
一、创建模型
1,一对多关系
一本书只有一个出版社,一个出版社可以出版多本书,从而书与出版社之间就构成一对多关系,书是‘多’的一方,出版社是‘一’的一方,我们在建立模型的时候,把外键写在‘多’的一方,即我们要把外键写在book类。

class Book(models.Model):
name=models.CharField(max_length=15)
price=models.IntegerField()
publish=models.ForeignKey('Publish',on_delete=models.CASCADE) #这就是外键,其实是有三个参数的,第二参数是指向的字段,此处可以省略,他会自动指向id字段class Publish(models.Model):
name=models.CharField(max_length=15)
addr=models.CharField(max_length=15)
phone=models.IntegerField()
在创建模型时不用创建id字段,在makemigrations命令输入之后,它会在migrations文件夹下生产一个py文件记录models.py里面所有的改动,在记录的时候就会自动给你加上自增长的主键字段id。
2,多对多关系
一本书可以有多个作者,一个作者可以写多本书,从而书和作者就构成了多对多的关系,我们在创建模型的时候,把多对多关系写在其中的任何一张表都可以。
class Book(models.Model):
name=models.CharField(max_length=15)
price=models.IntegerField()
publish=models.CharField(max_length=15)
author=models.ManyToManyField('Author',db_table='book_author') 这是创建关系表的代码,由于是写在book模型中的,所以第一个参数为另一张表Author,第二个参数为把关系表的名字改为‘book_author’,如果不写,
名字会是应用名_本模型名的小写_另一张模型名的小写。如‘app_book_author’ class Meta: 这是把表名改为‘book’,如果不写,表名为APP名_模型名,如'app_book'
db_table='book'class Author(models.Model):
name=models.CharField(max_length=15)
age=models.IntegerField() class Meta:
db_table='author'
在创建第三张模型的时候也不用指定book的id和author的id,它会自动把两个模型的id字段写进去的
3,一对一关系
一个作者只能对应一个作者详细信息表,他们之间就是一对一关系,这和多对多一样的,关系写在哪张表都是可以的
class Author(models.Model):
name=models.CharField(max_length=15)
age=models.IntegerField()
author_info=models.OneToOneField('Author_Info',on_delete=models.CASCADE) 这是一对一关系创建,第二参数是,自动跟随删除,当作者不在了,随即作者的信息也会删除 class Meta:
db_table='author'
class Author_Info(models.Model):
gf_name=models.CharField(max_length=10)
telephone=models.IntegerField()
ShenFenZheng=models.IntegerField()
4,在此处我们可以使用Django的database:db.sqlite3
步骤如下:
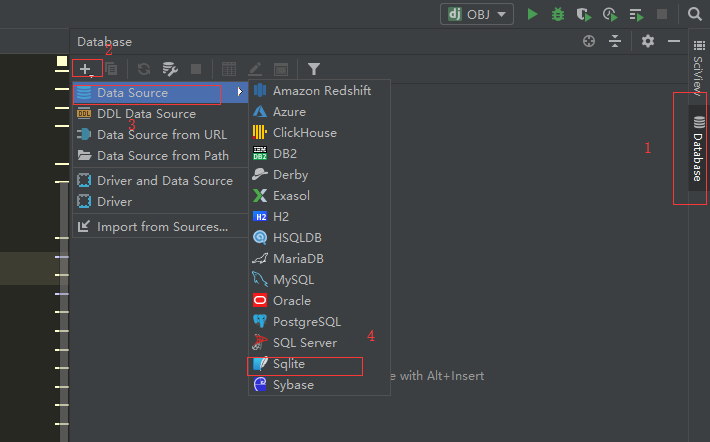
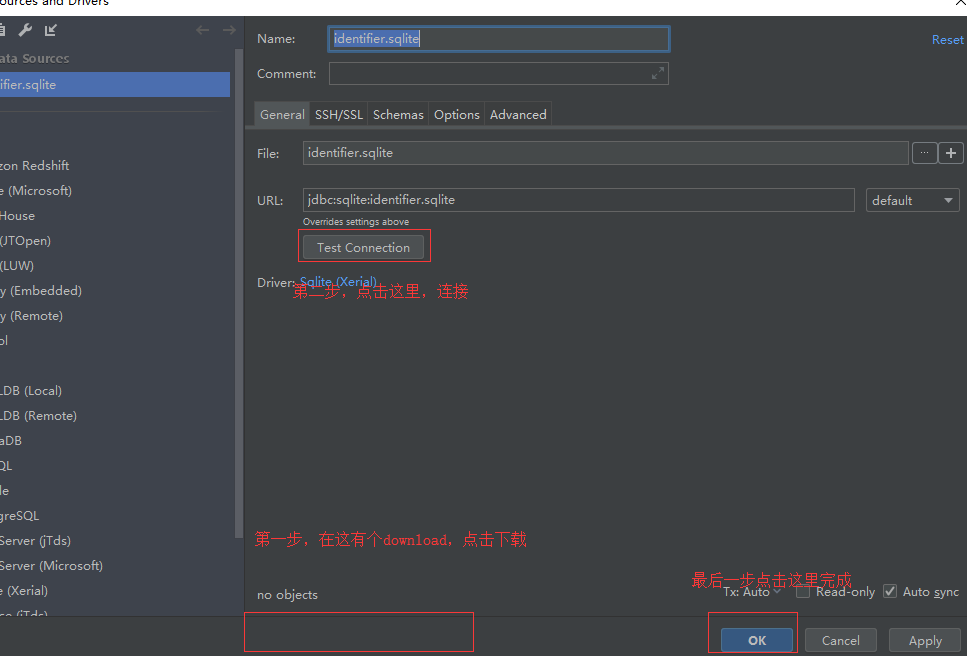
5,数据库迁移
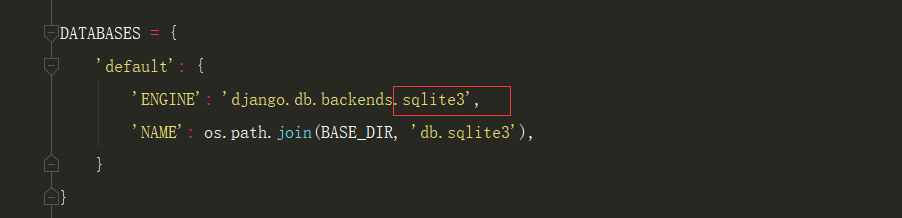
由于Django默认就是db.sqlite,所以我们不用去settings配置,也不需要在项目的__init__.py里写代码,现在只需要输入两条数据库迁移指令就行了
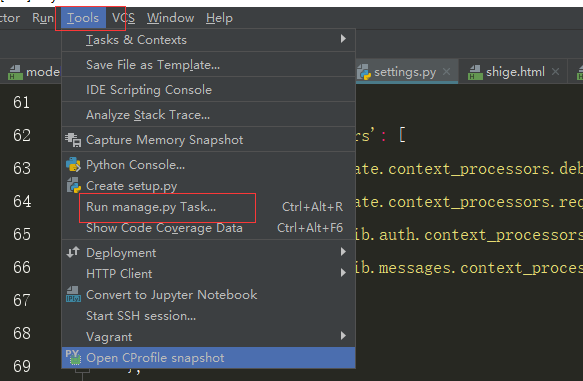
点击这里之后进入:
在这里数输入指令,就不需要写python manage.py了,因为已经进入到manage.py
现在输入makemigrations指令 #记录models.py文件发生的改变,然后在migrations文件夹下生产一个py文件,里面记录发生的变化 再输入migrate指令 #执行migrations文件下新变动的迁移文件,去更新数据库
到此,表就创建成功了。
二、添加表记录
1,一对多关系
之前我们创建了Book表和Publish表,两者就是一对多的关系,Book表是‘多’的一方,所以外键字段在Book表,Book表添加和之前的不一样,而‘一’的Publish表就是一张单表,和之前的一样,所以我们只要学习‘多’的一张Book表的添加就行了。添加表记录有两种方式。
1.1 按models.py里面Book类的属性来添加
pub=Publish.objects.all().filter(id=1).first() #首先找到id为1的Publish对象 book=Book.objects.create(name=name,price=price,publish=pub,pub_date=pub_date) #然后把这一对象赋值给Book类的publish属性
