
我就不沾啥大数据和人工智能的边了,只是默默的弄我的文本数据分析。我的初衷是对我自己的印象笔记的进行关键词提取分析,然后看看今年我自己的日记中出现最频繁词语。至于为啥选择python,只是因为python的数据分析的插件更多,更丰富,有更好的选择性。在这里就不进行这种万年话题的讨论了(“那门编程语言好”)。
依赖环境: python3; 工具: pip3
当然也是支持python2.7的,可以直接使用python编译,使用pip安装的。
文本数据源获取
我之前一直以为印象笔记导出的文本是txt或者word文档,当我实际导出时发现导出的是html格式文件。。。。,有点出乎意料,那么只能通过读取html文件,获取日记内容(我将我今年的印象合并在一个文件里面)。我选择使用BeautifulSoup获取html文件数据。
BeautifulSoup intsall:
$ pip3 install beautifulsoup4
from bs4 import BeautifulSoup
# 解析html文件, 若不是html文件可以不使用BeautifulSoup
soup = BeautifulSoup(
open("./file/合并.html", encoding='utf-8').read(), "html.parser")
html_text = soup.get_text() # 获取文本
变量html_text即是我的文本数据了,获取到文本数据之后,下面进行的就是关键字提取了。
参考: BeautifulSoup 文档
关键字提取
对文本数据提取和拆分,我选择使用jiaba, 它是python开源库中比较好的中文提取组件,用过之后还不错,对于个人分析还是够用的。
BeautifulSoup intsall:
$ pip3 install jieba
而且jieba还可以自定义词库哦,看下图:
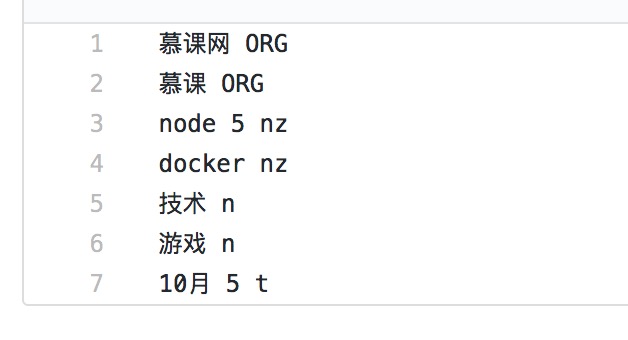
自定义词库时,一词站一行,每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒
import jieba
import jieba.analyse
# 自定义词库
jieba.load_userdict('./file/dict.txt') # 自定义词库
# 分析关键字 基于 TF-IDF 算法
extract_tags = jieba.analyse.extract_tags(html_text, topK=20, withWeight=True)
# 输出结果
for item in extract_tags:
print(item)
好的,就是这么简单,嘻嘻嘻,下面是我的2018年日记关键词:
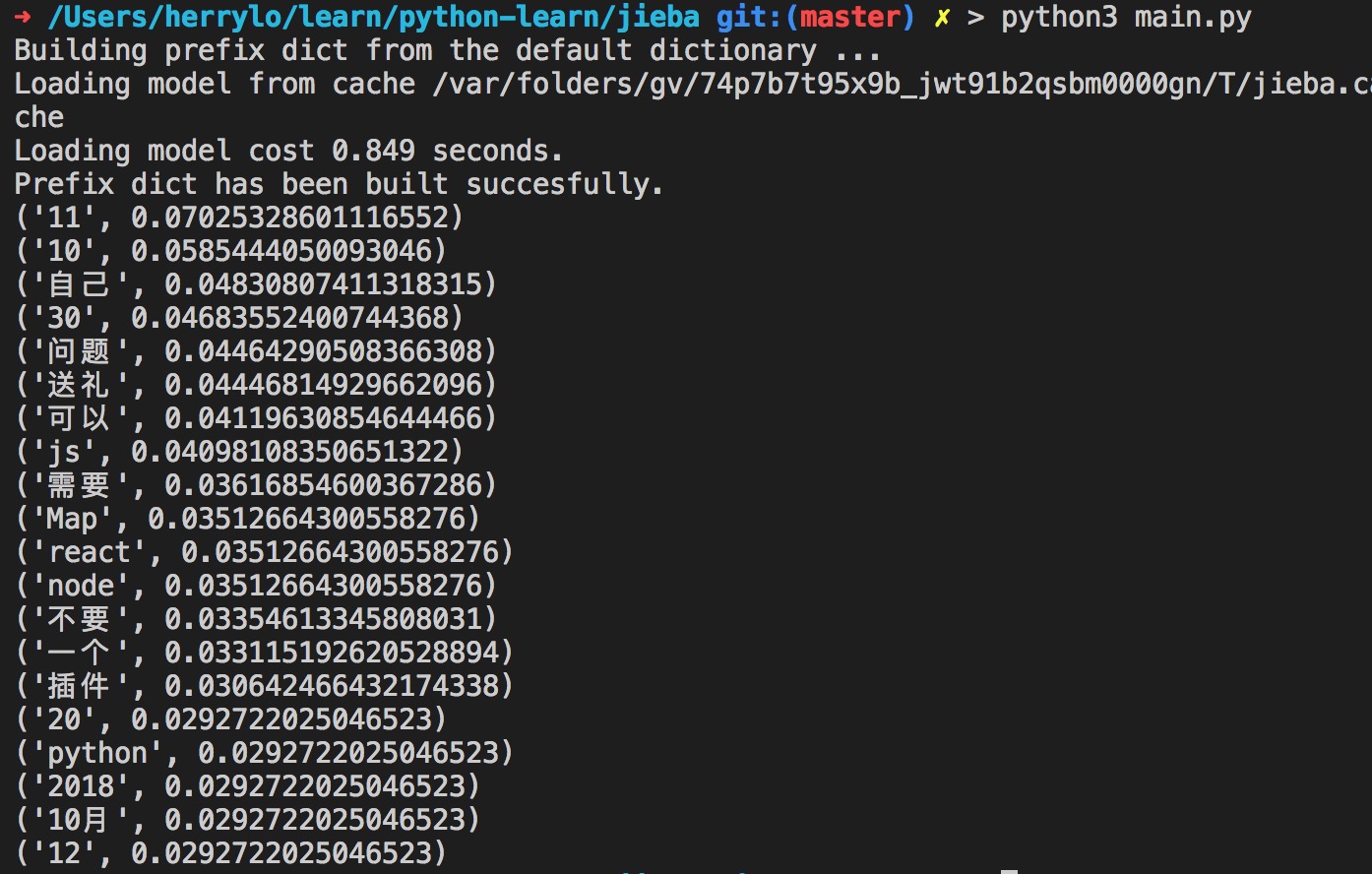
不多说了,有疑问可以评论或者私信哦!!






