository.findAll(new PageRequest(page, size, sort));
} @PostMapping("/add") public String addUser(@RequestParam String username,
@RequestParam String password) {
User user = new User();
user.setUsername(username);
user.setPassword(password);
userRepository.save(user);// 注意这里是save
return "Saved";
} @DeleteMapping("/delete") public String deleteUserById(@RequestParam long id) {
userRepository.deleteById(id); return "Deleted";
} @PutMapping("/update") public String updateUser(User user) {// User user = new User();// user.setId(id);// user.setUsername(username);// user.setPassword(password);
userRepository.save(user); return "Updated";
}
}上面就直接使用@Autowired自动引入了继承了JpaRepository的UserRepository接口,我们使用它默认的方法已经足够完成我们的基础功能了,值得一提的是我们的getAllUsers(...)方法,它往findAll()方法里传入了一个Pageable对象,这是Spring Data库中定义的一个接口,是所有分页相关信息的一个抽象,通过该接口,我们可以得到和分页相关的所有信息(例如pageNumber、pageSize等),这样Jpa就能够通过Pageable参数来得到一个带分页信息的Sql语句。
当然上面我们是通过自己创建了一个Pageable对象,Spring也支持直接获取Pageable对象,可以把上面的getAllUsers(...)方法改写成下面这样:
@GetMapping("/all")public Iterable<User> getAllUsers(@PageableDefault(value = 5, sort = {"id"}, direction = Sort.Direction.DESC)
Pageable pageable) { return userRepository.findAll(pageable);
}默认从第0页开始,也可以自己传入一个page参数,跟上面的是一样的。
第六步:运行项目
上面我们就快速搭建起来了一个基于Spring Boot和JPA的REST风格的后台增删改查实例,我们把项目跑起来,可以看到数据库自动创建了一些表:
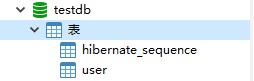
JPA帮我们创建的user表的创建SQL如下:
CREATE TABLE `user` ( `id` bigint(20) NOT NULL, `password` varchar(255) NOT NULL, `username` varchar(255) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `UK_sb8bbouer5wak8vyiiy4pf2bx` (`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
使用REST测试工具测试
完全符合我们的要求,然后我们使用一些REST的测试工具,来测试上面的功能是否都能正确运行,比如我这里使用的【Restlet Client】,在Chrome商店就可以下载到。
/all地址测试:
首先先来测试一下http://localhost:8080/all地址,由于现在数据库还是空的,所以可以看到返回如下:
{ "content": [
], "pageable": { "sort": { "sorted": true, "unsorted": false, "empty": false
}, "offset": 0, "pageNumber": 0, "pageSize": 5, "unpaged": false, "paged": true
