
前言
最近看Apache Spark社区2.2之后Structured Streaming也已经走上了Production Ready日程,再加之SPIP: Continuous Processing Mode for Structured Streaming真正流式执行引擎的加持,Spark在流式计算领域有了真正值得一试的资本,再加上SparkSession可以离线、流式、机器学习等计算模型统一入口。俗话说,有入口有用户,才有未来。是时候来一发源码级别的了解了。
阅读源码方式最好的就是word count这种简单得不能再简单的case了,闲话少说,抛出示例代码,开始分析。
import org.apache.spark.sql.SparkSessionobject WordCount extends App { val spark = SparkSession
.builder()
.appName("StructuredNetworkWordCount")
.getOrCreate() import spark.implicits._ // represents an unbounded table containing the streaming text data
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load() val words = lines.as[String].flatMap(_.split(" ")) val wordCounts = words.groupBy("value").count() val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
}import
import org.apache.spark.sql.SparkSession
既然统一以SparkSession为入口,当然最先就该导入SparkSession依赖
以Maven工程为例,就应该在pom文件中添加对应${spark.version}的spark sql module的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>创建SparkSession
val spark = SparkSession
.builder()
.appName("StructuredNetworkWordCount")
.getOrCreate()这部分用以初始化一个SparkSession的实例,和普通的2.x的Spark程序并无区别。在此不再赘述。
再次Import
import spark.implicits._
导入一些隐式转换,比如和schema相关的encoder,df和ds转换的方法等。
创建输入
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()可以看到一切的开始还是作为SparkSession实例的spark变量,终于要看源码了,好激动,在此之前先git log看下记下是哪个commit下的源码,不然以后变了或者看了更老的代码就牛头不对马嘴了。
git log -1 commit 209b9361ac8a4410ff797cff1115e1888e2f7e66 Author: Bryan Cutler <cutlerb@gmail.com> Date: Mon Nov 13 13:16:01 2017 +0900
进入SparkSession, 看下readStream方法做了啥?
/**
* Returns a `DataStreamReader` that can be used to read streaming data in as a `DataFrame`.
* {{{
* sparkSession.readStream.parquet("/path/to/directory/of/parquet/files")
* sparkSession.readStream.schema(schema).json("/path/to/directory/of/json/files")
* }}}
*
* @since 2.0.0
*/
@InterfaceStability.Evolving
def readStream: DataStreamReader = new DataStreamReader(self)返回一个用于读取流式数据的DataStreamReader实例,离线开发的时候我们用的是read方法返回一个DataDrameReader的实例,可以看到流式计算和离线计算在这里开始分开旅行。
然后调用DataStreamReader的format方法。
/**
* Specifies the input data source format.
*
* @since 2.0.0
*/
def format(source: String): DataStreamReader = { this.source = source this
}用以指定输入数据的格式, 这必然和load数据时的DataSource API有关,应该是用对应的名字映射成该数据格式的Class类型对象。
接着以option方法指定两个参数host 和 port,
/**
* Adds an input option for the underlying data source.
*
* You can set the following option(s):
* <ul>
* <li>`timeZone` (default session local timezone): sets the string that indicates a timezone
* to be used to parse timestamps in the JSON/CSV datasources or partition values.</li>
* </ul>
*
* @since 2.0.0
*/
def option(key: String, value: String): DataStreamReader = { this.extraOptions += (key -> value) this
}实际就是往DataStreamReader的成员变量extraOptions里加了些属性,看注释知个大概,实际用以指定DataSource接口的某些输入参数。目前还不知host和port参数的实际作用。
接着看load方法,
/**
* Loads input data stream in as a `DataFrame`, for data streams that don't require a path
* (e.g. external key-value stores).
*
* @since 2.0.0
*/
def load(): DataFrame = { if (source.toLowerCase(Locale.ROOT) == DDLUtils.HIVE_PROVIDER) { throw new AnalysisException("Hive data source can only be used with tables, you can not " + "read files of Hive data source directly.")
