
在前面的手记《简述Hadoop各种部署方式及学习路线》,分享了关于Hadoop的各种部署方式,那么今天我们就来搭建一个完全分布式的Hadoop环境
实验环境一共搭建3个节点:
一、主机名和IP如下:
node1.hadoop.cn 192.168.184.6 CentOS 7
node2.hadoop.cn 192.168.184.7 CentOS 7
node3.hadoop.cn 192.168.184.8 CentOS 7
二、节点所承担Hadoop中的角色:
node1.hadoop.cn namenode datanode nodemanager
node2.hadoop.cn datanode nodemanager
node3.hadoop.cn datanode nodemanager resourcemanager
集群部署前提:
在上述3个节点上做以下设置:
(1)、配置本地DNS解析
所有3个节点的/etc/hosts追加以下内容:
192.168.184.6 node1.hadoop.cn
192.168.184.7 node2.hadoop.cn
192.168.184.8 node3.hadoop.cn
(2)、关闭selinux和iptables
所有3个节点上执行:setenforce 0
查看关闭selinux是否生效:getenforce
永久关闭selinux:sed -i "s/SELINUX=Enforcing/SELINUX=permissive/g" /etc/sysconfig/selinux
关闭防火墙:systemctl stop firewalld.service
关闭开机自启动:systemctl disable firewalld.service
正式部署之前,有必要先理清思路。Hadoop的核心就是HDFS和MapReduce,其中HDFS是提供了底层的分布式存储功能,是一个独立的模块,而MapReduce则是建立在HDFS基础之上的,包括Hadoop 2.X版本中引入的YARN计算框架,其也是需要运行在HDFS基础之上。
因此我们首先来部署HDFS,HDFS由两个进程组成,一个是DataNode,另外一个是NameNode,其中NameNode是元数据的管理节点,存储了元数据的inode信息和目录树结构,但真正的数据是存储在DataNode之上,上面的规划中node1、node2和node3一共3个节点,都提供了DataNode功能,也就是都提供数据存储,但node1还额外提供了NameNode进程;
因此我们首先部署HDFS,配置步骤如下:
所需JDK安装包:jdk-8u181-linux-x64.tar.gz
所需Hadoop安装包:hadoop-2.7.6.tar.gz
一、配置JAVA环境
Hadoop中的HDFS或YARN进程,其实质都是启动一个JVM进程,是建立在JAVA环境的基础之上的,因此我们必须首先配置好环境变量
所有节点都做如下设置:
tar xf jdk-8u181-linux-x64.tar.gz -C /usr/local/
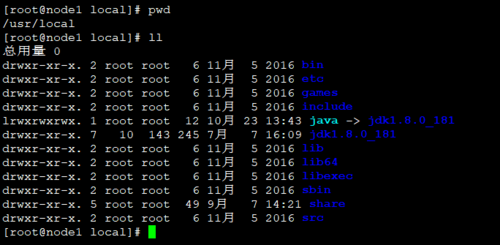
ln -sv /usr/local/jdk1.8.0_181 /usr/local/java
设置后如下图所示:
/etc/profile追加一下内容:
export JAVA_HOME=/usr/local/java
export PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
追加后使用source /etc/profile命令重读环境变量文件
至此JAVA环境变量设定完毕,测试是否设置正确,执行一下命令:
java -version
若输出一下信息,表示设置正确

二、配置HDFS
解压压缩包到指定目录:
tar xf hadoop-2.7.6.tar.gz -C /usr/local/
建立链接:
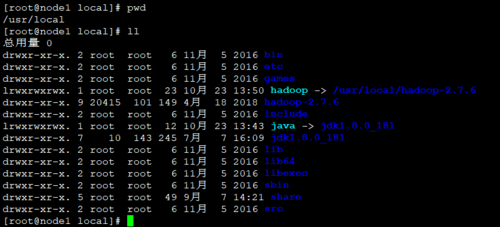
ln -sv /usr/local/hadoop-2.7.6 /usr/local/hadoop
设定后如下图所示:
更改属主属组,因为HDFS的NameNode和DataNode进程,我们都会以普通用户hdfs来运行,因此必须将hadoop的目录更改为hdfs所有
useradd hdfs
passwd hdfs (输出你想设置的密码)
root用户下将/usr/local/hadoop下所有文件更改为hdfs所有
chown -R hdfs.hdfs /usr/local/hadoop
chown -R hdfs.hdfs /usr/local/hadoop/*
设定后如下图所示:

继续配置HDFS环境变量,编辑/etc/profile文件,修改后的内容如下:

验证是否设置成功:
执行命令:hadoop version
输出一下内容表示配置HDFS环境变量成功:

确认上述配置无误后,使用su - hdfs切换到hdfs用户下,开始修改配置文件
su - hdfs
HDFS的配置文件目录为:/usr/local/hadoop/etc/hadoop
编辑hdfs-site.xml文件,内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/data02/name/</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data02/data/</value>
</property>
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50010</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/usr/local/hadoop/etc/hadoop/white_hosts</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/black_hosts</value>
</property>
</configuration>
主要参数配置说明:
dfs.replication 设定副本集
dfs.name.dir 设定NameNode的元数据信息存储目录,可以设置多个
dfs.data.dir 设定DataNode的数据存在哪里,可以写多个磁盘,用逗号分隔
dfs.hosts 文件中的列表为HDFS的DataNode节点
dfs.hosts.exclude 将文件列表中的主机剔除出HDFS
接着编辑core-site.xml文件,添加内容如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1.hadoop.cn:8020</value>
</property>
参数配置说明:
fs.defaultFS 指名NameNode服务RPC连接端口
编辑white.hosts文件,内容如下:
node1.hadoop.cn
node2.hadoop.cn
node3.hadoop.cn
说明:white.hosts文件中一行一个主机名,表示可以纳入集群的DataNode节点,根据我们的规划node1.hadoop.cn、node2.hadoop.cn、node3.hadoop.cn都要作为DataNode节点,所以都需要写进去
black.hosts文件为空表示不需将任何主机从HDFS从剔除,该文件通常用于维护,比如我们的HDFS集群中,有一个DataNode节点有故障,需要下线维护,则可以在NameNode节点的主机上,修改这个配置文件,将需要下线的主机名写进black.hosts文件,就可以将该节点剔除出HDFS集群
编辑slaves文件,内容如下:
node1.hadoop.cn
node2.hadoop.cn
node3.hadoop.cn
误区:slaves的作用在于我们使用start-dfs.sh启动进程时,帮助节点识别那些节点被纳入到了HDFS集群的,如果这个文件为空,则执行start-dfs.sh只会启动本机的进程(具体启动那些进程依赖于配置文件),但如果该文件不为空,则执行start-dfs.sh时,除启动本机进程外,还会通过ssh的方式登录到slaves文件中所定义的每一台主机,启动相关进程
经过上述的配置后,我们一共配置了3个文件,分别为:
hdfs-site.xml
core-site.xml
slaves
white.hosts
将这4个文件全部拷贝到其他节点上,保证3个节点一致。
然后执行start-dfs.sh,观察进程是否正常启动,可以通过jps命令查看
说明:执行上述命令时最好配置到其他主机的免秘钥登录,此处不再提供配置方法






