
字典类型简介
字典(dict)是存储key/value数据的容器,也就是所谓的map、hash、关联数组。无论是什么称呼,都是键值对存储的方式。
在python中,dict类型使用大括号包围:
D = {"key1": "value1",
"key2": "value2",
"key3": "value3"}dict对象中存储的元素没有位置顺序,所以dict不是序列,不能通过索引的方式取元素。dict是按照key进行存储的,所以需要通过key作为定位元素的依据,比如取元素或修改key对应的value。比如:
D['key1'] # 得到value1 D['key2'] # 得到value2 D['key3'] # 得到value3
字典的结构
dict是一个hashtable数据结构,除了数据类型的声明头部分,还主要存储了3部分数据:一个hash值,两个指针。下面详细解释dict的结构。
下面是一个Dict对象:
D = {"key1": "value1",
"key2": "value2",
"key3": "value3"}它的结构图如下:
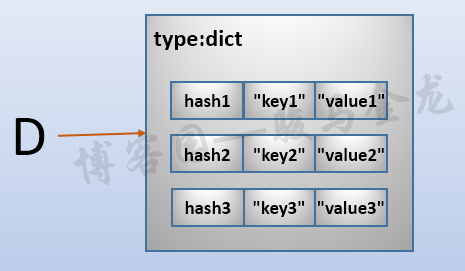
这个图很容易理解,key和value一一对应,只不过这里多加了一个hash值而已。但这只是便于理解的结构,它并非正确。看源码中对dict类型的简单定义。
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictKeyEntry;从源码中可知,一个hash值,这个hash值是根据key运用内置函数hash()来计算的,占用8字节(64位机器)。除了hash值,后面两个是指针,这两个指针分别是指向key、指向value的指针,每个指针占用一个机器字长,也即是说对于64位机器各占用8字节,所以一个dict的元素,除了实际的数据占用的内存空间,还额外占用24字节的空间。
所以,正确的结构图如下:
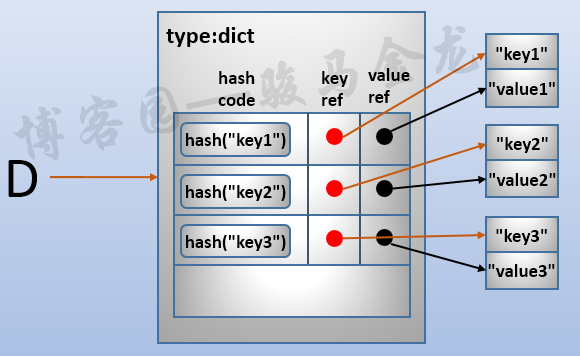
对于存储dict元素的时候,首先根据key计算出hash值,然后将hash值存储到dict对象中,与每个hash值同时存储的还有两个引用,分别是指向key的引用和指向value的引用。
如果要从dict中取出key对应的那个记录,则首先计算这个key的hash值,然后从dict对象中查找这个hash值,能找到说明有对应的记录,于是通过对应的引用可以找到key/value数据。
dict是可变的,可以删除元素、增加元素、修改元素的value。这些操作的过程与上面的过程类似,都是先hash,并根据hash值来存储或检索元素。
这里需要注意的是,在python中,能hashable的数据类型都必须是不可变类型的,所以列表、集合、字典不能作为dict的key,字符串、数值、元组都可以作为dict的key(类的对象实例也可以,因为自定义类的对象默认是不可变的)。
# 字符串作为key
>>> D = {"aa":"aa","bb":"bb"}
>>> D
{'aa': 'aa', 'bb': 'bb'}
# 数值作为key
>>> D = {1:"aa","bb":"bb"}
>>> D[1]
'aa'
# 元组作为key
>>> D = {(1,2):"aa","bb":"bb"}
>>> D
{(1, 2): 'aa', 'bb': 'bb'}
# 列表作为key,报错
>>> D = {[1,2]:"aa","bb":"bb"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'字典元素的顺序改变
因为元素存储到dict的时候,都经过hash()计算,且存储的实际上是key对应的hash值,所以dict中各个元素是无序的,或者说无法保证顺序。所以,遍历dict得到的元素结果也是无序的。
# python 3.5.2
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d
{'four': 4, 'two': 2, 'three': 3, 'one': 1}无序是理论上的。但是在python 3.7中,已经保证了python dict中元素的顺序和插入顺序是一致的。
Changed in version 3.7: Dictionary order is guaranteed to be insertion order. This behavior was an implementation detail of CPython from 3.6.
