
1.背景
目前对于一些非核心操作,如增减库存后保存操作日志 发送异步消息时(具体业务流程),一旦出现MQ服务异常时,会导致接口响应超时,因此可以考虑对非核心操作引入服务降级、服务隔离。
2.Hystrix说明
官方文档 [https://github.com/Netflix/Hystrix/wiki]
hystrix是netflix开源的一个容灾框架,解决当外部依赖故障时拖垮业务系统、甚至引起雪崩的问题。
2.1为什么需要Hystrix?
在大中型分布式系统中,通常系统很多依赖(HTTP,hession,Netty,Dubbo等),在高并发访问下,这些依赖的稳定性与否对系统的影响非常大,但是依赖有很多不可控问题:如网络连接缓慢,资源繁忙,暂时不可用,服务脱机等。
当依赖阻塞时,大多数服务器的线程池就出现阻塞(BLOCK),影响整个线上服务的稳定性,在复杂的分布式架构的应用程序有很多的依赖,都会不可避免地在某些时候失败。高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险。例如:一个依赖30个SOA服务的系统,每个服务99.99%可用。 99.99%的30次方 ≈ 99.7% 0.3% 意味着一亿次请求 会有 3,000,00次失败 换算成时间大约每月有2个小时服务不稳定. 随着服务依赖数量的变多,服务不稳定的概率会成指数性提高.
解决问题方案:对依赖做隔离。
2.2Hystrix设计理念
想要知道如何使用,必须先明白其核心设计理念,Hystrix基于命令模式
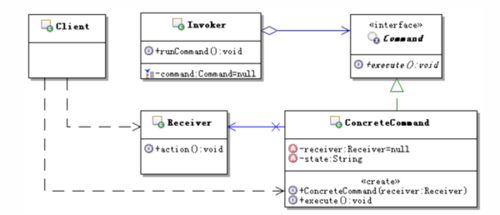
Command是在Receiver和Invoker之间添加的中间层,Command实现了对Receiver的封装
那么Hystrix的应用场景如何与上图对应呢?
API既可以是Invoker又可以是reciever,通过继承Hystrix核心类HystrixCommand来封装这些API(例如,远程接口调用,数据库查询之类可能会产生延时的操作)。就可以为API提供弹性保护了。
2.3 Hystrix如何解决依赖隔离
1: Hystrix使用命令模式HystrixCommand(Command)包装依赖调用逻辑,每个命令在单独线程中/信号授权下执行。
2: 可配置依赖调用超时时间,超时时间一般设为比99.5%平均时间略高即可.当调用超时时,直接返回或执行fallback逻辑。
3: 为每个依赖提供一个小的线程池(或信号),如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。
4: 依赖调用结果分:成功,失败(抛出异常),超时,线程拒绝,短路。 请求失败(异常,拒绝,超时,短路)时执行fallback(降级)逻辑。
5: 提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认错误率阈值为50%,超过将自动运行。
6: 提供近实时依赖的统计和监控
2.4Hystrix流程结构解析

1. 构建一个HystrixCommand或者HystrixObservableCommand
一个HystrixCommand或一个HystrixObservableCommand对象代表了对某个依赖服务发起的一次请求或者调用
同时在构造函数中传入所有需要的参数
HystrixCommand主要用于仅仅会返回一个结果的调用


HystrixObservableCommand主要用于可能会返回多条结果的调用


HystrixCommand command = new HystrixCommand(arg1, arg2); HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
2. 调用command的执行方法
要执行Command,需要在4个方法中选择其中的一个:execute(),queue(),observe(),toObservable()。其中execute()和queue()仅仅对HystrixCommand适用
execute():调用后直接block,属于同步调用,直到依赖服务返回单条结果,或者抛出异常
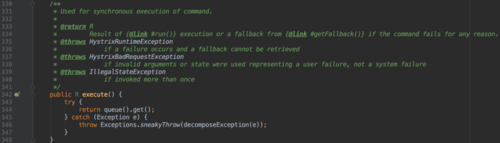
queue():返回一个Future,属于异步调用,后面可以通过Future获取单条结果