}
val dataSource =
DataSource(
sparkSession,
userSpecifiedSchema = userSpecifiedSchema,
className = source,
options = extraOptions.toMap)
Dataset.ofRows(sparkSession, StreamingRelation(dataSource))
}前面所调用的方法都是返回reader自身实例,本方法返回一个df,我们知道在离线计算中spark都是预定义的模式,这个过程都不会“起job进行运算”(注解1)。这同样适用在Structured Streaming中。load方法中我们实例化了一个dataSource变量,并由
/**
* Used to link a streaming [[DataSource]] into a
* [[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]]. This is only used for creating
* a streaming [[org.apache.spark.sql.DataFrame]] from [[org.apache.spark.sql.DataFrameReader]].
* It should be used to create [[Source]] and converted to [[StreamingExecutionRelation]] when
* passing to [[StreamExecution]] to run a query.
*/case class StreamingRelation(dataSource: DataSource, sourceName: String, output: Seq[Attribute])
extends LeafNode {
...
}转化为LogicalPlan,最后调用Dataset方法,
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = { val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed() new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
}完成了DataFrame的初步预定义。到这一看除了输入不一样,处理方式不会和离线也一样吧,那不是处理一次就瞎了,别急。让我们往里面瞅瞅,先看下val qe = sparkSession.sessionState.executePlan(logicalPlan), 可以看到
def executePlan(plan: LogicalPlan): QueryExecution = createQueryExecution(plan)
这里createQueryExecution: LogicalPlan => QueryExecution是一枚函数,将logicalplan转换为QueryExecution, 离线sql中这玩意就是其执行整个workflow,那流sql也就同理了。既然起作为sparkSession.sessionState的一枚成员变量,那我们就先看看它是怎么被定义的,首先
/**
* State isolated across sessions, including SQL configurations, temporary tables, registered
* functions, and everything else that accepts a [[org.apache.spark.sql.internal.SQLConf]].
* If `parentSessionState` is not null, the `SessionState` will be a copy of the parent.
*
* This is internal to Spark and there is no guarantee on interface stability.
*
* @since 2.2.0
*/
@InterfaceStability.Unstable
@transient
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse { val state = SparkSession.instantiateSessionState( SparkSession.sessionStateClassName(sparkContext.conf),
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}上面是sessionState的初始过程,看下SparkSession.instantiateSessionState里面干了啥,
/**
* Helper method to create an instance of `SessionState` based on `className` from conf.
* The result is either `SessionState` or a Hive based `SessionState`.
*/
private def instantiateSessionState(
className: String,
sparkSession: SparkSession): SessionState = { try { // invoke `new [Hive]SessionStateBuilder(SparkSession, Option[SessionState])`
val clazz = Utils.classForName(className) val ctor = clazz.getConstructors.head
ctor.newInstance(sparkSession, None).asInstanceOf[BaseSessionStateBuilder].build()
} catch { case NonFatal(e) => throw new IllegalArgumentException(s"Error while instantiating '$className':", e)
}
}通过java反射方式实例化一个BaseSessionStateBuilder的子类,然后调用build方法,返回一个SessionState实例,
/**
* Build the [[SessionState]].
*/
def build(): SessionState = { new SessionState(
session.sharedState,
conf,
experimentalMethods,
functionRegistry,
udfRegistration,
() => catalog,
sqlParser,
() => analyzer,
() => optimizer,
planner,
streamingQueryManager,
listenerManager,
() => resourceLoader,
createQueryExecution,
createClone)
}代码倒数第二行我们看到了久违的createQueryExecution参数,
/**
* Create a query execution object.
