
近日Google开源了一个基于观察者模式的项目Agera:Reactive Programming for Android。还是菜鸟的我刚看完RxJava就发现Google开源了一个"类似"的项目自然得学习一下。本来结合自己的理解简单介绍一下Agera的基本概念和原理以便更好的使用Agera。
什么是Agera
Agera is a set of classes and interfaces to help write functional, asynchronous, and reactive applications for Android.Requires Android SDK version 9 or higher.
Agera是用于Android开发者更方便地开发函数,异步,响应式程序的框架,它要求Android SDK版本9以上。
Agera是一个超轻量的Android库,有助于准备数据用于让Activity或者其中的事物(例如View)这些具有生命周期的事物消耗。它介绍了一种函数式响应编程,有助于更清晰的分离when,where以及what这三个数据处理流的要素,以及用近乎自然语言这样简洁的表达式来描述复杂,异步的流程。
要学会知道怎么使用应该先知道Agera的原理吧,因此接下来详细地介绍一下Agera。。
一、Reactive Programming
Ageray的响应式编程范型以著名的观察者模式作为他的驱动机制。一个可观察物通过接口 Observable 描述,并且有责任去广播事件给所有注册的观察者。一个观察者通过接口 Updatable 描述,可以注册以及从 Observable对象取消注册,并且通过更新它自己来响应事件。
接下来的文档也将用observable和updatable来代表实现了这两个接口的java对象。
push event ,pull data
Agera使用的是push事件,pull数据的模型。这就意味着事件本身不携带数据,当updatable响应事件时如果需要的话就必须自己从它的数据源中抓取数据。
用这种方法,就把接口Observable供应数据的责任移除了,允许接口封装简单的事件(例如一次按钮的点击,一次下拉刷新的触发)用于广播。但是,observable通常也能提供数据。如果一个observable能够提供数据并且将一个事件定义为一次其供应的数据的改变,那么这个observable就被称做Repository(实现了Suppiler的Observable)。这样依然没有改变push事件 ,pull数据的模型:当数据改变时这个Repository通知所有注册的push event, pull data更新他们自己;当他们分别响应事件时从Repository中拉取数据。这个模型的优点就是分离数据消耗与事件分发,也就允许Repository执行懒计算。
取决于push event, pull data和一般的多线程处理,一个updatable可以不会见到repository提供的数据所有的改变历史。这是故意如此的:在大多数情况下(特别是当更新App的UI),只需要处理最近的,最新的数据。
Agera风格的响应式客户端的标准实现需要由下面几点组成:
将updatable注册到一个合适的observable用于通知相关事件
人为随意调用updatable初始化或者纠正客户端状态
updatable等待被任意observable调用,当updatable被调用时更新客户端状态必要时使用从数据源新拉到的数据。
当响应不再需要的时候取消updatable对同一组observable的注册
二、Observables and updatables
正如之前提到的,一个observable代表一个事件源,一个updatable观察这些事件。一个updatable通过Observable.addUpdatable(Updatable)注册到observable,通过Observable.removeUpdatable(Updatable)取消注册。一个事件以Updatable.update()的形式被发送到updatable。
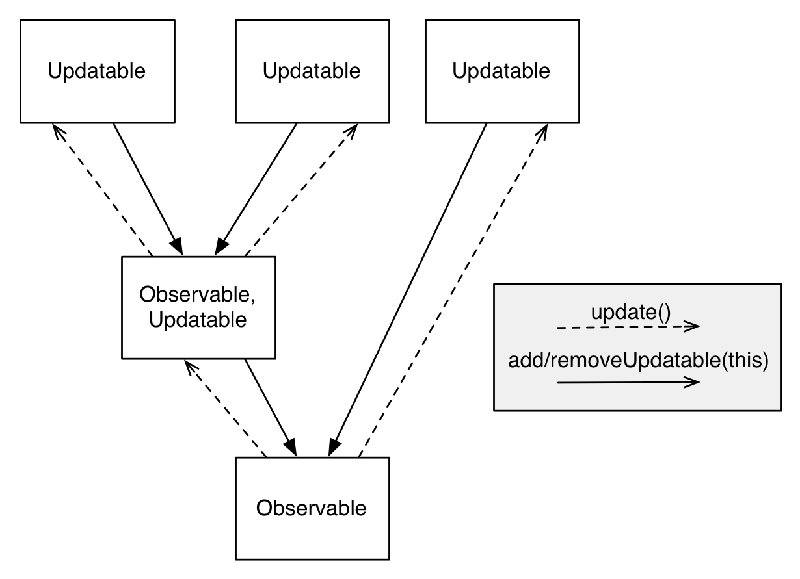
Observables and updatables.png
一个Activity可以观察来自于observable的事件:
public class MyUpdatableActivity extends Activity implements Updatable { private Observable observable; @Override
protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState);
observable = new MyObservable();
} @Override
public void update() { // Act on the event
} @Override
protected void onResume() { super.onResume();
observable.addUpdatable(this);
update();
} @Override
protected void onPause() { super.onPause();
observable.removeUpdatable(this);
}
}在上面的代码中,observable在onResume()中被激活,在onPause()中被失效,observable的生命周期与Activity的生命周期相匹配。
Updatable注册与取消注册应该成对出现。再次添加一个相同的updatable到observable是非法的。从observable移除一个updatable当该updatable尚未注册到observable上或者已经取消注册都是非法的。
Activation lifecycle and event chain