}, "totalElements": 0, "last": true, "totalPages": 0, "number": 0, "size": 5, "sort": { "sorted": true, "unsorted": false, "empty": false
}, "numberOfElements": 0, "first": true, "empty": true}添加用户测试:
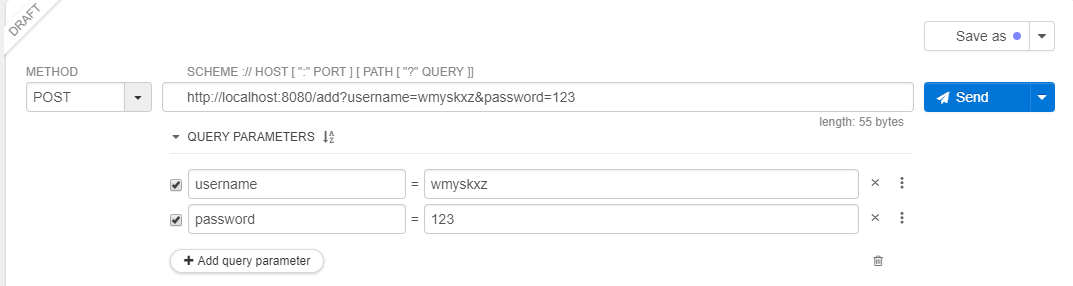
然后我们使用http://localhost:8080/add?username=wmyskxz&password=123地址,添加几个类似的用户信息:
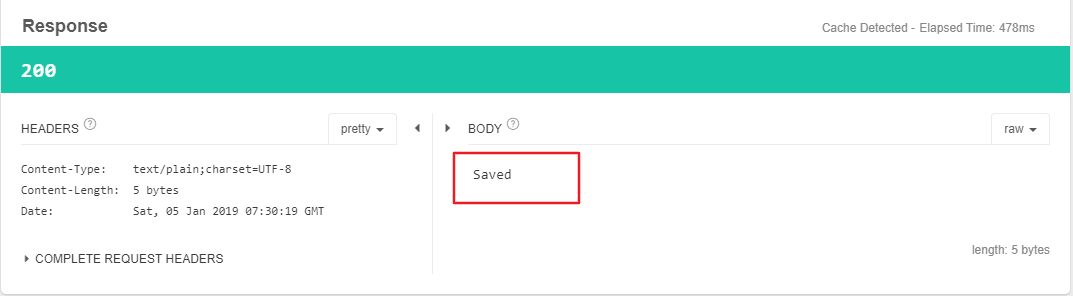
可以看到返回正确的Saved信息:
/getOne地址测试:
我们就直接使用http://localhost:8080/getOne?id=1来获取刚才添加的用户,可以看到返回正确的数据:
{ "id": 1, "username": "wmyskxz", "password": "123"}修改用户测试:
然后我们使用http://localhost:8080/update?id=1&username=wmyskxz&password=123456来模拟进行用户密码的修改:
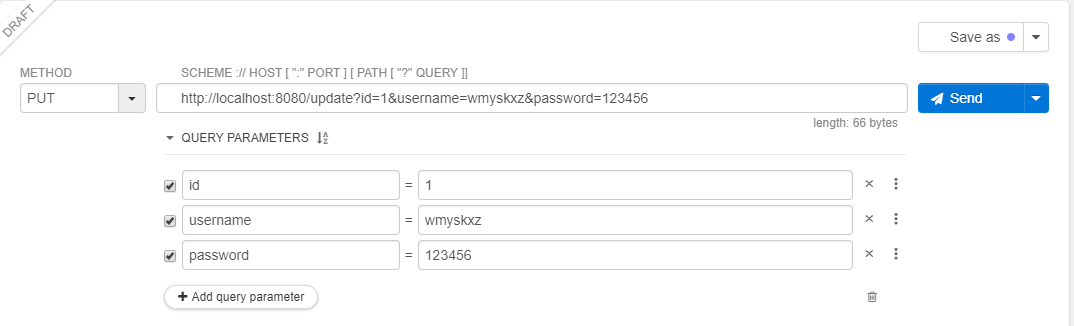
可以看到正确的更新信息Updated,再次查询用户,也能看到正确的数据:
{ "id": 1, "username": "wmyskxz", "password": "123456"}分页测试:
我们使用添加功能为数据库添加5条以上的数据,然后进行一次查询/all,可以看到能够按照id倒叙排列后返回5条数据:
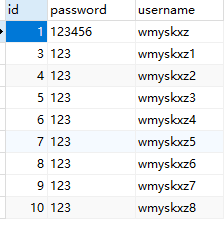
返回的JSON数据如下:
{ "content": [
{ "id": 10, "username": "wmyskxz8", "password": "123"
},
{ "id": 9, "username": "wmyskxz7", "password": "123"
},
{ "id": 8, "username": "wmyskxz6", "password": "123"
},
{ "id": 7, "username": "wmyskxz5", "password": "123"
},
{ "id": 6, "username": "wmyskxz4", "password": "123"
}
], "pageable": { "sort": { "sorted": true, "unsorted": false, "empty": false
}, "offset": 0, "pageNumber": 0, "pageSize": 5, "unpaged": false, "paged": true
}, "totalElements": 9, "last": false, "totalPages": 2, "number": 0, "size": 5, "sort": { "sorted": true, "unsorted": false, "empty": false
}, "numberOfElements": 5, "first": true, "empty": false}删除用户测试:
使用地址http://localhost:8080/delete?id=1来删除ID为1的用户:
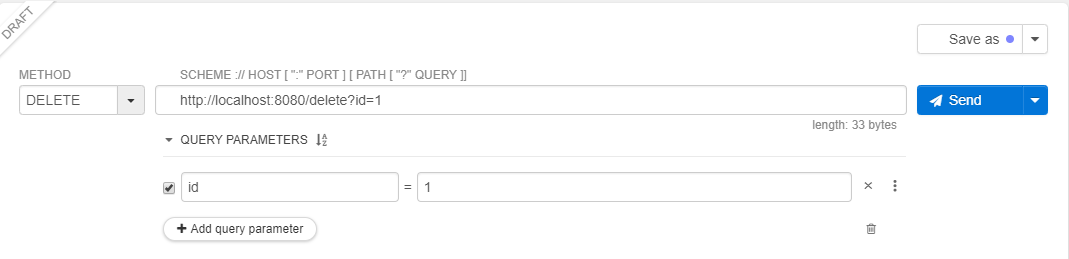
能正确看到Deleted信息,并查看数据能够看到数据已经被删除了。
以上,我们就快速搭建好了一个CRUD+分页的后台实例,还用了比较流行的RESTful风格,粗略的感受了一下JPA的方便,还是挺爽的..没有复杂的Mapper文件,不用自动生成实体,甚至不用管SQL,只需要专注在逻辑上就行了,其实简单使用的话以上的东西也能应付一些常见的场景了,后期再深入了解了解吧!
参考资料:
springboot(五):spring data jpa的使用——纯洁的微笑
springboot(十五):springboot+jpa+thymeleaf增删改查示例——纯洁的微笑
Spring Boot中使用Spring-data-jpa让数据访问更简单、更优雅——程序猿DD