1.2 按数据库里面Book表的字段来添加
book=Book.objects.create(name=name,price=price,publish_id=1,pub_date=pub_date) #直接把Publish的id赋值给book表的publish_id就行了
2,多对多关系
之前我们创建了Book表和Author表,两者就是多对多关系,我是把多对多关系写在book表中的,所以从book去添加关联关系是正向的。
# 当前生成的书籍对象book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1)# 为书籍绑定的作者对象a1=Author.objects.filter(id=2).first() # 在Author表中主键为2的纪录a2=Author.objects.filter(id=1).first() # 在Author表中主键为1的纪录 # 绑定多对多关系,即向关系表book_authors中添加纪录,正向用属性,反向用表名_set 第一种,以Book为基表,因为多对多关系是写在Book中的,所以现在属于正向关联,用属性 book_obj.author.add(author1,author2) #这是给book_obj对象绑定上author1和author2两个对象。这里的author不是Author小写,而是Book类的一个属性 第二种,以Author为基表,因为多对多关系不是写在Author表,所以属于反向关联,用表名小写_set author_obj.book_set.add(book1,book2) #这是给author_obj对象绑定上book1和book2两个对象,但是这里book可不是Author类的属性,而且也没有这个属性,它是Book表小写后得到的 关系表的方法: 1,add()方法 参数可以是可以是n个模型类对象,如上面的写法 也可以是一个queryset集合,如author_list=Author.objects.filter(id__gt=2),这是找出id大于2的作者集合 book_obj.author.add(*author_list) 还可以是一个主键列表,如下面的写法 book_obj.author.add(*[1,3,4]) 2,remove()方法,移出关系方法 现在book1关联着author1和author2两个作者 book1.author.remove(author1) #此时book1就关联author2一个作者 反向也行author2.book_set.remove(book2) #把author2的关联书籍book2给移出 3,clear()方法,清空关系方法 book1.author.clear() #把book1的所有关联关系给删除,现在book1就没有关联作者了 author1.book_set.clear() 一样的,把author1的所有关联书籍的关联关系删除 4,set()方法,先把关联关系清空,再添加关联关系 假如book1关联着author1 book1.author.set(author2) 先把与author1的关联关系删除,然后再建立与author2的关联关系 假如author3关联着book1 author3.book_set.set(book2) 先把关联关系清空,再建立与book2的关联关系 5,=方法,赋值一个可迭代对象,关联关系会被整体替换 假如book1关联author1 new_list=[author2,author3] book1.author=new_list 这也会先把关联关系清空,然后把列表里的对象与book1建立关联关系
3,一对一关系
之前创建的Author表和Author_Info表之间就是一对一关系,我把关联字段写在了Author表中。
给Author类的属性赋值 info=Author_Info.objects.create(gf_name=gf_name,telephone=telephone,ShenFenZheng=ShenFenZheng) #这是创建了一条Author_Info记录,info就是一个Author_info对象 Author.objects.create(name=name,age=age,author_info=info) 把创建的info对象赋值给author_info属性 和一对多一样,也可以使用Author表的字段赋值 Author.objects.create(name=name,age=age,author_info_id=2)
三、基于对象的跨表查询(就是子查询)
1,一对多查询(Book与Publish)
1.1 正向查询(按属性:publish)
# 查询主键为1的书籍的出版社所在的城市book_obj=Book.objects.filter(pk=1).first()# book_obj.publish 是主键为1的书籍对象关联的出版社对象print(book_obj.publish.city)
1.2 反向查询(按表名小写_set:book_set)
publish=Publish.objects.get(name="苹果出版社")#publish.book_set.all() : 与苹果出版社关联的所有书籍对象集合book_list=publish.book_set.all() for book_obj in book_list: print(book_obj.title)
2,一对一查询(Author与Author_Info)
2.1 正向查询(按属性:author_info)
