
Apache官方定义:Lucene是一个高效的,基于Java的全文检索库;开源免费
先来谈什么叫全文检索?
全文检索主要针对非结构化数据,主要有两种方法:
(1)、顺序扫描法
比如我们想要在成千上万的文档中,查找包含某一字符串的所有文档,顺序扫描法就必须逐个的扫描每个文档,并且每个文档都要从头看到尾,如果找到,就继续找下一个,直至遍历所有的文档;这种方法通常应用于数据量较小的场景,比如经常使用的grep命令就是这种查找方式
(2)、全文检索
试想一下结构化数据的查询方式,例如数据库的查找方式,我们知道在数据库中构建索引可以极大程度的提高查询速度,这是因为结构化数据有一定程度固定的结构使得我们可以采取某些搜索算法加速查询速度,那既然如此,为什么我们不可以尝试在非结构化数据中,将一部分结构化信息抽取出来,重新组织,然后针对这部分有结构的数据进行索引建立,从而达到加速查询的目的;
上述想法很天然,但却构成了全文检索的基本思路
从非结构化数据中抽取部分结构化数据,并建立索引,再对索引进行搜索的过程,我们成为全文索引
从上面我们可以看出,全文检索分为两步:
第一步:索引创建
第二步:搜索索引
从上述思路中,可以印出来三个问题:
1、索引里究竟存了些什么?
2、如何创建索引
3、如何对索引进行搜索?
针对上述问题,我们逐个探讨:
问题1:索引里究竟存了些什么?
想要知道索引里究竟存了些什么?我们必须先来了解一下正向索引和反向索引
正向索引:从文档中查找字符串 关系型数据库使用的是正向索引
反向索引:从字符串查找文档 搜索引擎lucene使用的是反向索引
反向索引的解释如下:

如上图所示,假如我有100个文档,对他们从1-100进行编号;
左边保存的是一系列的字符串,也可以理解为词,我们称这些字符串集合为词典;
右边保存的是包含左边字符串的文档链表,此文档链表成为倒排表
在上面中,我们对词典中包含的字符串创建索引,而这些字符串也正是我们搜索的信息,因此可以大大加快查询速度
比如说我们要查找同时包含"lucene"和"hadoop"的文档,我们只需以下几步:
第一步:取出包含lucene的文档链表
第二步:取出包含hadoop的文档链表
第三步:合并链表,取出交集