*/
protected def createQueryExecution: LogicalPlan => QueryExecution = { plan => new QueryExecution(session, plan)
}看了下QueryExecution定义,及其子类IncrementalExecution,
/** * A variant of [[QueryExecution]] that allows the execution of the given [[LogicalPlan]] * plan incrementally. Possibly preserving state in between each execution. */class IncrementalExecution( sparkSession: SparkSession, logicalPlan: LogicalPlan, val outputMode: OutputMode, val checkpointLocation: String, val runId: UUID, val currentBatchId: Long, val offsetSeqMetadata: OffsetSeqMetadata) extends QueryExecution(sparkSession, logicalPlan) with Logging
豁然开朗,看来我们这边是走错了,接下来的目的就是看我们的case中如何触发了这个类的实例化了。
回到load方法里面,我们看到
Dataset.ofRows(sparkSession, StreamingRelation(dataSource))
这边的logical plan 我们接收的是一个StreamingRelation, 其有个关键的标志
override def isStreaming: Boolean = true
猜测流式执行还是离线执行必然是放在了规则器里了,那我就先记下,等等回来再看,为啥?因为我们的逻辑计划还只生成了一段,必然还不涉及到query execution相关的操作,等我把整个sql执行计划定义完了,我们在回来看不迟。
Transformations
val words = lines.as[String].flatMap(_.split(" "))val wordCounts = words.groupBy("value").count()在我们的case中,我们对我们的df进行了一系列transformation操作,这个和spark sql中的离线计算一毛一样,就不赘述了,最后
/** * Count the number of rows for each group. * The resulting `DataFrame` will also contain the grouping columns. * * @since 1.3.0 */ def count(): DataFrame = toDF(Seq(Alias(Count(Literal(1)).toAggregateExpression(), "count")()))
依然返回熟悉的DataFrame。
到此为止,我们完成了我们plan的预定义.
寻找流式执行的最后稻草
最后一两句代码了,spark缺点太大了,写个分布式的app就这么几行代码,我觉得在讲不清楚,我就要卷铺盖走人了。
回头看看程序代码
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()先看看wordCounts.writeStream,
/**
* Interface for saving the content of the streaming Dataset out into external storage.
*
* @group basic
* @since 2.0.0
*/
@InterfaceStability.Evolving
def writeStream: DataStreamWriter[T] = { if (!isStreaming) {
logicalPlan.failAnalysis( "'writeStream' can be called only on streaming Dataset/DataFrame")
} new DataStreamWriter[T](this)
}已经要把dataset落存储了啊,我是不是漏掉了神马?好方!!
还是得回来一步步往下走,DataStreamWriter的outputMode
/**
* Specifies how data of a streaming DataFrame/Dataset is written to a streaming sink.
* - `OutputMode.Append()`: only the new rows in the streaming DataFrame/Dataset will be
* written to the sink
* - `OutputMode.Complete()`: all the rows in the streaming DataFrame/Dataset will be written
* to the sink every time these is some updates
* - `OutputMode.Update()`: only the rows that were updated in the streaming DataFrame/Dataset
* will be written to the sink every time there are some updates. If
* the query doesn't contain aggregations, it will be equivalent to
* `OutputMode.Append()` mode.
*
* @since 2.0.0
*/
def outputMode(outputMode: OutputMode): DataStreamWriter[T] = { this.outputMode = outputMode this
}设定下sink的模式,目前支持complete, append, update,就是字面意思,对应sink的语义上也很好理解。
接着调用.format("console")
/**
* Specifies the underlying output data source.
*
* @since 2.0.0
*/
def format(source: String): DataStreamWriter[T] = { this.source = source this
}对应source 我们有数据格式,sink我们也有对应的格式,这边我们选择的是console,直接打印到控制台。
最后了,调用.start(),代码挺多的,看来有戏,
/**
* Starts the execution of the streaming query, which will continually output results to the given
* path as new data arrives. The returned [[StreamingQuery]] object can be used to interact with
* the stream.
*
* @since 2.0.0
*/
def start(): StreamingQuery = { if (source.toLowerCase(Locale.ROOT) == DDLUtils.HIVE_PROVIDER) { throw new AnalysisException("Hive data source can only be used with tables, you can not " + "write files of Hive data source directly.")
