
看过很多关于Python字符编码的博客,或深或浅,总感觉有点云里雾里,今天这里我尝试用我的方式也来凑个热闹。
首先,我们要弄清楚几个问题,这个对我们后面的理解非常重要。
- 字节与字符
- Python源代码文件的执行过程
- Python中的字符串与unicode字符串的区别
这是针对两个不同的对象创立出来的,人与字符, 机器与字节
字节是比较底层的概念,就是计算机里的0和1的组合,8个为一个字节。
这个是经过抽象后的,说白点,就是我们看见的一个一个的符号(比如汉字,标点,字母等等),是给人理解的。因为我们平时交流用的记号都是字符,而计算机存储,计算需要的是0和1的字节数据,这就存在一个映射关系,就是字符与字节的映射关系。
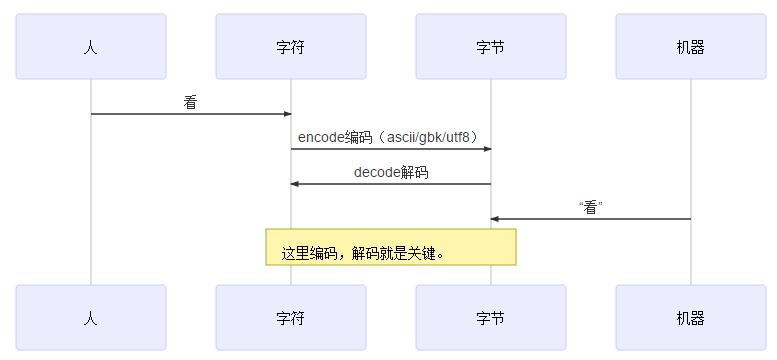
所以,就形成了人看字符,机器看字节。而字节 与 字符的转换就称为解码与编码,这个过程就需要指定转换规则,这个规则就是编码规则,比如utf8,ascii,gbk。
我们知道,磁盘上的文件都是二进制格式存放的,其中文本文件都是以某种特定编码的字节形式存放。对于源文件的编码是文本编辑器指定。当执行Python代码文件时,解释器字节后,需要将其转换为Unicode字符串(decode过程)之后才能操作。因此,对于文本编辑器编辑的一个Python源文件,当再次被读取执行之前的解码过程,就需要知道当初的编码原则,而这个解码过程就有个坑。
坑Python2的
默认解码ASCII,不能识别中文字符,这个当初utf8编码成字节文件就不能被解释器正确解码。而Python3默认的是utf8
因此,常见python2中,在源码文件头写上这个一个注释,_*_ coding:utf-8 _*_,来告知解释器文件编码,让其改变其默认解码规则。
# python2
import sys
sys.getdefaultencoding()
# 'ascii'
# Python3
import sys
sys.getdefaultencoding()
# 'utf-8'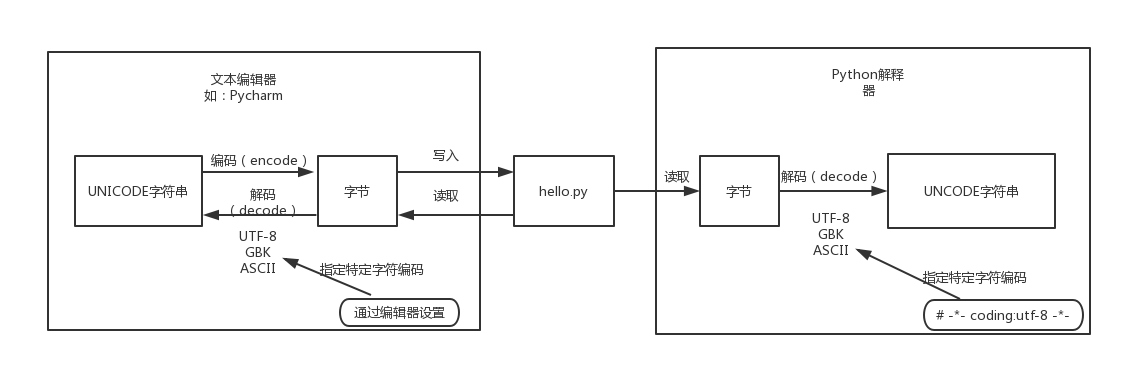
我们常见的解码错误(UnicodeEncodeError)就出现在解释器的解码环节。
Python中字符串与unicode字符串的区别Python2
Python2中对字符串的支持提供以下三个类:
- class basestring(object)
- class str(basestring)
- class unicode(basestring)
这里面,可以这么理解,str就是字节流形式的字节串,unicode就是字符,str当转换为unicode的时候,就是字节-->字符的过程,就需要编码,解码过程。
str用这个字符串的名字,这就跟我们平时理解的字符串不一致,其实是字节串和存在磁盘的字节一样一样的。
Python3
Python3提供的二个类:
- class bytes(object)
- class str(object)
Python3避免了这种概念上的混淆,把字节用bytes来表示,字符串用str来表示(而Python2用str来表示字节,unicode来表示字符),这就和我们上面认识的字节,字符的概念一致。
参考