一个observable当它被至少一个updatable观察时它处于active状态,当他不被任意一个updatable观察时处于inactive状态。从另一个角度说:一个updatable通过注册到处于inactive的observable上来激活observable;当处于active的observable仅具有一个注册的updatable时,该updatable通过取消注册来使其停用。

Activation lifecycle and event chain.png
一个observable可能观察其它的在其“上游”(就事件传播路径而言)的observable并且将他们的event转化为自身的事件,一个很普通的例子就是一个数据依赖于其它repository的repository。就正确的配线方式而言,如此一个中间的observable通常保持对其上游observable的强引用,但是仅仅当它自身是active时将他内部的updatable注册到其上游observable上,当他处与inactive时取消内部updatable的注册。这就意味着他在下游方向的强引用仅当有别的updatable注册到它上面时存在。这也意味着最下游的updatable最终控制在事件链上所有的observable的激活与失效。
UI lifecycle
这个事件链特别适合伴随UI的生命周期构建响应式结构。允许一个U元素是一个Activity,一个Fragment,或者在之内的view,它的活动生命周期可以通过一些Android生命周期事件对进行定义,例如从onStart到onStop,从onResume到onPause,从onAttachedToWindow到onDetachedFromWindow以及其他的。允许这个UI元素是或者持有一个updatable用于更新UI,该updatable使用repository提供的数据。该repository反过来使用其它的事件源和数据源(未必是repositories)来计算数据。
在UI元素的生命周期的开端,上述的updatable注册到repository并因此激活它。这将连接上事件链并激活相关的数据处理流,使数据和UI最新。
在UI的生命周期的结尾事,上述的updatable从相同的repository上取消注册,假设此时该事件链上没有其它的updatable使得任意observable保持active,这将导致该事件链连锁拆卸。如果UI元素将不再活跃(由于例如activity将被摧毁),因为当系统处于inactive状态时,在事件链中并没有下游引用,所以该UI元素可以自由的被回收,也就避免了activity泄漏。

UI Lifecycle
Threading
Agera提倡明确的线程处理,使用Loopers(有大量可用的lOOPER,例如app的主Looper和IntentService工作线程的Looper)来帮助定义下列线程处理契约。
就内部的激活生命周期处理,每一个observable与其被创建时所在的线程的Looper(worker Looper)有一生的联系。该observable被激活和失效均来自该worker Looper。如果这个observable观察处于激活状态的其它observables,那个这个observable的updatable将从这个worker Looper注册到其上游的observables上。
一个updatable必须从一个Looper 线程注册到一个observable上,这个线程不需要和运行observable‘s worker looper的线程相同。observable会使用同一个Looper Thread来发送Updatable.update()调用updatable。
一个updatable可以从任何线程取消注册。但是为了避免由于Looper的内部处理updatable取消注册之后事件被发送到updatable的情况,推荐在updatable注册所发生的线程里进行updatable的取消注册操作。
Looper只要有observable或者注册的updatable依赖于他,开发者就有责任使它保持激活存活状态。由于死亡的Looper导致的异常和内存泄漏是开发者的责任(Agera是不会背这个锅的)。实际上,除了使用一直存活的主Looper以外很少使用其他的Looper。
三、Repositories
上文已经提到,一个Repositories是一个可以提供数据的observable,它将一个事件定义为提供的数据的一次改变。提供的数据可以通过Repository.get()获取。
Simple repositories
一个简单的repository可以通过Repositories中的方法创建。
有两个选择:
提供相同数据并且不生成事件的静态的repository()(repository(object))。
无论何时value被更新成了另一个value(通过Object.equals(Object))允许改变value和生成事件的可变repository(mutableRepository(object))。
这里两种方法均会调用SimpleRepository(@NonNull final T reference, boolean mutable),只是所传的mutable参数的不同。
天生的,这些简单的repositories无论是否激活通常都能提供最新的数据。
Complex repositories
一个复杂的repository可以响应其它的repository或者任意通常的observable(该repository的事件源),以同步或者异步的方式,通过内部程序将从其他数据源获取到的数据转换生成自身的数据。r该epository提供的数据对事件源的事件做出响应保持最新,但是由于程序处理的复杂性,当repository处于inactive时可能不会选择将数据保持最新。任何数据消费者必须通过注册一个updatable来表达他想消费数据的企图。这样的操作会激活repository,但是未必迅速使数据最新;在repository发送第一个事件之前数据消费者可能仍然看到过时的数据。
Agera提供repository compiler,用近乎自然语言来声明和实现一个complex repository.