} if (source == "memory") {
assertNotPartitioned("memory") if (extraOptions.get("queryName").isEmpty) { throw new AnalysisException("queryName must be specified for memory sink")
} val sink = new MemorySink(df.schema, outputMode) val resultDf = Dataset.ofRows(df.sparkSession, new MemoryPlan(sink)) val chkpointLoc = extraOptions.get("checkpointLocation") val recoverFromChkpoint = outputMode == OutputMode.Complete() val query = df.sparkSession.sessionState.streamingQueryManager.startQuery(
extraOptions.get("queryName"),
chkpointLoc,
df,
sink,
outputMode,
useTempCheckpointLocation = true,
recoverFromCheckpointLocation = recoverFromChkpoint,
trigger = trigger)
resultDf.createOrReplaceTempView(query.name)
query
} else if (source == "foreach") {
assertNotPartitioned("foreach") val sink = new ForeachSink[T](foreachWriter)(ds.exprEnc)
df.sparkSession.sessionState.streamingQueryManager.startQuery(
extraOptions.get("queryName"),
extraOptions.get("checkpointLocation"),
df,
sink,
outputMode,
useTempCheckpointLocation = true,
trigger = trigger)
} else { val dataSource = DataSource(
df.sparkSession,
className = source,
options = extraOptions.toMap,
partitionColumns = normalizedParCols.getOrElse(Nil))
df.sparkSession.sessionState.streamingQueryManager.startQuery(
extraOptions.get("queryName"),
extraOptions.get("checkpointLocation"),
df,
dataSource.createSink(outputMode),
outputMode,
useTempCheckpointLocation = source == "console",
recoverFromCheckpointLocation = true,
trigger = trigger)
}
}好吧,我以为写scala的都讨厌用if else,我么指定的source是console直接走到else分支。
首先,我们看到实例化了一个DataSource API, 回想在先前的reader里也见过一个,有头有尾,不错。
通知我们这边也看到了dataSource.createSink(outputMode), 开头的读也有了,尾巴的写也有了,就差一个东西将两者以流式的方式串联起来了
接下来,看看sparkSession.sessionState.streamingQueryManager,这货在实例化sessionState时见过一面,当时没留意,再看看看。。
/** * Interface to start and stop streaming queries. */ protected def streamingQueryManager: StreamingQueryManager = new StreamingQueryManager(session)
注释一目了然,那么逻辑自然在startQuery方法里面了,
/**
* Start a [[StreamingQuery]].
*
* @param userSpecifiedName Query name optionally specified by the user.
* @param userSpecifiedCheckpointLocation Checkpoint location optionally specified by the user.
* @param df Streaming DataFrame.
* @param sink Sink to write the streaming outputs.
* @param outputMode Output mode for the sink.
* @param useTempCheckpointLocation Whether to use a temporary checkpoint location when the user
* has not specified one. If false, then error will be thrown.
* @param recoverFromCheckpointLocation Whether to recover query from the checkpoint location.
* If false and the checkpoint location exists, then error
* will be thrown.
* @param trigger [[Trigger]] for the query.
* @param triggerClock [[Clock]] to use for the triggering.
*/
private[sql] def startQuery(
userSpecifiedName: Option[String],
userSpecifiedCheckpointLocation: Option[String],
df: DataFrame,
sink: Sink,
outputMode: OutputMode,
useTempCheckpointLocation: Boolean = false,
recoverFromCheckpointLocation: Boolean = true,
trigger: Trigger = ProcessingTime(0),
triggerClock: Clock = new SystemClock()): StreamingQuery = { val query = createQuery(
userSpecifiedName,
userSpecifiedCheckpointLocation,
df,
sink,
outputMode,
useTempCheckpointLocation,
recoverFromCheckpointLocation,
trigger,
triggerClock)
activeQueriesLock.synchronized { // Make sure no other query with same name is active
userSpecifiedName.foreach { name => if (activeQueries.values.exists(_.name == name)) { throw new IllegalArgumentException( s"Cannot start query with name $name as a query with that name is already active")
}
} // Make sure no other query with same id is active
if (activeQueries.values.exists(_.id == query.id)) { throw new IllegalStateException( s"Cannot start query with id ${query.id} as another query with same id is " + s"already active. Perhaps you are attempting to restart a query from checkpoint " + s"that is already active.")
}
activeQueries.put(query.id, query)
} try { // When starting a query, it will call `StreamingQueryListener.onQueryStarted` synchronously.
// As it's provided by the user and can run arbitrary codes, we must not hold any lock here.
