
索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就获取到的,很多的技术人员因为不恰当的创建索引,最后使得其效果适得其反,可以说“成也索引,败也索引”。
本系列文章来自Stairway to SQL Server Indexes,翻译和整理后发布在agilesharp和博客园,希望对广大的技术朋友在如何使用索引上有所帮助。
唯一索引和约束
唯一索引和其它索引本质上并没有什么不同,唯一不同的是唯一索引不允许索引键中存在相同的值。因为索引中每一个条目都与表中的行对应。唯一索引不允许重复值被插入索引也就保证了对应的行不允许被插入索引所在的表,这也是为什么唯一索引能够实现主键和候选键。
为表声明主键或唯一约束时,SQL Server会自动创建与之对应的唯一索引。你可以在没有唯一约束的情况下创建唯一索引,但反之则不行。定义一个约束时,SQL Server会自动创建一个与之同名的索引,并且你不能在删除约束之前删除索引。但可以删除约束,删除约束也会导致与之关联的索引被删除。
每个表中可以包含多个唯一索引。比如说AdventureWorks的Product表,含有四个唯一索引,分别是ProductID,ProductNumber,rowguid和ProductNameColumn,设置Product表的人将ProductID作为主键,其它三个作为候选键。
你可以通过Create INDEX语句创建唯一索引,比如:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_Name] ON Production.Product ( [Name]);
也可以通过直接定义约束创建唯一索引:
ALTER TABLE Production.Product ADD CONSTRAINT PK_Product_ProductID PRIMARY KEY CLUSTERED ( ProductID );
上面第一种方法,你Prodcut表中不能含有相同的ProductName,第二种情况表中不允许存在相同的ProductID。
因为定义一个主键或是定义约束会导致索引被创建,所以你必须在约束定义时就给出必要的索引信息,因此上面ALTER TABLE语句中包含了”CLUSTERED”关键字。
如果唯一索引或约束所约束的列在当前的表中已经含有了重复值,那么创建索引会失败。
而当唯一索引创建成功后,所有违反这个约束的DML语句都会失败,比如,我们打算加入一条当前表中存在的的ProductName,语句如下:
INSERT Production.Product ( Name , ProductNumber , Color , SafetyStockLevel , ReorderPoint , StandardCost , ListPrice , Size , SizeUnitMeasureCode , WeightUnitMeasureCode , [Weight] , DaysToManufacture , ProductLine , Class , Style , ProductSubcategoryID , ProductModelID , SellStartDate , SellEndDate , DiscontinuedDate ) VALUES ( 'Full-Finger Gloves, M' , 'A unique product number' , 'Black' , 4 , 3 , 20.00 , 40.00 , 'M' , NULL , NULL , NULL , 0 , 'M' , NULL , 'U' , 20 , 3 , GETDATE() , GETDATE() , NULL ) ;
上面代码执行后我们可以看到如下报错信息:
消息 2601,级别 14,状态 1,第 1 行 不能在具有唯一索引 'AK_Product_Name' 的对象 'Production.Product' 中插入重复键的行。 语句已终止。
上面的消息告诉我们AK_Product_Name索引不允许我们插入的数据含有和当前表中一样的ProductName。
主键,唯一约束和没有约束
主键约束和唯一约束有如下细小的差别。
主键约束不允许出现NULL值。任何索引的索引键都不允许包含null值。但唯一约束允许包含NULL值,但唯一约束把两个NULL值当作重复值,所以施加了唯一约束的每一列只允许包含一个NULL值。
创建主键时会自动创建聚集索引,除非当前表中已经含有了聚集索引或是创建主键时指定了NONCLUSTERED关键字。
创建唯一约束时会自动创建非聚集索引,除非你指定了CLUSTERED关键字并且当前表中还没有聚集索引。
每个表中只能有一个主键,但可以由多个唯一约束。
对于唯一约束和唯一索引的选择,请参照MSDN上的指导,如下:
唯一约束和唯一索引并没有显著的区别。创建独立的唯一索引和使用唯一约束对于数据的验证方式并无区别。查询优化器也不会区分唯一索引是由约束创建还是手工创建。然而以数据完整性为目标的话,最好创建约束,这使得对应的索引的目标一目了然。
混合唯一索引和过滤索引
上面我们提到过唯一索引只允许一个NULL值,但这和常见的业务需求有冲突。很多时候我们对于已经存在的值不允许重复,但是允许存在多个没有值的列。
比如说吧,你是一个供货商,你所有的产品都来自于第三方厂商。你将你这里所有的商品信息都存在一个叫做ProductDemo的表中。你有自己的ProductID,还追踪产品的UPC(Universal Product Code)值。但并不是所有的厂商产品都存在UPC,你表中的部分数据如下所示。
| ProductID | UPCode | Other Columns |
| 主键 | 唯一索引 | |
| 14AJ-W | 036000291452 | |
| 23CZ-M | ||
| 23CZ-L | ||
| 18MM-J | 044000865867 |
表1.ProductDemo表的部分内容
在上表中第二列,你既要保证UPCode的唯一性,又要保证允许NULL值。实现这种需求最好的办法就是混合唯一索引和过滤索引(过滤索引实在SQL Server 2008中引入的)。
作为演示,我们创建了表1所示的表.