四、Compiled repositories
一个complex repository可以通过一个单独的java表达式编成。这个表达式由以下几部分组成:
Repositories.repositoryWithInitialValue(...);
Event sources - .observe(...);
Frequency of reaction - .onUpdatesPer(...) or .onUpdatesPerLoop()
Data processing flow - .getFrom(...), .mergeIn(...)
, .transform(...), etc.;Miscellaneous configurations - .notifyIf(...) , .onDeactivation(...), etc.;
.compile()
这个我想在后面结合Demo再详细的理解,这里就仅仅是一些介绍。
当被编成的repository被激活时,它注册一个内部的updatable到给定的事件源并开始第一次开启数据处理流来计算暴露的数据。这个数据处理流响应来自事件源的事件再次更新数据。在第一次计算完成前,这个repository暴露初始化数据也就是repositoryWithInitialValue所指定的数据。无论何时数据被更新,repository的客户端(我觉得可以理解为监听他的updatable)被通知。当repository被去活化时,内部的updatable从事件源中取消注册,数据处理流不再运行,所以内部的数据可能变得过时。当再次激活,数据将再一次更新。
表达式中不同的阶段用嵌套在RepositoryCompilerStates接口中编译状态接口描述。这些接口在每个阶段仅仅暴露一些合适的方法来引导开发者去正确的补全表达式(可以使用IDE的自动补全).
这些方法的完整文档可以在这些接口中看到;特别是接下来的每个部分:
响应的事件源和频率:RFrequency和他的父类REventSource
数据处理流:RFlow和他的父类RSyncFlow
各种各样的配置:RConfig
这个repository编写表达式不应该在中间被打断。为了捕获一个变量的中间对象或者将其转换为另一个接口的用法是不支持的。
编写一个repository会招致一些开销,但是之后的操作是相当轻量的。任何repository最好是和一些具有生命周期的例如activity,可复用的view hierarchy等高级组件或者服务于整个应用的全局单例的创建相关联。特别是complied repository,因为他的编译的确会造成开销(发生在运行时)。
When, where, what
编成的repository表达式清晰的记载了whenrepository响应事件,where响应发生的线程,what构成了暴露的数据。
repository按照给定的频率监听给定的事件源,这两部分组成了when要素。
数据处理流指定了数据的起源以及repository中数据的计算,这就是what要素。
由于要使用内部的updatable,他必须从一个Looper Thread注册到事件源,所以编成的repository就和一个worker Looper相关联了(接下来Asynchronous programming会讲到)。在数据处理流中,可以插入指令使处理流移动到java Executors上。这样明确的线程处理设计组成了where要素。
Data processing flow
数据处理流由指令组成,每一条指令接收一个输入变量并为下一条指令生成一个输出变量。第一条的指令的输入变量类型是repository的变量类型,同时也是最后一条以then开头的指令的输出变量的类型。这些编译者状态接口只要可能就使用通用的类型参数来确保类型安全,伴随着输入类型的抗变性(下一条指令可以接收当前指令的输出类型的父类)和输出类型的共分散(最后一条指令可以生成该repository的变量类型的子类)(这句话我也表示有点懵逼,后面再结合源码理解一下)。
当数据流运行时,通过Repository.get()取出的当前repository的变量被用来当做第一条指令的输入变量。如果在这之前数据流尚未更新数据或者repository因为RepositoryConfig.RESET_TO_INITIAL_VALUE配置而被重置,这个数据可能是repository的初始化数据。指令被有序的运行来转换这个输入的变量。运行生成最终变量的以then开头的指令或者运行一条结束流并生成一个变量的终止子句(例如orEnd,通过RTermination状态接口描述,接下来会在“Attempts and Result”中描述)后,数据处理流通常会结束,在这种情况下,repository数据被更新并通知注册的updatable。如果使用.thenSkip()指令或者其他跳过接下来操作的终止子句例如orSkip(),该数据流会被突然终止并且跳过更新自身数据并且不会通知更新。
Operators
为了让数据流可以调用客户端代码逻辑,Agera指定一下接口各自提供了一个方法:
Supplier.get(): a 0-input, 1-output operator;
Function.apply(TFrom): a 1-input, 1-output operator;
Merger.merge(TFirst, TSecond): a 2-input, 1-output operator.