疑问:全文检索的确加快了搜索的速度,但是多了索引的过程,两者加起来不一定有顺序扫描快。这种说法的确有一定道理,在数据量小的情况下,顺序扫描未必比全文检索慢,但全文检索设计的初衷就是用于大数据量的业务环境中。
解答:全文检索和顺序扫描的区别在于:顺序扫描每次都必须从头至尾扫描全部数据,但全文检索的索引创建过程只需一次,以后查询无需再次创建,但却可以一直为搜索所用。
总结:全文检索相对于顺序扫描的优势在于一次索引创建,多次使用
问题2:如何创建索引?
索引的创建一般分为以下几步:
第一步:将文档交给切词组件(Tokenizer)进行切词处理
第二步:将得到的词元(Token)交给语言处理组件
第三步:将得到的词(Term)交给索引组件
第四步:由索引组件针对词建立索引
针对上述步骤,我们给出2个示例文档,加以详细说明
Document 1:Students should be allowed to go out with their friends, but not allowed to drink beer.
Document 2:My friend Jerry went to school to see his students but found them drunk which is not allowed.
第一步:切词组件处理
上述2个文档会被交给切词组件,切词组件主要针对文档进行切割,将文档中的单词一个一个切割出来,同时消除一些无意义的词,比如标点符号、英文中的"the"和"is"、中文中的"的"等。因为标点符号和一些形容词,在实际的搜索中是很少会被搜索的,所以在该步骤会剃掉这些词语,减少索引的大小
经过切割以后,可能会被切分成以下词元:
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”
第二步:语言处理组件处理
该步骤主要针对第一步生成的词元进行自然语言同化处理,比如针对cars词元,同时生成新的词car;Student词元中的大写字母小写化,这样能够实现一个student搜索,可以同时搜索处理像Student、STUDENT、stuDENT等多种情况,经过该步骤处理后,可能会被切分成以下词:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”
正因为有了自然语言处理组件,才能使得搜索drove,drive也能被搜出来
第三步:将得到的词交给索引组件建立索引
索引组件主要做以下几件事情:
(1)、利用得到的词创建一个词典
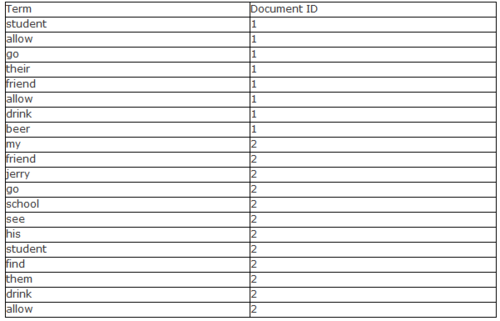
(2)、对字典按字母顺序进行排序
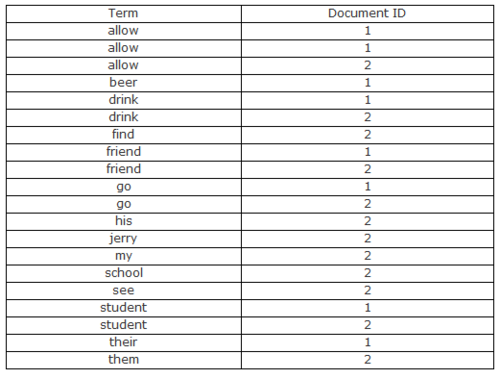
(3) 、合并相同的词并建立倒排链表
在上述表中,有几个定义:
Document Frequency:表示该词出现在所有文档的总数
Frequency:表示在某一个文档中该词出现的次数
第四步:建立索引
针对最后生成的词典,进行索引的建立,至此我们发现根据搜索词,我们可以立即找到对应的文档;而且诸如drink、drunk等都可以找到同一个文档
问题3:如何对索引进行搜索?
搜索可以分为以下几步:
第一步:用户输入查询语句
第二步:对查询语句进行词法分析、语法分析、语言处理
第三步:搜索索引,得到符合语法树的文档
第四步:根据得到的文档和查询语句相关性,对结果进行排序予以展示
第一步:用户输入语句
查询语句的语法根据全文检索系统的实现而不同。
比如用户输入:lucene AND learned NOT hadoop ---------> 用户想要查找包含lucene和learned,但是不包含hadoop的文档
第二步:对查询语句进行词法分析、语法分析、语言处理
(1)、词法分析主要用来识别单词和关键字
比如针对上述用户的输入,经过词法分析,得到单词为lucene、learned、hadoop,关键词为AND、NOT
(2)、语言分析主要根据查询语句来生成一颗语法树
受限进行语法判断,如果不满足语法要求,则直接报错;若满足语法要求,则可以生成下面的语法树:
(3)、语言处理和索引建立过程中得语言处理几乎一样
例如将learned变成learn,经过处理后得到以下结果:
第三步:搜索索引,得到符合语法树得文档
首先,在反向索引链表里,找到包含lucene、learn和hadoop得文档
其次,对包含lucene和learn得文档进行求合集操作,得到同时包含两者得文档链条
然后,将得到合集后得链表与hadoop得文档链表进行差集操作,去除包含hadoop得文档
最后,此文档链表就是我们要找得文档
第四步:根据得到的文档和查询语句的相关性,对结果进行排序
此过程也是极其复杂的,比如谷歌搜索,查询出来的结果有几十万上百万,如何排序显示,这个过程涉及到一些自然语言的理解,过程非常复杂,在此不再赘述
总结:Lucene是一个开源的分部署搜索引擎的实现,ElasticSearch底层就是基于Lucene实现的,之所以能够实现分布式搜索,原因就在于每一个文档在出库入库之前,就已经被进行切词分析处理,针对每个词建立索引,是一种空间换时间的做法
················································································································
欢迎关注课程:
企业级开源四层负载均衡解决方案--LVS














热门评论
-

qq_坚持v_02019-12-06 0
查看全部评论老师的课程 我还真买了