egon=Author.objects.filter(name="egon").first()print(egon.authorDetail.telephone)
2.2 反向查询(按表名小写:author)
# 查询所有住址在北京的作者的姓名 authorDetail_list=AuthorDetail.objects.filter(addr="beijing")for obj in authorDetail_list: print(obj.author.name)
3,多对多查询(Author与Book)
3.1 正向查询(按属性:author)
# 金瓶眉所有作者的名字以及手机号 book_obj=Book.objects.filter(title="金瓶眉").first() authors=book_obj.authors.all()for author_obj in authors: print(author_obj.name,author_obj.authorDetail.telephone)
3.2 反向查询(按表名小写_set:book_set)
# 查询egon出过的所有书籍的名字 author_obj=Author.objects.get(name="egon") book_list=author_obj.book_set.all() #与egon作者相关的所有书籍 for book_obj in book_list: print(book_obj.title)
4,related_name设置
可以通过Foreignkey和MangToMangField的定义中设置related_name的值来复写foo_set的名称。
publish=ForeignKey('Publish',related_name='booklist') #这样之后,反向就不用表名_set,就用booklist# 查询 人民出版社出版过的所有书籍publish=Publish.objects.get(name="人民出版社")
book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合四、基于双下划线的跨表查询
Django还提供了一种直观而高效的方式在查询中表示关联关系,它能自动确认sql join联系。要做跨关系查询,就使用两个下划线来链接模型间关联字段的名称,直到最终连接到想要的model为止。
正向查询按属性,反向查询按表名小写
1,一对多查询
# 练习: 查询苹果出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects
.filter(publish__name="苹果出版社")
.values_list("title","price") # 反向查询 按表名:book
queryResult=Publish.objects
.filter(name="苹果出版社")
.values_list("book__title","book__price")
2,多对多查询
# 练习: 查询alex出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects
.filter(authors__name="yuan")
.values_list("title") # 反向查询 按表名:book
queryResult=Author.objects
.filter(name="yuan")
.values_list("book__title","book__price")
3,一对一关系
# 查询alex的手机号
# 正向查询
ret=Author.objects.filter(name="alex").values("authordetail__telephone") # 反向查询
ret=AuthorDetail.objects.filter(author__name="alex").values("telephone")
4,进阶练习(连续跨表)
# 练习: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects
.filter(publish__name="人民出版社")
.values_list("title","authors__name") # 反向查询
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("book__title","book__authors__age","book__authors__name")# 练习: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称
# 方式1:
queryResult=Book.objects
.filter(authors__authorDetail__telephone__regex="151")
.values_list("title","publish__name") # 方式2:
ret=Author.objects
.filter(authordetail__telephone__startswith="151")
.values("book__title","book__publish__name")
五、聚合查询与分组查询
1,聚合
aggregate(*args,**kwargs)是Queryset的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是按照字段和聚合函数的名称自动生成出来的