下面的指令会使用它们:.getFrom(Supplier) and variants;
.transform(Function) and variants;
.mergeIn(Supplier, Merger) and variants
.getFrom(Supplier)表示忽略输入变量,使用从给定Supplier中获取数据作为输出变量;.transform(Function)表示将给定的Function将输入变量转换为输出变量;.mergeIn(Supplier, Merger)表示将输入变量和从Supplier中新拿到的数据通过Merger转换为输出变量。
正如下面图片所示:

Operators.png
为了更高级的功能,数据处理流提供了非线性的操作(数据通过这个方法到流的外面,或者终止流,具体的信息可以去看源码,文档中有描述)。这些方法通过下面的接口提供:
Receiver.accept(T): a 1-input, 0-output operator;
Binder.bind(TFirst, TSecond): a 2-input, 0-output operator;
Predicate.apply(T): an operator that checks the input value for a yes-or-no answer.
下面的指令会使用这些操作:.sendTo(Receiver) and variants;
.bindWith(Supplier, Binder) and variants;
.check(Predicate).or,and variants,
.sendTo(Receiver)表示将输入的变量发送到给定的receive,然后传递输入变量当做指令的输出变量;.bindWith(Supplier, Binder)表示将输入变量和Supplier中的数据传递给Binder,然后不修改输入变量作为输出变量;.check(Predicate)表示如果Predicate适用于输入变量,则流继续运行,否则执行之后的终止子句并将该输入变量作为子句指令的输入变量。

Operators.png
为了实现模块化结构,Repository实现了Supplier接口,MutableRepository实现了Supplier和Receiver,所以可以直接在complex repository中作为操作符。
Attempts and Result
功能接口Supplier,Function和Merger被定义成不抛出异常,但是实际上,很多操作可能会失败。为了捕获这些失败,Agera提供了一个包装类Result,这个类封装了(不管是成功或者失败)操作或者尝试的结果。这些尝试可能作为一个Supplier, Function或者Merger来实现,并且会返回一个结果。
* An immutable object encapsulating the result of an <i>attempt</i>. An attempt is a call to
* {@link Function#apply}, {@link Merger#merge} or {@link Supplier#get} that may fail. This class
* helps avoid throwing exceptions from those methods, by encapsulating either the output value of
* those calls, or the failure encountered. In this way, an attempt always produces a {@link Result}
* whether it has {@link #succeeded} or {@link #failed}.
*
* <p>This class can also be used to wrap a nullable value for situations where the value is indeed
* null, but null is not accepted. In this case a {@link Result} instance representing a failed
* attempt to obtain a non-null value can be used in place of the nullable value.数据流提供了一系列能意识到失败的指令,如果失败发生,这些执行可以终止数据流并执行后续的终止子句:
.attemptGetFrom(Supplier).or…;
.attemptTransform(Function).or…;
.attemptMergeIn(Supplier, Merger).or…,
.or...代表的是终止子句,由上面的RTermination接口描述。.orSkip()表示一旦失败就跳过更新。.orEnd(Function)表示一旦失败就结束当前数据流并用Function生成的结果更新当前编成repository的数据,如果需要的话会通知相关的updatable。
因为这些.attempt*指令确保下一条指令只会接收到正确的结果,内部使用的操作符生成Result<T>,所以这些指令的输出类型是T而不是Result<T>,例如attemptGetFrom所示:
RTermination<TVal, Throwable, ? extends RSyncFlow<TVal, TCur, ?>> attemptGetFrom( @NonNull Supplier<Result<TCur>> attemptSupplier);
Supplier会生成Result<TCur>,但是attempGetFrom会得到一个TCur类型的结果。
对称的,一个操作符也可以是recovery operation(这个单词我感觉怎么翻译都不恰当),也就是可以使用Result类的变量作为输入。一个操作符使用Result类变量作为输入并且生成Result类输出,就被称作attempt recovery operator。例如:
private static final class HttpResponseToBitmap
implements Function<Result<HttpResponse>, Result<Bitmap>> { @NonNull