# python 3.7.1
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}虽保证了顺序,但后面介绍dict的时候,仍然将它当作无序来解释。
字典和列表的比较
python中list是元素有序存储的序列代表,dict是元素无序存储的代表。它们都可变,是python中最灵活的两种数据类型。
但是:
dict的元素检索、增删改速度快,不会随着元素增多、减少而改变。但缺点是内存占用大
list的元素检索、增删改速度随着元素增多会越来越慢(当然实际影响并没有多大),但是内存占用小
换句话说,dict是空间换时间,list是时间换空间。
其实从dict和list的数据结构上很容易可以看出dict要比list占用的内存大。不考虑存储元素的实际数据空间,list存储每个元素只需一个指针共8字节(64位机器)即可保存,而dict至少需要24字节(64位机器)。
构造字典
有几种构造字典的方式:
使用大括号包围
使用dict()构造方法,dict()构造有3种方式:
dict(key=value)
dict(DICT)
dict(iterable),其中iterable的每个元素必须是两元素的数据对象,例如
("one",1)、["two",2]后两种都可以结合第一种方式
使用dict对象的fromkey()方法
使用dict对象的copy()方法
字典解析的方式。这个在后文再解释
>>> D = {} # 空字典
>>> type(D)
<class 'dict'>
>>> D = {"key1": "value1",
"key2": "value2",
"key3": "value3"}
>>> D
{'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> f = dict([('two', 2), ('one', 1), ('three', 3)], four=4, five=5)fromkey(seq,value)是dict的类方法,所以可直接通过dict类名来调用(当然,使用已存在的对象来调用也没有问题)。它构造的字典的key来自于给定的序列,值来自于指定的第二个参数,如果没有第二个参数,则所有key的值默认为None。所以,第二个参数是构造新dict时的默认值。
例如,构造一个5元素,key全为数值的字典:
>>> dict.fromkeys(range(5))
{0: None, 1: None, 2: None, 3: None, 4: None}
>>> dict.fromkeys(range(5), "aa")
{0: 'aa', 1: 'aa', 2: 'aa', 3: 'aa', 4: 'aa'}再例如,根据已有的dict来初始化一个新的dict:
>>> d = dict(one=1, two=2, three=3, four=4, five=5)
>>> dict.fromkeys(d)
{'one': None, 'two': None, 'three': None, 'four': None, 'five': None}
>>> dict.fromkeys(d, "aa")
{'one': 'aa', 'two': 'aa', 'three': 'aa', 'four': 'aa', 'five': 'aa'}因为key的来源可以是任意序列,所以也可以从元组、列表、字符串中获取。
>>> dict.fromkeys("abcd","aa")
{'a': 'aa', 'b': 'aa', 'c': 'aa', 'd': 'aa'}
>>> L = ["a", "b", "c", "d"]
>>> dict.fromkeys(L)
{'a': None, 'b': None, 'c': None, 'd': None}
>>> T = ("a", "b", "c", "d")
>>> dict.fromkeys(L)
{'a': None, 'b': None, 'c': None, 'd': None}dict的copy()方法会根据已有字典完全拷贝成一个新的字典副本。但需要注意的是,拷贝过程是浅拷贝。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> dd = d.copy()
>>> dd
{'three': 3, 'one': 1, 'two': 2, 'four': 4}
>>> id(d["one"]), id(dd["one"])
(10919424, 10919424)操作字典
官方手册:https://docs.python.org/3/library/stdtypes.html#mapping-types-dict
dict的增删改查
通过key即可检索到元素。
>>> d
{'one': 1, 'two': 2, 'three': 3}
>>> d["one"]
1
>>> d["four"] = 4
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d["ten"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'ten'对于dict类型,检索不存在的key时会报错。但如果自己去定义dict的子类,那么可以自己重写__missing__()方法来决定检索的key不存在时的行为。例如,对于不存在的键总是返回None。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> class mydict(dict):
... def __missing__(self, key):
... return None
...
>>> dd = mydict(d)
>>> dd
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> dd["ten"]
>>> print(dd["ten"])
Noneget(key,default)方法检索dict中的元素,如果元素存在,则返回对应的value,否则返回指定的default值,如果没有指定default,且检索的key又不存在,则返回None。这正好是上面自定义dict子类的功能。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d.get("two")
2
>>> d.get("six","not exists")
'not exists'
>>> print(d.get("six"))
Nonelen()函数可以用来查看字典有多少个元素:
>>> d
{'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> len(d)
4setdefault(key,default)方法检索并设置一个key/value,如果key已存在,则直接返回对应的value,如果key不存在,则新插入这个key并指定其value为default并返回这个default,如果没有指定default,key又不存在,则默认为None。
>>> d.setdefault("one")
1
>>> d.setdefault("five")
{'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': None}
>>> d.setdefault("six",6)
6
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': None, 'six': 6}update(key/value)方法根据给定的key/value对更新已有的键,如果键不存在则新插入。key/value的表达方式有多种,只要能表达出key/value的配对行为就可以。比如已有的dict作为参数,key=value的方式,2元素的迭代容器对象。
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d.update(five=5, six=6) # key=value的方式
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': 5, 'six': 6}
>>> d.update({"one":11, "two":22}) # dict作为参数
>>> d
{'one': 11, 'two': 22, 'three': 3, 'four': 4, 'five': 5, 'six': 6}