计算所有图书的平均价格from django.db.models import Avg
Book.objects.all().aggregate(Avg('price'))
结果:{'price__avg': 34.35}
如果你想要为聚合值指定一个名称,可以向聚合函数前面用一个变量名来接收,此时,键的名称就变为接收的变量名
Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 34.35}
在终止子句里面可以放多个聚合函数,得到结果就是有多个键值对from django.db.models import Avg, Max, Min
Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
{'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
aggregate()只能对一个分组有用,对于按某字段分完组后的n个组,此时aggregate()就不能循环对每个分组作用,它只会得到第一组的结果
2,分组
2.1 单表分组查询
查询每一个部门名称以及对应的员工数
emp:
id name age salary dep1 alex 12 2000 销售部2 egon 22 3000 人事部3 wen 22 5000 人事部
emp.objects.values('dep').annotate(c=Count('*'))
values(‘dep’)就是按‘dep’进行分组
annotate()对每个分组的进行操作
2.2 多表分组查询
每一个出版社的名称和出版过的书籍个数
Publish.objects.values('name').annotate(c=Count('book')) #首先读整个语句,当读到‘book’时,就会把两个表连起来,然后在按Publish.name分组
跨表分组查询本质就是将关联表join成一张表,然后再按单表的思路进行分组查询
还有一种写法:
publishlist=Publish.objects.annotate(c=Count('book')) 这相当于给Publish表添加了一个‘c’字段。首先也是把两张表连起来,以Publish分组,计算每个Publish的书籍数量
publishlist是一个queryset对象集合,里面放的是publish模型类对象,只是现在的对象比之前多了一个‘c’字段
for publish in publishlist:
print(publish.name,publish.c) 利用for循环就可以遍历出每个模型类对象,然后用句点符‘.’就可以取得任何字段的值
我们也可以不用for循环,直接用values_list()就可以实现,如上面的for循环可以写成:values_list('name','c')
统计每一本书的作者个数
Book.objects.annotate(c=Count('author')).values_list('name','c')
filter()放在annotate()前面就是相当于where
统计每一本以py开头的书籍的作者的个数:
Book.objects.filter(name__startswith='py').annotate(c=Count('author')).values_list('name','c')
filter()放在annotate()后面就相当于having
统计作者个数大于1的书籍:
Book.objects.annotate(c=Count('author')).filter(c__gt=1).value_list('name','c')
根据书籍的作者数来排序:
Book.objects.annotate(c=Count('author')).orderby('c')
六、F查询与Q查询
1,F查询
在之前,对象的字段只能放在比较符的前面,比如filter(id__gt=2),但现在,有一个表,有生物成绩ss字段和物理成绩ws字段,统计物理成绩高于生物成绩的学生:
student.objects.filter(ws__gt=ss) 这样写肯定是报错的,因为字段写在了比较符后面,但此时我们借助F查询就可以不报错了,正确写法如下:
student.objcts.filter(ws__gt=F('ss')) F('ss')此时就是把ss字段的值取出来,就相当于一个纯数字了,可以进行加减乘除操作
查询物理成绩大于生物成绩两倍的学生
student.objects.filter(ws__gt=F('ss')*2)
把每个学生的物理成绩加上10分:
student.objects.all().update(ws=F('ws')+10)
2,Q查询
之前我们在用filter()时,可以用‘,’表示与关系,但没有或关系,现在我们用Q查询就可以实现或关系 Book.objects.filter(Q(id__gt=2)|Q(title__startswith='p')) 过滤出id大于2或者以‘p’开头的 Book.objects.filter(Q(id__gt=2)&Q(title__startswith='p')) 过滤出id大于2且以‘p’开头的 Book.objects.filter(Q(id__gt=2)|~Q(title__startswith='p')) 过滤出id大于2或不以‘p’开头的 Q查询可以和关键字参数混用,但Q()在前面 Book.objects.filter(Q(pub_date__year=2017)|Q(pub_date__year=2016),pub_date__month=2)过滤出2017年2月份或2016年2月份的书籍