@Override
public Result<Bitmap> apply(@NonNull final Result<HttpResponse> input) { final byte[] body = input.get().getBody();
Bitmap bitmap = decodeByteArray(body, 0, body.length);
Log.i(TAG,"HttpResponseToBitmap apply "+(bitmap!=null)); return absentIfNull(bitmap);
}
}为了在数据处理流中使用这样的操作符,之前的指令是不能意识失败的(即便使用了attempt操作符),所以之前指令的成功和失败的结果(以Result的类型)recovery operator都能收到。
Asynchronous programming
这个repository必须在一个Looper线程(通常是主线程)上编成。这个Looper就是这个repository的的worker repository,接下来的处理也会在这个Looper线程上执行:
客户端updatable的注册与取消注册
对事件源的监听,处理和限制频率
开启一个新的数据处理流
这个数据处理流不要求在这个Looper线程上同步的完成。特殊的指令 .goTo(Executor) 和 .goLazy() 确保异步编程。这些指令不改变输入的变量;它们仅仅在运行时控制流的延续:.goTo(Executor)将剩下的执行指令发送到给定的Executor,.goLazy()将暂停执行直到Repository.get()第一次被调用。
在.goTo(Executor)之后,该worker Looper线程被释放可以用处理其他的事件,这个repository同时可能通过他的updatable被失效或被事件源通知更新。在后一种情况,为了减少竞争条件,这个数据处理流被调度重新开始运行而不是开启一个和正在运行的流同时运行。这repository可以通过onDeactivation和onConcurrentUpdate配置来取消这个流。这个有助于保护资源(就失效而言)和快速重新运行(就更新而言)。一个被取消的流禁止改变repository的数据和通知updatable更新。取消行为可以通过.onDeactivation(int) 和.onConcurrentUpdate(int)来配置,这两个方法在RConfig状态接口中定义。
就.goLazy()指令而言,如果repository数据发生更新,那么他的updatable会被通知更新,但是是否去更新repository要取决于后面的指令。当Repository.get()被调用时,因为该方法需要产出一个数据,该数据流将在这个线程同步重新启用并且从此时忽略取消信号。另一方面,如果在Repository.get()重新运行这个暂停流之前repository收到一个来自事件源的更新通知,暂停状态和中间的变量将被丢弃,接下来的指令也不会再次运行,这个流将快速重启。在流重启之后并且在再次到达.goLazy()指令之前调用Repository.get()将会返回repository的上一个数据。因为.goLazy()有助于跳过不必要的计算,有策略的使用它有助于提升程序的执行。
五、Compiled functions
compiled repository的数据处理流是一种数据结构不可知论者(除了Result包装)。实际上,数据流很普遍的用于处理lists数据(例如在RecyclerView中使用)。举个特例,接下来是一个通过网络的一系列数据的程序的流程:
Download the data as a byte array;
Parse the data into some object representation;
Extract the items from the object representation;
Perform any additional transformation for each item into a form (UI model object) ready to render by an Adapter, and/or, perform any filtering task on the list to include or exclude specific items;
Set the resulting list as the data source of the Adapter.
开发者可能打算将前四步封装到一个function来让compiled repository调用,并且用一个updatable用第5步来响应这个提供了很多UI模型对象的repository。如果更多的子程序(例如将数据模型转换为UI模型)是分离可用的,将这些全部程序封装成一个function,这样更容易使用和增加可读性。
Agera提供了一种类似于complied repository的风格来使用可重用的小操作符来编写function:
// For type clarity only, the following are smaller, reused operators:Function<String, DataBlob> urlToBlob = …; Function<DataBlob, List<ItemBlob>> blobToItemBlobs = …; Predicate<ItemBlob> activeOnly = …; Function<ItemBlob, UiModel> itemBlobToUiModel = …; Function<List<UiModel>, List<UiModel>> sortByDateDesc = …; Function<String, List<UiModel>> urlToUiModels = Functions.functionFrom(String.class) .apply(urlToBlob) .unpack(blobToItemBlobs) .filter(activeOnly) .map(itemBlobToUiModel) .morph(sortByDateDesc) .thenLimit(5);
这个function的可读性棒吧!!!