// Otherwise, it's easy to cause dead-lock, or block too long if the user codes take a long
// time to finish.
query.streamingQuery.start()
} catch { case e: Throwable =>
activeQueriesLock.synchronized {
activeQueries -= query.id
} throw e
}
query
}参数很多,我们也没用到几个,先不看。
方法逻辑是我小学写作文用的三短文结构,1、创建query 2、校验query 3、start
创建query
private def createQuery(
userSpecifiedName: Option[String],
userSpecifiedCheckpointLocation: Option[String],
df: DataFrame,
sink: Sink,
outputMode: OutputMode,
useTempCheckpointLocation: Boolean,
recoverFromCheckpointLocation: Boolean,
trigger: Trigger,
triggerClock: Clock): StreamingQueryWrapper = { var deleteCheckpointOnStop = false
val checkpointLocation = userSpecifiedCheckpointLocation.map { userSpecified => new Path(userSpecified).toUri.toString
}.orElse {
df.sparkSession.sessionState.conf.checkpointLocation.map { location => new Path(location, userSpecifiedName.getOrElse(UUID.randomUUID().toString)).toUri.toString
}
}.getOrElse { if (useTempCheckpointLocation) { // Delete the temp checkpoint when a query is being stopped without errors.
deleteCheckpointOnStop = true
Utils.createTempDir(namePrefix = s"temporary").getCanonicalPath
} else { throw new AnalysisException( "checkpointLocation must be specified either " + """through option("checkpointLocation", ...) or """ + s"""SparkSession.conf.set("${SQLConf.CHECKPOINT_LOCATION.key}", ...)""")
}
} // If offsets have already been created, we trying to resume a query.
if (!recoverFromCheckpointLocation) { val checkpointPath = new Path(checkpointLocation, "offsets") val fs = checkpointPath.getFileSystem(df.sparkSession.sessionState.newHadoopConf()) if (fs.exists(checkpointPath)) { throw new AnalysisException( s"This query does not support recovering from checkpoint location. " + s"Delete $checkpointPath to start over.")
}
} val analyzedPlan = df.queryExecution.analyzed
df.queryExecution.assertAnalyzed() if (sparkSession.sessionState.conf.isUnsupportedOperationCheckEnabled) { UnsupportedOperationChecker.checkForStreaming(analyzedPlan, outputMode)
} if (sparkSession.sessionState.conf.adaptiveExecutionEnabled) {
logWarning(s"${SQLConf.ADAPTIVE_EXECUTION_ENABLED.key} " + "is not supported in streaming DataFrames/Datasets and will be disabled.")
} new StreamingQueryWrapper(new StreamExecution(
sparkSession,
userSpecifiedName.orNull,
checkpointLocation,
analyzedPlan,
sink,
trigger,
triggerClock,
outputMode,
deleteCheckpointOnStop))
}我们的case太简单,没有checkpoint,没有trigger, 所以基本就是默认设置,上述逻辑中基本就不只是用到创建analyzedPlan,然后就直接实例化一个StreamingQueryWrapper, 完事,当然重要的StreamExecution。这边我们也注意到前期parse 完的un-resovled logical plan是由QueryExecution做的。
StreamExecution:这应该真真就是我们的流式执行引擎了。来看下他的主要成员:
sources: 流式数据源,前文已经hit
logicalPlan: DataFrame/Dataset 的一系列变换,前文已经hit
sink: 结果输出端,前文已经hit
再来看下,另外的重要成员变量是:
currentBatchId: 当前执行的 id,初始为-1,表示需要先初始化
offsetLog:WAL,记录当前每个batch的offset
batchCommitLog: 记录已经被commit掉的batch
availableOffsets:当前可以被执行的Offset,还未被commit到sink
committedOffsets: 当前已经被处理且commit到sink或者statestore的offset
watermarkMsMap: 记录当前操作的watermark,对于stateful的查询而言可以处理delayed数据的一种手段。
通过StreamExecution就将整个流程穿起来了,后面通过代码走读在分析其工作原理。让我们先回到三段文上来。
校验query
Make sure no other query with same name is active
Make sure no other query with same id is active
start query
/**
* Starts the execution. This returns only after the thread has started and [[QueryStartedEvent]]
* has been posted to all the listeners.
*/
def start(): Unit = {
logInfo(s"Starting $prettyIdString. Use $resolvedCheckpointRoot to store the query checkpoint.")
microBatchThread.setDaemon(true)
microBatchThread.start()
startLatch.await() // Wait until thread started and QueryStart event has been posted
}看到这一喜,应该找到组织了。看到microBatch一凉,看来还不是纯种的流式计算框架。
/**
* The thread that runs the micro-batches of this stream. Note that this thread must be
* [[org.apache.spark.util.UninterruptibleThread]] to workaround KAFKA-1894: interrupting a
* running `KafkaConsumer` may cause endless loop.