>>> d.update([("five",55),("six",66)]) # 列表中2元素的元组
>>> d
{'one': 11, 'two': 22, 'three': 3, 'four': 4, 'five': 55, 'six': 66}
>>> d.update((("five",55),("six",66))) # 这些都可以
>>> d.update((["five",55],["six",66]))
>>> d.update(zip(["five","six"],[55,66]))del D[KEY]可以用来根据key删除字典D中给定的元素,如果元素不存在则报错。
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> del d["four"]
>>> d
{'three': 3, 'two': 2, 'one': 1}
>>> del d["five"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'five'clear()方法用来删除字典中所有元素。
>>> d = {'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.clear()
>>> d
{}pop(key,default)用来移除给定的元素并返回移除的元素。但如果元素不存在,则返回default,如果不存在且没有给定default,则报错。
>>> d = {'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.pop("one")
1
>>> d.pop("five","hello world")
'hello world'
>>> d.pop("five")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'five'popitem()用于移除并返回一个(key,value)元组对,每调用一次移除一个元素,没元素可移除后将报错。在python 3.7中保证以LIFO的顺序移除,在此之前不保证移除顺序。
例如,下面是在python 3.5中的操作时(不保证顺序):
>>> d
{'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.popitem()
('three', 3)
>>> d.popitem()
('four', 4)
>>> d.popitem()
('two', 2)
>>> d.popitem()
('one', 1)
>>> d.popitem()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'popitem(): dictionary is empty'测试
通过d[key]的方式检索字典中的某个元素时,如果该元素不存在将报错。使用get()方法可以指定元素不存在时的默认返回值,而不报错。而设置元素时,可用通过直接赋值的方式,也可以通过setdefault()方法来为不存在的值设置默认值。
重点在于元素是否存在于字典中。上面的几种方法能在检测元素是否存在时做出对应的操作,但字典作为容器,也可以直接用in和not in去测试元素的存在性。
>>> "one" in d True >>> "one3" in d False >>> "one3" not in d True
迭代和dict视图
keys()返回字典中所有的key组成的视图对象;
values()返回字典中所有value组成的视图对象;
items()返回字典中所有(key,value)元组对组成的视图对象;
iter(d)函数返回字典中所有key组成的可迭代对象。等价于
iter(d.keys())
前3个方法返回的是字典视图对象,关于这个稍后再说。先看返回结果:
>>> d
{'three': 3, 'four': 4, 'two': 2, 'one': 1}
>>> d.keys()
dict_keys(['three', 'four', 'two', 'one'])
>>> list(d.keys())
['three', 'four', 'two', 'one']
>>> d.values()
dict_values([3, 4, 2, 1])
>>> d.items()
dict_items([('three', 3), ('four', 4), ('two', 2), ('one', 1)])iter(d)返回的是由key组成的可迭代对象。
>>> iter(d) <dict_keyiterator object at 0x7f0ab9c9c4f8> >>> for i in iter(d):print(i) ... three four two one
既然这些都返回key、value、item组成的"列表"对象(视图对象),那么可以直接拿来迭代遍历。
>>> for i in d.keys(): ... print(i) ... three four two one >>> for i in d.values(): ... print(i) ... 3 4 2 1 >>> for (key,value) in d.items(): ... print(key,"-->",value) ... three --> 3 four --> 4 two --> 2 one --> 1
dict视图对象
keys()、values()、items()返回字典视图对象。视图对象中的数据会随着原字典的改变而改变。如果知道关系型数据库里的视图,这很容易理解。
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> d.keys()
dict_keys(['one', 'two', 'three', 'four'])
>>> list(d.keys())
['one', 'two', 'three', 'four']字典视图对象是可迭代对象,可以用来一个个地生成对应数据,但它毕竟不是列表。如果需要得到列表,只需使用list()方法构造即可。
>>> list(d.keys()) ['one', 'two', 'three', 'four']
因为字典试图是可迭代对象,所以可以进行测试存在性、迭代、遍历等。
KEY in d.keys() for key in d.keys(): ... for value in d.values(): ... for (key, value) in d.items(): ...
字典的视图对象有两个函数:
len(obj_view):返回视图对象的长度
iter(obj_view):返回视图对象对应的可迭代对象
>>> len(d.keys()) 4 >>> iter(d.keys()) <dict_keyiterator object at 0x000001F0A7D9A9F8>
注意,字典视图对象是可迭代对象,但并不是实际的列表,所以不能使用sort方法来排序,但可以使用sorted()内置函数来排序(按照key进行排序)。
最后,视图对象是随原始字典动态改变的。修改原始字典,视图也会改变。例如:
>>> d = {'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> ks = d.keys()
>>> del d["one"]
>>> k
dict_keys(['two', 'three', 'four'])字典迭代和解析
字典自身有迭代器,如果需要迭代key,则不需要使用keys()来间接迭代。所以下面是等价的:
for key in d:for key in d.keys()
关于字典解析,看几个示例即可理解:
>>> d = {k:v for (k,v) in zip(["one","two","three"],[1,2,3])}
>>> d
{'one': 1, 'two': 2, 'three': 3}
>>> d = {x : x ** 2 for x in [1,2,3,4]}
>>> d
{1: 1, 2: 4, 3: 9, 4: 16}
>>> d = {x : None for x in "abcde"}
>>> d
{'a': None, 'b': None, 'c': None, 'd': None, 'e': None}
转载请注明出处:https://www.cnblogs.com/f-ck-need-u/p/10159432.html