就可复用性这个术语而言,意味着这段操作背后的逻辑在其它地方也需要。在complied function中只需要很少的工作就将它们封装成了Function接口,如果读过代码,右边的表达式最终将生成一个ChainFunction类型。为了使用FunctionCompiler 预先准备了很多Function/Predicate定义,这就导致了很多花费(编译时需要编译附加的类,运行时需要加载这些类,生成这些对象,并且链接它们变成一个Complied function)。这种方法可能会比直接自己写自定义function更糟糕。所以开发者一定要考虑仅当只减少代码行数的时候才应该使用function compiler。
function compiler通过定义在FunctionCompilerStates的编译者状态接口支持。如同repository compiler,这个表达式同样不能在中间被打断。
六、Reservoirs and parallelism
取决于push event,pull data模型和一般的多线程处理,一个updatable可能不会见到repository的数据的所有改变历史。这是因为在大多数情况下(特别是用于更新App的UI),只有最近,最新的数据需要处理。但是,如果updatable需要知道所有的改变的数据改变历史呢?Agera提供了一个Repository的子类Reservoir。在这种情况Reservoir很适用。
public interface Reservoir<T> extends Receiver<T>, Repository<Result<T>> {}Reservoir是Queue的响应式版本。数据可以通过Receiver接口进队到reservoir,这会通知他的客户updatable,这个updatable会通过Repository(准确说是Supplier)接口反过来是相同的数据出队。reservior的访问是同步的,所以不可能有两个客户出队同一个实例(在这个地方,实例被定义为一个成功入队的数据;如果同一个变量(同一个java对象引用)被多次入队,在reservoir里他们是不同的实例)。reservoir返回结果类型是被Result包装了的,所有如果一个客户当repository是空的时候试图出队数据,他将收到Result.absent()作为一个失败的提示。
reservoir更适合于作为必须响应每一个数据的响应者的事件源。如果合适的话,可以使用complied repository实现响应者,它使用reservoir作为它的事件源之一,利用.attemptGetFrom(reservoir).orSkip()开启数据处理流。只要repository处于激活状态,在reservoir和complied repository之间的observable-updatable关系将会消费所有提交到reservoir的数据。
简单的并行可以使用一个reservoir和compiled repositories的多个实例,这些repository均按照上述的方式使用reservoir作为它的事件源。数据可以被提交给reservoir,然后每一个repository都试图出队该数据用于自身的数据处理流。为了实现真正的并行,这些repository必须将处理移动到多线程的执行器或者在不同的worker Looper运行。
七、Custom observables
Agera可以很简单的实现自定义Observable。
Proxy observables
一个代理observable传递其它observable(其它源observable)的事件,对于这些事件做一些小的或不处理。类Observables提供了下列标准代理observable的创建方法:
compositeObservable that composites multiple source observables;
conditionalObservable that suppresses events from a source observable during the times a specified condition does not hold;
perMillisecondObservable and perLoopObservable that throttle the event frequency of a source observable.
提供了三种代理Observable:compositeObservable组合了多个源observable,conditionalObservable当指定条件未达到时压制源observable的事件,perMillisecondObservable 和 perLoopObservable则压制源observable发送事件的频率。
BaseObservable
BaseObservable完整的实现了updatable的注册,取消注册,和通过线程处理通知更新。通过继承它可以很简单建立一个自定义observable。无论何时需要发送事件,子类只需要在任意线程简单的调用dispatchUpdate()。下面的例子是将一个view的点击事件转换为一个observable:
public class ViewClickedObservable extends BaseObservable
implements View.OnClickListener { @Override
public void onClick(View v) {
dispatchUpdate();
}
}BaseObservable的子类可以通过重写observableActivated()
和 observableDeactivated()监控这个observable的激活生命周期。observableActivated()将在生命周期的开端被调用, observableDeactivated()将在生命周期结束时被调用(顺便提一句:observable的观察者从0到至少一个表示激活,从至少一个到0个表示失活,中间这段时间就是他的生命周期)。这两个方法被BaseObservable的worker Looper线程调用,这个线程指的是创建Baseobservable实例的线程。在大多数情况下所有的observable的worker Looper都是主线程的Looper,这也就减轻了同步锁的需求。
UpdateDispatcher
当不能直接继承BaseObservable或者不是最优时,例如该类已经继承了另外一个类,依然很容易去实现Observable接口。一个UpdateDispatcher实例有助于实现一个用和BaseObservable同样的方式管理updatable的,遵从线程处理约定的自定义Observable。
这个自定义observable需要通过或者重载Observables.updateDispatcher()来私有地持有一个update dispatcher,这个方法会接收一个ActivationHandler实例。ActivationHandler接口定义了observableActivated
和 observableDeactivated来监听生命周期。和BaseObservable一样,update dispatcher同样需要一个worker looper用于工作,所以必须在在一个Looper线程中创建。
该自定义observable可以简单的调用update dispatcher实现所有updatable的注册与取消注册。为了发送事件给所有的客户updatable,可以通过调用UpdateDispatcher.update()。看名字就知道UpdateDispatcher是一个updatable,所以如果要自定义的observable是一个proxy observable并且需要注册内部的updatable到其它的事件源,UpdateDispatcher是一个很好地选择。
额外的提示,UpdateDispatcher同样是Observable的子类,所以也能当做一个基本的observable使用。正如mutable repository连接了数据的生产者和消费者,UpdateDispatcher连接了事件的生产者和消费者。MutableRepository继承了Repository,Receiver,数据生产者通过他的Receiver接口端提供数据给它,数据消费者通过Repository接口端从它获取数据并消费数据。同样的,UpdateDispatcher继承了Observable和Updatable接口,事件生产者通过它的Updatable接口端发送事件给他,同时事件消费者通过它的Observable接口端接收事件。
八、Incrementally Agerifying legacy code
Agera介绍的风格可能更适合从头开始编写的新的app。接下来将是给希望将代码转换为Agera风格的开发者的tips。
Upgrading legacy observer pattern
观察者模式可以通过很多方式可以实现,但是不是所有的都能直接的迁移成observable-updatable结构。接下来就的通过给遗留的"listenable"类添加一个Observable借口来升级的例子。
类MyListenable通过addListener和removeListener来管理listener(Listener接口的实现)的添加和删除。作为演示,他继承SomebaseClass作为额外的负担。使用UpdateDispatcher来管理注册在其上的Updatable,并且使用内部类Bridge连接内部的UpdateDispatcher与Listener,这样在使它成为observable之时还能使用之前的API:
public final class MyListenable extends SomeBaseClass implements Observable { private final UpdateDispatcher updateDispatcher; public MyListenable() { // Original constructor code here...