*/
val microBatchThread = new StreamExecutionThread(s"stream execution thread for $prettyIdString") { override def run(): Unit = { // To fix call site like "run at <unknown>:0", we bridge the call site from the caller
// thread to this micro batch thread
sparkSession.sparkContext.setCallSite(callSite)
runBatches()
}
}run方法里面调了runBatches方法,有点儿长,删掉点好了,并在代码里直接加注释分析
/**
* Repeatedly attempts to run batches as data arrives
*/
private def runBatches(): Unit = { try { // force initialization of the logical plan so that the sources can be created
// 强行调用下logical plan,以创建sources,这变量是lazy的。
logicalPlan // Isolated spark session to run the batches with.
// clone一个session来做真正执行
val sparkSessionToRunBatches = sparkSession.cloneSession() // 记录source offset 序列的元数据信息,
offsetSeqMetadata = OffsetSeqMetadata(
batchWatermarkMs = 0, batchTimestampMs = 0, sparkSessionToRunBatches.conf) if (state.compareAndSet(INITIALIZING, ACTIVE)) { // 一个Trigger机制,我们质变是一个`ProcessingTimeExecutor`,
// executor方法实际就是一个while循环,循环执行execute的函数参数。
triggerExecutor.execute(() => {
startTrigger() if (isActive) {
reportTimeTaken("triggerExecution") { // 尝试获取新数据
if (currentBatchId < 0) { // We'll do this initialization only once
// 第一次尝试
populateStartOffsets(sparkSessionToRunBatches)
sparkSession.sparkContext.setJobDescription(getBatchDescriptionString)
logDebug(s"Stream running from $committedOffsets to $availableOffsets")
} else { // 后面这么尝试,具体就是获取source的最新offset,写wal,添加
constructNextBatch()
} // runBatch, 对当前batch进行计算,后续拉出来在看看
if (dataAvailable) {
currentStatus = currentStatus.copy(isDataAvailable = true)
updateStatusMessage("Processing new data")
runBatch(sparkSessionToRunBatches)
}
} // Report trigger as finished and construct progress object.
finishTrigger(dataAvailable) // 做完运算马上写log
if (dataAvailable) { // Update committed offsets.
batchCommitLog.add(currentBatchId)
committedOffsets ++= availableOffsets
logDebug(s"batch ${currentBatchId} committed") // We'll increase currentBatchId after we complete processing current batch's data
currentBatchId += 1
sparkSession.sparkContext.setJobDescription(getBatchDescriptionString)
} else {
currentStatus = currentStatus.copy(isDataAvailable = false)
updateStatusMessage("Waiting for data to arrive") Thread.sleep(pollingDelayMs)
}
}
updateStatusMessage("Waiting for next trigger")
isActive
})
updateStatusMessage("Stopped")
}
}
}
}runBatch
/**
* Processes any data available between `availableOffsets` and `committedOffsets`.
* @param sparkSessionToRunBatch Isolated [[SparkSession]] to run this batch with.
*/
private def runBatch(sparkSessionToRunBatch: SparkSession): Unit = { // Request unprocessed data from all sources.
newData = reportTimeTaken("getBatch") {
availableOffsets.flatMap { case (source, available) if committedOffsets.get(source).map(_ != available).getOrElse(true) => val current = committedOffsets.get(source) val batch = source.getBatch(current, available)
assert(batch.isStreaming, s"DataFrame returned by getBatch from $source did not have isStreaming=true\n" + s"${batch.queryExecution.logical}")
logDebug(s"Retrieving data from $source: $current -> $available") Some(source -> batch) case _ => None
}
} // A list of attributes that will need to be updated.
val replacements = new ArrayBuffer[(Attribute, Attribute)] // Replace sources in the logical plan with data that has arrived since the last batch.
