
MySQL作为迭代了很多个版本的数据库。在数据库的索引上实现了很多的优化版本,从一开始的只允许一个表有一个列为索引值,到目前版本可支持多个列建立索引值,更多关于索引优化版本的描述,以后有机会笔者再写一篇文章。本文主要介绍索引当中的聚簇索引。
MySQL官方对聚簇索引的定义是,聚簇索引并不是一种单独的索引类,而是一种数据存储方式,第一次看到这段描述,我相信很多人都会一头雾水,索引是一种数据存储结构?这怎么解释?下面笔者一步一步来讲述MySQL对聚簇索引的定义和具体运用。
首先上贴一张图
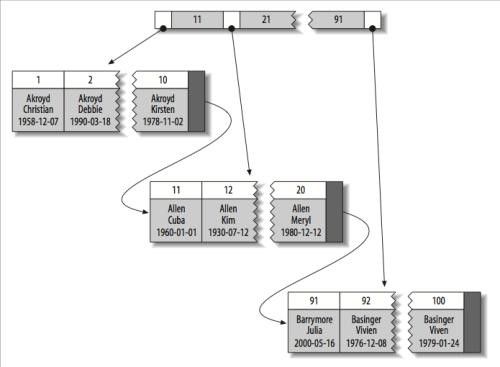
在MySQL中,有一列值,专门被设定为聚簇索引,这列值就是主键,通常为数字类型的字段。那么如果数据表中没有主键呢?MySQL的解决办法是隐式地将一个唯一的非空的列定义为聚簇。那如果这也没有呢?MySQL就自己创建一个聚簇索引,具体这个聚簇索引内部是怎么建立的,笔者还需要去学习学习。反正无论如何,MySQL都会创建一个聚簇索引。
那么为什么说聚簇索引是一种数据存储结构呢?原因是MySQL将索引(即主键)对应的每一条记录都以链表的形式存储在索引的叶子页中,那么很容易理解,聚簇索引就是表,而反过来说,表以聚簇索引的形式来存储。那么是所有的MySQL存储引擎都采用聚簇索引这种数据存储结构吗?答案是否定的,在MySQL中,只用Innodb引擎才采用聚簇索引,其他的存储引擎像MyISAM采用非聚簇索引。
那么接下来的问题是聚簇索引有什么优势,它的这种优势是因为什么产生的?本人学习过程中总结了以下几点。
1. 采用聚簇索引,索引和其他列值存储在一起,在查询过程中利用B-Tree查询,搜寻速率很快。而采用非聚簇索引(如MyISAM引擎),在查询上比Innodb相对要慢得多。
2. 聚簇索引内部实现了将相类似的数据存放在一起,当需要查询相类似的内容时,只需要查询比较少的数据页就可以实现对数据的获取。
为了理解第一点优势,我们还需要去理解二级索引的一些相关问题。
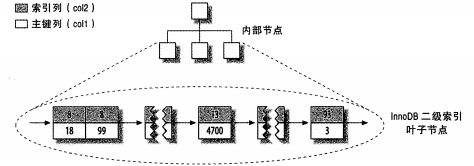
在Innodb中,二级索引除了存储本身的列值外,其叶子节点存储的不是‘行指针’,而是主键值,为什么是这样呢?原来这种方式在表结构发生变化的时候会有很大的优势。如果二级索引的存储顺序是以列值为基础的,那么在发生数据行的移动或者增加删除时候,必定会引起索引结构的巨大变化,举个例子:在MyISAM存储引擎的表结构,索引的存储顺序是以数值大小或者字符串的字母为基准的,如果有这么一列数据age是数字类型,当其中的一条数据的age改变之后,跟在它后面的数据的顺序要重新排列,修改后的数据插入原来的表中也需要花费一番功夫。而Innodb的优势在于,以主键为顺序(通常主键是没有任何实际意义的一列自增的数值),因为主键是顺序的,自增的,就不会出现说因为二级索引值的改变而使一条数据在表中移动过程中产生巨大影响甚至改变了表的结构。但有一个缺点是Innodb的二级索引的这类指针会加大了二级索引的存储空间。当数据量很大的时候,还是会有一定的空间压力的。
下图是Innodb存储引擎的二级索引储存结构。
图片介绍:keycolumns为二级索引(灰色行),primarykey为主键索引(白色行)
上面还提到了一点,主键是一列自增的数值。那么主键是否自增对索引的结构产生影响呢?
