
RPC体系结构
spark1.6中的RPC体系结构大致如下:
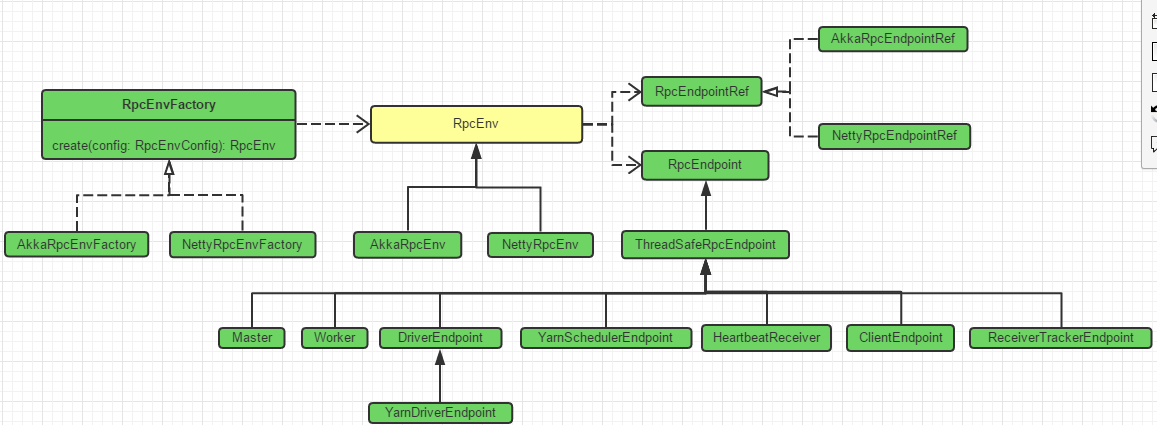
image
RpcEnv相当于容器,有host、port已及注册其中的RpcEndpoint,RpcEndpoint有对应的RpcEndpointRef。RpcEndpointRef对RpcEndpoint发送相应消息,RpcEndpoint对针对具体消息做出相应操作。
大致流程
客户端和服务端都需要创建RpcEnv对象
服务端通过RpcEnv.setupEndpoint()将服务注册到RpcEnv中
客户端通过主机、端口、名称找到对应的RpcEndpointRef,通过调用ask\send方法对其发送请求
RpcEndpoint通过receive\receiveReplay对调用请求做出响应
RpcEnv创建
Master、Worker、Driver中均需要创建RpcEnv
Master和Worker在启动时创建,Driver在SparkContext创建SparkEnv时创建RpcEnv
这三个角色,同时为服务端和客户端
//Master.scala\Worker.scala val rpcEnv = RpcEnv.create(SYSTEM_NAME, host, port, conf, securityMgr)
Driver中创建,代码如下:
//SparkEnv.scala
private def create(....):SparkEnv={
.....
val rpcEnv = RpcEnv.create(systemName, hostname, port, conf, securityManager,
clientMode = !isDriver)
}
....RpcEnv.create里面会通过RpcEnvFactory的create方法来创建具体的RpcEnv实现,下面是V1.6的代码,通过反射来支撑Akka和Netty这两套RPC实现,V2.0里面面已经没有AkkaRpcEnvFactory以及AkkaRpcEnv、AkkaEndpointRef等使用AAkka的rpc实现了,只有NettyRpcEnvFactory直接new了.
private def getRpcEnvFactory(conf: SparkConf): RpcEnvFactory = {
val rpcEnvNames = Map( "akka" -> "org.apache.spark.rpc.akka.AkkaRpcEnvFactory", "netty" -> "org.apache.spark.rpc.netty.NettyRpcEnvFactory")
val rpcEnvName = conf.get("spark.rpc", "netty")
val rpcEnvFactoryClassName = rpcEnvNames.getOrElse(rpcEnvName.toLowerCase, rpcEnvName)
Utils.classForName(rpcEnvFactoryClassName).newInstance().asInstanceOf[RpcEnvFactory]
}最终由RpcEnvFactory(具体实现为:NettyRpcEnvFactory)的create方法创建具体的RpcEnv实现,并在指定端口启动服务。
以下为NettyRpcEnvFactory
def create(config: RpcEnvConfig): RpcEnv = {
val sparkConf = config.conf // Use JavaSerializerInstance in multiple threads is safe. However, if we plan to support
// KryoSerializer in future, we have to use ThreadLocal to store SerializerInstance
val javaSerializerInstance = new JavaSerializer(sparkConf).newInstance().asInstanceOf[JavaSerializerInstance]
val nettyEnv = new NettyRpcEnv(sparkConf, javaSerializerInstance, config.host, config.securityManager) if (!config.clientMode) {
val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
nettyEnv.startServer(actualPort)
(nettyEnv, nettyEnv.address.port)
} try {
Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch { case NonFatal(e) =>
nettyEnv.shutdown() throw e
}
}
nettyEnv
}
}RpcEndpoint注册
RpcEvn创建成功,服务端已经在指定的端口启动,但还需要注册具体的服务(RpcEndpoint)于其中才能正常响应调用方的调用请求
调用RpcEvn.setupEndpoint来注册RpcEndpoint
/** * Register a [[RpcEndpoint]] with a name and return its [[RpcEndpointRef]]. [[RpcEnv]] does not * guarantee thread-safety. */ def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef
以Master为例,代码如下:
val masterEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, new Master(rpcEnv, rpcEnv.address, webUiPort, securityMgr, conf))
每个RpcEnv中的RpcEndpoint,在开始处理处理消息之前会调用onStart方法,所以一些初始化的方法都大onStart中进行,比如Master和Worker的启动就在时执行,
receive中定义对各种消息处理的操作,消息类型全是case class,比如在Master中就有对Heartbeat、DriverStateChanged、ExecutorStateChanged等等消息的处理、可以看Master.scala和Worker.scala
RpcEndpoint的定义
//RpcEndpoint.scalaprivate[spark] trait RpcEndpoint { /**
* Invoked before [[RpcEndpoint]] starts to handle any message.
*/
def onStart(): Unit = {
} /**
* Process messages from [[RpcEndpointRef.send]] or [[RpcCallContext.reply)]]. If receiving a
* unmatched message, [[SparkException]] will be thrown and sent to `onError`.
*/
def receive: PartialFunction[Any, Unit] = { //通常都在这里面定义了对各种各样消息的对应操作,消息都是定义在case class中
} /**
* Process messages from [[RpcEndpointRef.ask]]. If receiving a unmatched message,
* [[SparkException]] will be thrown and sent to `onError`.
*/
def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = { //通常都在这里面定义了对各种各样消息的对应操作以及回复,消息都是定义在case class中
} /**
* Retrieve the [[RpcEndpointRef]] represented by `systemName`, `address` and `endpointName`.
* This is a blocking action.
*/
def setupEndpointRef(
systemName: String, address: RpcAddress, endpointName: String): RpcEndpointRef = {
setupEndpointRefByURI(uriOf(systemName, address, endpointName)) //服务调用着调用这个方法获取RpcEndpointRef,给RpcEndpoint发送调用请求
}
......
}
作者:migle
链接:https://www.jianshu.com/p/c2b854698608