updateDispatcher = Observables.updateDispatcher(new Bridge());//
} // Original class body here... including:
public void addListener(Listener listener) { … } public void removeListener(Listener listener) { … } @Override
public void addUpdatable(Updatable updatable) {
updateDispatcher.addUpdatable(updatable);
} @Override
public void removeUpdatable(Updatable updatable) {
updateDispatcher.removeUpdatable(updatable);
} private final class Bridge implements ActivationHandler, Listener { @Override
public void observableActivated(UpdateDispatcher caller) {
addListener(this);
} @Override
public void observableDeactivated(UpdateDispatcher caller) {
removeListener(this);
} @Override
public void onEvent() { // Listener implementation
updateDispatcher.update();//这样就将listener和UpdateDispatch联系起来了
}
}
}这句代码 Observables.updateDispatcher(new Bridge())会生成一个AsyncUpdateDispatcher,传入的Bridge作为其内部的activationHandler,具体的建议去看Observables#AsyncUpdateDispatcher。
Exposing synchronous operations as repositories
java本质上是一种同步性的语言,最低级的操作符都是同步方法实现的。当这个操作会花费一些时间来输出结果,我们称这个方法为阻塞的方法,并且开发者被警告不能在主线程调用它。
假设app的UI需要从一个阻塞方法获得数据,Agera提供了compiled
repository很方便让这个阻塞方法在后台的执行器处理,同时由于线程的处理,UI可以在观察repository的线程上消费数据。首先,方法被封装成Agera的操作符,如下
public class NetworkCallingSupplier implements Supplier<Result<ResponseBlob>> { private final RequestBlob request = …; @Override
public Result<ResponseBlob> get() { try {
ResponseBlob blob = networkStack.execute(request); // blocking call
return Result.success(blob);
} catch (Throwable e) { return Result.failure(e);
}
}
}
Supplier<Result<ResponseBlob>> networkCall = new NetworkCallingSupplier();
Repository<Result<ResponseBlob>> responseRepository =
Repositories.repositoryWithInitialValue(Result.<ResponseBlob>absent())
.observe() // no event source; works on activation
.onUpdatesPerLoop() // but this line is still needed to compile
.goTo(networkingExecutor)
.thenGetFrom(networkCall)
.compile();上面的片段假设在repository被编写之前就知道了request,并且这个request将不会改变。不能改变的request并没有什么卵用,所以为了可以改变request就需要进行升级。因此就用一个MutableRepository来存储提供request。为了使该repository被建成后就能提供第一个request,将request用Result封装并用absent()初始化repository。
// MutableRepository<RequestBlob> requestVariable =// mutableRepository(firstRequest);// OR:MutableRepository<Result<RequestBlob>> requestVariable = mutableRepository(Result.<RequestBlob>absent());
然后将阻塞的方法封装成Function:
public class NetworkCallingFunction
implements Function<RequestBlob, Result<ResponseBlob>> { @Override
public Result<ResponseBlob> apply(RequestBlob request) { try {
ResponseBlob blob = networkStack.execute(request); return Result.success(blob);
} catch (Throwable e) { return Result.failure(e);
}
}
}
Function<RequestBlob, Result<ResponseBlob>> networkCallingFunction = new NetworkCallingFunction()最终版的repository就如下了:
Result<ResponseBlob> noResponse = Result.absent(); Function<Throwable, Result<ResponseBlob>> withNoResponse = Functions.staticFunction(noResponse); Repository<Result<ResponseBlob>> responseRepository = Repositories.repositoryWithInitialValue(noResponse) .observe(requestVariable) .onUpdatesPerLoop() // .getFrom(requestVariable) if it does not supply Result, OR: .attemptGetFrom(requestVariable).orEnd(withNoResponse) .goTo(networkingExecutor) .thenTransform(networkCallingFunction) .compile();
基本上看名字也能理解吧,所以写表达式时最好能给操作符特定的命名,这样极大的增加可读性。
Wrapping asynchronous calls in repositories