MySQL官方在这个问题上建议数据库管理者和应用开发者使用自增的索引,原因是如果使用非自增的索引和不确定长度的索引,会在数据库写入大量数据的时候产生很大的性能问题。
因为数据的写入顺序是不确定的,数据需要在原表中寻找一个位置插入,而这个位置通常不是在已有数据的最后,可能是中间,这样会增加很多额外的工作。同时,因为写入的位置不确定会使表频繁的分页和产生较多的空索引值或者说索引值之间产生很大的空隙,即产生了大量的碎片。这样一来,对数据的写入操作就会产生很大的性能问题。
下面放MyISAM存储引擎的图片作为和Innodb存储引擎对比
MyISAM存储引擎
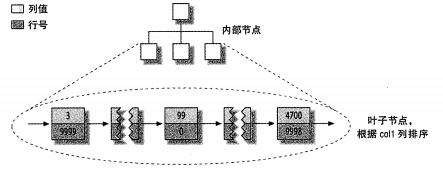
从图片可以看出,MyISAM的二级索引是以具体的列值为顺序进行
下面两张图比较形象地对两种存储引擎的主键索引和二级索引的指针指向作了一个对比
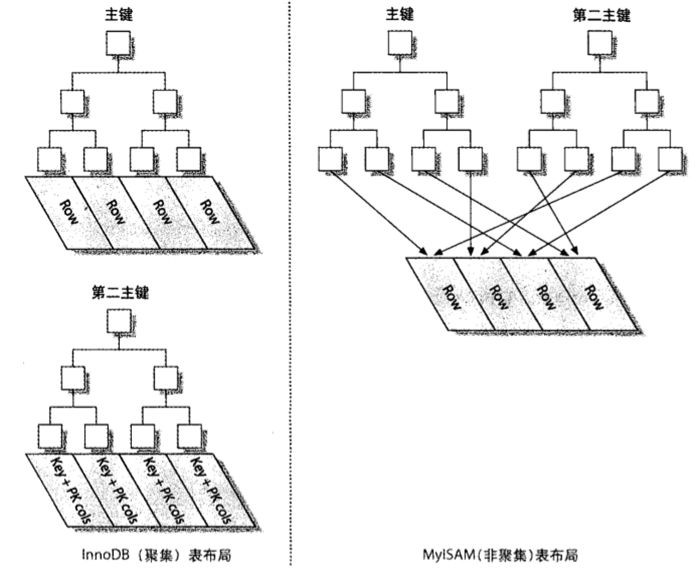
回归到问题的最初点—为什么采用聚簇索引查询速度会更快?原因是聚簇索引的每一个索引值的叶子节点就为数据,只要查询到对应的主键索引值,就可以查询到对应的哪一行数据,读取速度相对来说提升了不少。而MyISAM需要特别为索引创建存储空间来存放,在查询过程中还要到磁盘中进行数据的读取。
相对来说聚簇索引的第二个优势就很好理解了,例如一个关于会员的表记录了会员的id值,姓名,年龄,性别和手机号,假设手机号是二级索引,在存储二级索引的时候,会将手机号码开头几位数字相似的手机号存放在一起,例如以135和170开头的手机号会分在不同的索引表中。在查询的过程中可以对二级索引的查询,快速查到手机号以135开头的那部分会员的信息。而在非聚簇索引表中(MyISAM存储引擎),主键索引和二级索引互相影响(如上图),在查询过程就很难实现优化了。
以上是本人对聚簇索引和非聚簇索引的应用场景和优劣势的对比。另外聚簇索引有时候也会跟覆盖索引拿出来一起比较,实际上两种索引是不同的概念,前者描述的是一种数据存储的结构,后者是描述在数据查询中直接对索引值的查询的过程。而在实现的结构基础上,聚簇索引是基于主键列的,覆盖索引是基于非主键列的任何数据列。
作者:四两逻辑
原文地址:https://www.cnblogs.com/thomson-fred/p/9827777.html







热门评论
-

Nothing4313402018-12-18 0
查看全部评论查询是利用b+tree吧