CREATE TABLE ProductDemo
(
ProductID NCHAR(6) NOT NULL
PRIMARY KEY ,
UPCode NCHAR(12) NULL
) ;
接下来我们插入如上所示的数据.
INSERT ProductDemo ( ProductID, UPCode ) VALUES ( '14AJ-W', '036000291452' ) , ( '23CZ-M', NULL ) , ( '23CZ-L', NULL ) , ( '18MM-J', '044000865867' ) ;
当我们插入重复值时
INSERT ProductDemo (ProductID , UPCode) VALUES ('14AJ-K', '036000291452');收到如下错误
消息 2601,级别 14,状态 1,第 1 行 不能在具有唯一索引 'xx' 的对象 'dbo.ProductDemo' 中插入重复键的行。 语句已终止。
(译者注,这里原文作者应该是疏忽了,略坑爹,因为他没有创建过滤唯一索引,所以按照原文不会报错,我在这里加上了,代码:CREATE UNIQUE NONCLUSTERED INDEX xx on ProductDemo(UPCode) where UPCode!=null)
选择合适的IGNORE_DUP_KEY选项
当你创建唯一索引时,你可以指定IGNORE_DUP_KEY选项,因此本文最开始创建唯一索引的选项可以是:
CREATE UNIQUE NONCLUSTERED INDEX AK_Product_Name ON Production.Product ( [Name] ) WITH ( IGNORE_DUP_KEY = OFF );
IGNORE_DUP_KEY这个名字容易让人误会。唯一索引存在时重复的值永远不会被忽略。更准确的说,唯一索引中永远不允许存在重复键。这个选项的作用仅仅是在多列插入时有用。
比如,你有两个表,表A和表B,有着完全相同的结构。你可能提交如下语句给SQL Server。
INSERT INTO TableA SELECT * FROM TableB;
SQL Server会尝试将所有表B中的数据插入表A。但如果因为唯一索引拒绝表B中含有和表A相同的数据插入A怎么办?你是希望仅仅重复数据插入不成功,还是整个INSERT语句不成功?