现在很多库都提供了都提供了异步API和配套的线程调度功能,客户端代码无法控制或者取消线程的调度。使用这样的一个库可能会使Agerify整个app的难度增大。最显然的方式就是用上面演示的方式找到一个替代物。一种不推荐的方式就是运行到一个后台线程,执行异步调用,堵塞线程直到返回结果,然后再"同步"地返回结果。在这部分讨论的是当上述显然的方式不适用时一种恰当的变通方案。
一种循环的异步调用模式就是request-response结构.接下来的例子假设了一种详细的结构,这个结构可以取消未完成的工作,但是并没有指定调用callback的线程。首先应该很容易抽取出以下几个类:
interface AsyncOperator<P, R> { Cancellable request(P param, Callback<R> callback);
}interface Callback<R> { void onResponse(R response); // Can be called from any thread}interface Cancellable { void cancel();
}首先要执行request(),就需要有AsyncOperator接口实例;
其次request执行需要参数,由Supplier提供;为了能取消request操作那么又必须有Cancellable对象;然后会提供一个result的结果。
需要消费该result的对象就可以监听它来实现数据的更新
public class AsyncOperatorRepository<P, R> extends BaseObservable
implements Repository<Result<R>>, Callback<R> { private final AsyncOperator<P, R> asyncOperator; private final Supplier<P> paramSupplier; private Result<R> result; private Cancellable cancellable; public AsyncOperatorRepository(AsyncOperator<P, R> asyncOperator,
Supplier<P> paramSupplier) { this.asyncOperator = asyncOperator; this.paramSupplier = paramSupplier; this.result = Result.absent();
} @Override
protected synchronized void observableActivated() {
cancellable = asyncOperator.request(paramSupplier.get(), this);
} @Override
protected synchronized void observableDeactivated() { if (cancellable != null) {
cancellable.cancel();
cancellable = null;
}
} @Override
public synchronized void onResponse(R response) {
cancellable = null;
result = Result.absentIfNull(response);
dispatchUpdate();
} @Override
public synchronized Result<R> get() { return result;
}
}为了可以支持request参数的动态变化,那么提供参数的Supplier就必须同时可以被监听,因此参数的来源就变成了Repository(实现了Supplier的Observable),AsyncOperatorRepository也必须实现updatable接口。并且只有当有对象需要消费response也就是有updatable监听AsyncOperatorRepository的时候,AsyncOperatorRepository才会监听paramRepository。
public class AsyncOperatorRepository<P, R> extends BaseObservable
implements Repository<Result<R>>, Callback<R>, Updatable { private final AsyncOperator<P, R> asyncOperator; private final Repository<P> paramRepository; private Result<R> result; private Cancellable cancellable; public AsyncOperatorRepository(AsyncOperator<P, R> asyncOperator,
Repository<P> paramRepository) { this.asyncOperator = asyncOperator; this.paramRepository = paramRepository; this.result = Result.absent();
} @Override
protected void observableActivated() {
paramRepository.addUpdatable(this);
update();
} @Override
protected synchronized void observableDeactivated() {
paramRepository.removeUpdatable(this);
cancelOngoingRequestLocked();
} @Override
public synchronized void update() {
cancelOngoingRequestLocked(); // Adapt accordingly if paramRepository supplies a Result.
cancellable = asyncOperator.request(paramRepository.get(), this);
} private void cancelOngoingRequestLocked() { if (cancellable != null) {
cancellable.cancel();
cancellable = null;
}
} @Override
public synchronized void onResponse(R response) {
cancellable = null;
result = Result.absentIfNull(response);
dispatchUpdate();
} // Similar process for fallible requests (typically with an
// onError(Throwable) callback): wrap the failure in a Result and
// dispatchUpdate().
@Override
public synchronized Result<R> get() { return result;
}
}上面所描述的repository也就完美的封装了异步调用。
小结
谢谢您的阅读,由于理解有限,有误的地方还请多多指出。有时间的同学还是看看官方文档吧!
本来还想结合demo介绍用法的,后面发现自己太天真了,这篇介绍已经够长了,用法什么的还是下一篇再写吧。。。。