observe():订阅一个Observable对象,Observable代表的是依赖服务返回的结果,获取到一个那个代表结果的 Observable对象的拷贝对象
toObservable():返回一个Observable对象,如果我们订阅这个对象,就会执行command并且获取返回结果
R value = command.execute(); Future<R> fValue = command.queue(); Observable<R> ohValue = command.observe(); Observable<R> ocValue = command.toObservable();
3. 检查是否开启缓存
如果这个command开启了请求缓存request cache,而且这个调用的结果在缓存中存在,那么直接从缓存中返回Observer结果。
一般来说,所谓的request cache只是针对一次request context,类似于web应用中响应一个请求去调用多个依赖服务,对同一个依赖的相同参数的调用可以放到缓存从而减少网络请求来提升性能。
具体实现可以通过添加过滤器来添加一个HystrixRequestContext
public class HystrixRequestContextServletFilter implements Filter { public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext(); try {
chain.doFilter(request, response);
} finally {
context.shutdown();
}
}
}在Command实现中有CacheKey的设定方法:
public class CommandUsingRequestCache extends HystrixCommand<Boolean> {
... @Override
protected String getCacheKey() { return String.valueOf(value);
}
}4.检查是否开启了断路器
在命令结果没有缓存命中的时候, Hystrix 会在执行命令前检查断路器是否为打开状态
即检查这个command对应的依赖服务是否开启了断路器
断路器被打开,不执行该command,直接执行fallback降级机制
断路器被关闭,第5步
断路器的实现原理:
控制短路器是否允许工作,包括跟踪依赖服务调用的健康状况,以及对异常情况过多时是否允许触发短路,默认是true,一般不需要修改

只要执行一个command,这个请求就一定会经过断路器
如果在一定时间内经过断路器的流量超过阈值,才会进行后面的断路器相关处理
可以通过以下配置修改,默认值是20
如果断路器统计到的异常调用的占比超过了一定的阈值,才会打开断路器开关
默认是50%的异常比例
经过以上步骤,然后断路器
从close状态转换到open状态断路器打开的时候,所有经过该断路器的请求全部被短路,不调用后端服务,直接走fallback降级(第8步)
经过了一段时间之后,
断路器会进入half-open状态,让一条请求经过断路器,看能不能正常调用
如果调用成功了,那么就自动恢复,
转到close状态
时间可以通过以下配置来修改,默认为5000毫秒
可以强迫打开短路器,一般不使用