这个取决于你设定的IGNORE_DUP_KEY参数,当你创建唯一索引时,通过设置设个参数可以设定当插入不成功时怎么办,设置IGNORE_DUP_KEY的两种参数解释如下:
IGNORE_DUP_KEY=OFF
整个INSERT语句都不会成功并弹出错误提示,这也是默认设置。
IGNORE_DUP_KEY=OFF
只有那些具有重复键的行不成功,其它所有的行会成功。并弹出警告信息。
IGNORE_DUP_KEY 选项仅仅影响插入语句。而不会被UPDATE,CREATE INDEX,ALTER INDEX所影响。这个选项也可以在设置主键和唯一约束时进行设置。
为什么唯一索引可以提供额外的性能提升
唯一索引可以提供出乎你意料之外的性能提升。这是因为唯一索引给SQL Server提供了确保某一列绝对没有重复值的信息。adventureWork的Product表中的ProductID和ProductName这两个唯一索引,提供了很好的例子。
加入,你们公司数据仓库的某个哥们希望你给他提供Product表的一些信息,要求如下:
产品名称
产品销售的数量
总销售额
因此,你写了如下的查询语句:
SELECT [Name] , COUNT(*) AS 'RowCount' , SUM(LineTotal) AS 'TotalValue' FROM Production.Product P JOIN Sales.SalesOrderDetail D ON D.ProductID = P.ProductID GROUP BY P.Name
(译者注,这里原作者给的代码有问题,ProductID替换为P.Name)
数据仓库的哥们对你的查询语句很满意,每一行都包含了产品名称,销售数量和总的销售额,查询出来的部分结果如下:

但是,你对于这个查询的成本有所担心。SalesOrderDetail是上面查询中两个表中比较大的表,并且还按照ProductName进行分组,这个ProductName是来自Product表而不是SalesOrderDetail表。
通过SQL Server Management Studio,你注意到SalesOrderDetail表有主键,并且主键也是聚集索引键,也就是SalesOrderID和SalesOrderDetailID,这个主键并不会给按照ProductName分组带来性能提升。
如果你运行了第五篇包含列的代码,你创建了如下非聚集索引。
CREATE NONCLUSTERED INDEX FK_ProductID_ModifiedDate ON Sales.SalesOrderDetail ( ProductID, ModifiedDate ) INCLUDE ( OrderQty, UnitPrice, LineTotal ) ;
你觉得这个索引可以对你的查询有帮助因为这个索引包含了除了ProductName列的所有查询所需的信息。并且这个索引是按照ProductID进行排序的,但你仍然担心分组的ProductID来自其中一个表而Select的信息来自另一个表。
你通过SQL Server Management Studio,通过查看执行计划,看到前面数据仓库那哥们要的查询的执行计划如图1所示。
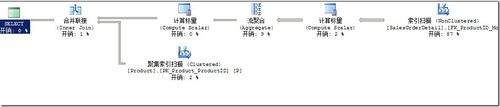
图1.按Product.Name进行分组时的执行计划
首先你可以惊讶于Product表的Product name索引,Product.AK_Product_Name没有被使用.然后你意识到在Product.Name列上和Product.ProductID上有唯一索引,这使得SQL Server知道这两列是唯一的。因此,Group By Name等效于Group By ProductID。这使得一个产品一个组。
因此,查询优化器意识到你的查询等同于如下查询,这两个ProductID索引因此支持对所求查询的Join和group操作。
SELECT [Name] , COUNT(*) AS 'RowCount' , SUM(LineTotal) AS 'TotalValue' FROM Production.Product P JOIN Sales.SalesOrderDetail D ON D.ProductID = P.ProductID GROUP BY ProductID
SQL Server会同时扫描SalesOrderDetail上的覆盖索引和聚集索引,这两个索引都是以ProductID进行排序的。因此使用合并连接,而免去了排序或散列操作,总之SQL Server生成了最有效的查询计划。
如果你Drop了Product.AK_Product_Name索引,比如:
IF EXISTS ( SELECT * FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID(N'Production.Product') AND name = N'AK_Product_Name') DROP INDEX AK_Product_Name ON Production.Product;
那么生成的新的执行计划就没有那么有效了,需要额外的排序和合并连接操作。

图2.当Drop掉索引后,按照Product Name进行分组的查询的执行计划
你可以看到,虽然唯一索引的主要功能是保证数据的完整性,还可以帮助查询优化器生成更好的查询计划,即使这个索引本身不被用来访问数据。
总结
唯一索引为主键和候选键提供了约束。唯一索引可以在没有唯一约束时存在,反之则不行。
唯一索引同时也可以是过滤索引,这使得唯一索引可以允许一列中有多个NULL值。
IGNORE_DUP_KEY 关键字可以影响批量插入语句。
唯一索引还可以提供更好的性能,既然唯一索引本身并没有用于数据访问。