val withNewSources = logicalPlan transform { case StreamingExecutionRelation(source, output) =>
newData.get(source).map { data => val newPlan = data.logicalPlan
assert(output.size == newPlan.output.size, s"Invalid batch: ${Utils.truncatedString(output, ",")} != " + s"${Utils.truncatedString(newPlan.output, ",")}")
replacements ++= output.zip(newPlan.output)
newPlan
}.getOrElse { LocalRelation(output, isStreaming = true)
}
} // Rewire the plan to use the new attributes that were returned by the source.
val replacementMap = AttributeMap(replacements) val triggerLogicalPlan = withNewSources transformAllExpressions { case a: Attribute if replacementMap.contains(a) =>
replacementMap(a).withMetadata(a.metadata) case ct: CurrentTimestamp => CurrentBatchTimestamp(offsetSeqMetadata.batchTimestampMs,
ct.dataType) case cd: CurrentDate => CurrentBatchTimestamp(offsetSeqMetadata.batchTimestampMs,
cd.dataType, cd.timeZoneId)
}
reportTimeTaken("queryPlanning") {
lastExecution = new IncrementalExecution(
sparkSessionToRunBatch,
triggerLogicalPlan,
outputMode,
checkpointFile("state"),
runId,
currentBatchId,
offsetSeqMetadata)
lastExecution.executedPlan // Force the lazy generation of execution plan
} val nextBatch = new Dataset(sparkSessionToRunBatch, lastExecution, RowEncoder(lastExecution.analyzed.schema))
reportTimeTaken("addBatch") { SQLExecution.withNewExecutionId(sparkSessionToRunBatch, lastExecution) {
sink.addBatch(currentBatchId, nextBatch)
}
}
……
}runBatch这里有5个关键步骤:
1、从availableOffsets拿到最新 offset作为终点,从 committedOffsets拿到前置batch的offset作为起点,Source.getBatch(起点,终点) 获取本执行新收到的数据, 以Dataset/DataFrame 表示
2、以StreamExecution里预置的logicalPlan为蓝本,进行transform,得到绑定新的数据的logicalPlan (withNewSources)副本,具体做法就是模式匹配,用第一步的df替换StreamingExecutionRelation节点的source成员为最新。
3、接着通过该计划创建IncrementalExecution ,
4、调用lastExecution.executedPlan之后会触发Catalyst的一系列化学反应,将logicalplan转化为可执行的物理计划
5、将该executedPlan打包成一个Dataset交给 Sink,即调用 Sink.addBatch触发执行,我们的sink是console,看下ConsoleSink的实现,show方法触发整个dag的运转
override def addBatch(batchId: Long, data: DataFrame): Unit = synchronized { val batchIdStr = if (batchId <= lastBatchId) { s"Rerun batch: $batchId"
} else {
lastBatchId = batchId s"Batch: $batchId"
} // scalastyle:off println
println("-------------------------------------------")
println(batchIdStr)
println("-------------------------------------------") // scalastyle:off println
data.sparkSession.createDataFrame(
data.sparkSession.sparkContext.parallelize(data.collect()), data.schema)
.show(numRowsToShow, isTruncated)
}总结
本文以wordcount app 简单的走读了下Structured Streaming的源码及执行逻辑,记录作为一个医生转行程序员看代码的一个过程,见地比较浅显,不足之处欢迎指正。
Structured Streaming中还有很多令人振奋的特性值得分析挖掘,希望在后面可以尽快分享给大家。
注解1:对于输入path目录很多的情况下,spark也会起job来并行listfilestatus
作者:风景不美
链接:https://www.jianshu.com/p/f6acadaa35a2





热门评论
-

qq_慕盖茨90880572019-05-09 0
查看全部评论start query
def start(): Unit = {
logInfo(s"Starting $prettyIdString. Use $resolvedCheckpointRoot to store the query checkpoint.")
microBatchThread.setDaemon(true)
microBatchThread.start()
startLatch.await() // Wait until thread started and QueryStart event has been posted
}
这部分在最新的代码中是否已经修改了,这样子的话,microBatchExecution中的runBatch又是在哪调用起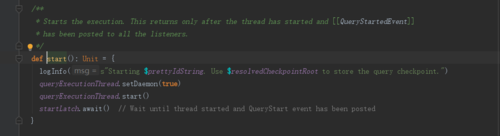 呢?
呢?