强迫关闭短路器,一般不使用

5.检查线程池/队列/semaphore是否已满
如果command对应的线程池/队列/semaphore(不使用线程池时)已经满了,那么也不会执行command直接去调用fallback降级机制
6.执行command
调用HystrixObservableCommand.construct()或HystrixCommand.run()来实际执行这个command
HystrixCommand.run() 返回单条结果,或者抛出一个异常
HystrixObservableCommand.construct() 返回一个Observable对象,可以获取多条结果或者 onError 发送错误通知
如果HystrixCommand.run()或HystrixObservableCommand.construct()的执行,超过了timeout
那么command所在的线程就会抛出一个TimeoutException,会去执行fallback降级机制,而且就不会管run()或construct()返回的值
这里要注意的一点是,我们是不可能终止掉一个调用严重延迟的依赖服务的线程的,只能说给你抛出来一个TimeoutException,但是还是可能会因为严重延迟的调用线程占满整个线程池的,即使这个时候新来的流量都被限流了。如果没有timeout的话,那么就会拿到一些调用依赖服务获取到的结果,然后hystrix会做一些logging记录和metric统计。
有一个很重要的点,command的执行强烈建议我们设置一个timeout的时间,来避免所有资源都被占用导致系统整体性能下降,可以通过以下来配置:
//默认是true打开超时控制HystrixCommandProperties.Setter() .withExecutionTimeoutEnabled(boolean value)//默认1000msHystrixCommandProperties.Setter() .withExecutionTimeoutInMilliseconds(int value)
当command执行超时之后会直接进行fallback降级处理
7.短路健康检查
Hystrix会将每一个依赖服务的调用成功,失败,拒绝,超时,等事件,都会发送给circuit breaker断路器
短路器就会对调用成功/失败/拒绝/超时等事件的次数进行统计。短路器会根据这些统计次数来决定,是否要进行短路,如果打开了短路器,那么在一段时间内就会直接短路,然后如果在之后第一次检查发现调用成功了,就关闭断路器
8.调用fallback降级机制
一般来说有四种情况会调用fallback降级机制
Hystrix调用各种外部接口,或者访问外部依赖,mysql,redis,zookeeper,kafka,等等出现了任何异常
对外部的依赖调用所使用的线程池已满/信号量限流资源到达极限
访问时间过长,可能就会导致超时,报一个TimeoutException异常
基于上述三种情况都会发送异常事件到断路器中去进行统计,如果异常达到一定的比例直接开启断路器
两种常见的降级处理是
维护内存ECache直接获取一份过期的数据
设定一个默认值返回
public class CommandHelloFailure extends HystrixCommand<String> { private final String name; public CommandHelloFailure(String name) { super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")); this.name = name;
} @Override
protected String run() { throw new RuntimeException("this command always fails");
} @Override
protected String getFallback() { return "Hello Failure " + name + "!";
}
}HystrixObservableCommand,是实现resumeWithFallback方法
一般在降级机制中,都建议给出一些默认的返回值,比如静态的一些代码逻辑,或者从内存中的缓存中提取一些数据,尽量在这里不要再进行网络请求了。即使在降级中,一定要进行网络调用,也应该将那个调用放在一个HystrixCommand中,进行隔离
设置fallback.isolation.semaphore.maxConcurrentRequests,这个参数设置了HystrixCommand.getFallback()最大允许的并发请求数量,默认值是10,也是通过semaphore信号量的机制去限流。如果超出了这个最大值,那么直接被reject
HystrixCommandProperties.Setter().withFallbackIsolationSemaphoreMaxConcurrentRequests(int value)
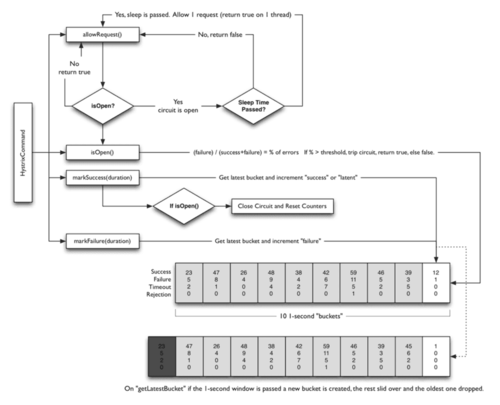
流程说明:1:每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中2:执行execute()/queue做同步或异步调用.3:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤.4:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤.5:调用HystrixCommand的run方法.运行依赖逻辑5a:依赖逻辑调用超时,进入步骤8.6:判断逻辑是否调用成功6a:返回成功调用结果6b:调用出错,进入步骤8.7:计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态.8:getFallback()降级逻辑. 以下四种情况将触发getFallback调用: (1):run()方法抛出非HystrixBadRequestException异常。 (2):run()方法调用超时 (3):熔断器开启拦截调用 (4):线程池/队列/信号量是否跑满8a:没有实现getFallback的Command将直接抛出异常8b:fallback降级逻辑调用成功直接返回8c:降级逻辑调用失败抛出异常9:返回执行成功结果
2.5 熔断器:Circuit Breaker
每个熔断器默认维护10个bucket,每秒一个bucket,每个bucket记录成功,失败,超时,拒绝的状态
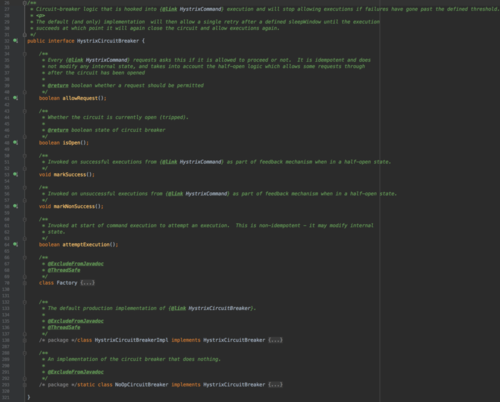
默认错误超过50%且10秒内超过20个请求进行中断拦截.
2.6 Hystrix隔离分析
Hystrix隔离方式采用线程/信号的方式,通过隔离限制依赖的并发量和阻塞扩散
2.6.1 线程隔离
把执行依赖代码的线程与请求线程分离,请求线程可以自由控制离开的时间(异步)
通过线程池大小可以控制并发量,当线程池饱和时可以提前拒绝服务,防止依赖问题扩散
线上建议线程池不要设置过大,否则大量堵塞线程有可能会拖慢服务器
2.6.2 特点分析
优点
使用线程可以完全隔离第三方代码,请求线程可以快速返回
当一个失败的依赖再次变成可用时,线程池将清理,并立即恢复可用,而不是一个长时间的恢复
可以完全模拟异步调用,方便异步编程
缺点
线程池的主要缺点是它增加了cpu,因为每个命令的执行涉及到排队(默认使用SynchronousQueue避免排队),调度和上下文切换。
对使用ThreadLocal等依赖线程状态的代码增加复杂性,需要手动传递和清理线程状态。
NOTE: Netflix公司内部认为线程隔离开销足够小,不会造成重大的成本或性能的影响。
Netflix 内部API 每天100亿的HystrixCommand依赖请求使用线程隔,每个应用大约40多个线程池,每个线程池大约5-20个线程。
2.6.3 信号隔离
信号隔离也可以用于限制并发访问,防止阻塞扩散, 与线程隔离最大不同在于执行依赖代码的线程依然是请求线程(该线程需要通过信号申请)
如果客户端是可信的且可以快速返回,可以使用信号隔离替换线程隔离,降低开销.

4 参数配置


4.1 参数说明
其他参数可参见 https://github.com/Netflix/Hystrix/wiki/Con




作者:芥末无疆sss
链接:https://www.jianshu.com/p/ec992a2f7f37
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。





