在上篇博文中,我们讲述怎样处理第l−1层到第l层的前向传输和反向求导,我们还没有讲述关于输出层的处理技术。在这里,我们还以MNIST手写数字识别为例,网络计算图如下所示:
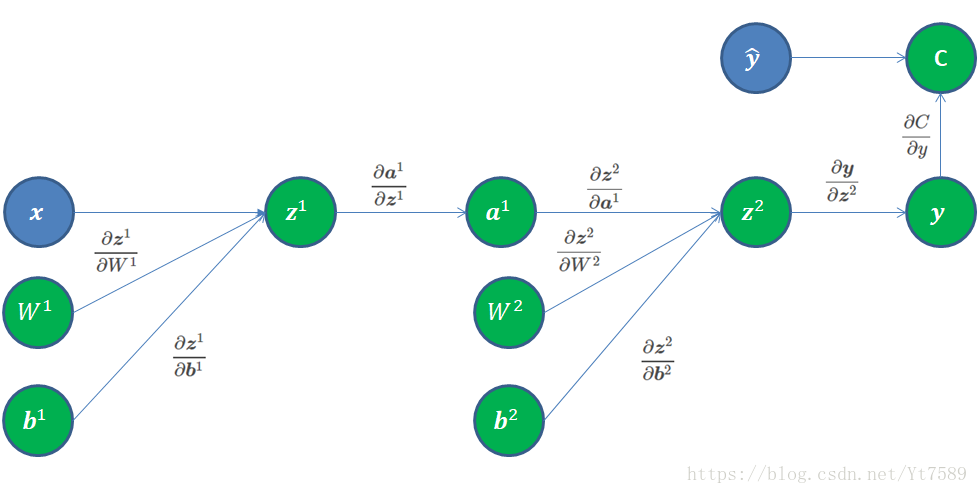
当我们计算出输出层的输出y∈R10时,表示输入图像x是0~9这10个数字的概率。此时输入图像x对应的正确结果y^∈R10,假设该数为r,则y^r=1,其余维0,即y^={0,0,...,1,...,0},其中主1的是第r维。
我们首先处理损失函数,这里我们假设不考虑添加调整项的情况,我们的代价函数取交叉熵(cross entropy)函数,根据交叉熵定义:
H(p,q)=Ep(−logq)=H(p)+KL(p∥q)
对离散值情况,交叉熵(cross entropy)可以表示为:
H(p,q)=−∑k=1Kp(k)logq(k)
在这里我们设正确值y^的分布为p,而计算值y=a2的分布为q,假设共有K=10个类别,并且假设第r维为正确数字,则代价函数的值为:
C=H(p,q)=−∑k=1Kp(k)logq(k)=−(0∗logy1+0∗logy2+...+1∗logyr+...+0∗logy10)=−logyr
我们可以将代价函数值视为R1的向量,我们对y求偏导,根据Jacobian矩阵定义,结果为R1×N2=R1×10的1行10列的矩阵。结果如下所示:
∂C∂y=[00...−1yr...0]
其只有正确数字对应的第r维不为0,其余均为零。
接下来我们来求:∂y∂z2,因为y和a2均为向量,可以直接使用Jacobian矩阵定义得:
∂y∂z2=∂y1∂z21∂y2∂z21...∂yN2∂z21∂y1∂z22∂y2∂z22...∂yN2∂z22............∂y1∂z2N2∂y2∂z2N2...∂yN2∂z2N2
接下来∂z2∂W2、∂z2∂a1、∂z2∂b2就是上一篇博文中讲述的内容。这里我们简单讲解下代价函数和代价函数反向求导的问题。代码如下所示:
@tf.custom_gradientdef cross_entropy(y, y_):
# 找出y_中不等于0的下标值
idx = np.nonzero(y_)[0][0] def grad_fn(dy):
grad_C = np.zeros(y.shape[0])
grad_C[idx] = - 1.0 / y[idx] return tf.constant(grad_C) return -math.log(y[idx]), grad_fndef test003(args={}):
tf.enable_eager_execution()
tfe = tf.contrib.eager
print('代价函数求导...')
y = np.zeros((10)) for idx in range(10):
y[idx] = 0.01
y[2] = 0.31
y[3] = 0.11
y[8] = 0.21
y[1] = 0.11
y[4] = 0.21
y_ = np.array([0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
print('y:{0}'.format(y))
print('y_:{0}'.format(y_))
C = cross_entropy(y, y_)
print('代价函数值:{0}'.format(C.numpy()))
grad_C1 = tfe.gradients_function(cross_entropy)
pC_py = grad_C1(y, y_)
print('pC_py:{0}'.format(pC_py[0].numpy()))运行结果如下所示:

在求∂y2∂z2时,根据我们的定义,输出层采用的是交叉熵(Cross Entropy)函数,形式为:
yi=ez2i∑N2k=1ez2k(3.3.001)
下面我们来求∂yi∂z2j,我们分为i≠j和i=j两种情况来讨论。
当i=j时:
∂yi∂z2i=∂∂z2i(ez2i∑N2k=1ez2k)=ez2i∑N2k=1ez2k−(ez2i∑N2k=1ez2k)2(3.3.002)
当i≠j时:
∂yi∂z2j=∂∂z2j(ez2i∑N2k=1ez2k)=−ez2iez2j(∑N2k=1ez2k)2(3.3.002)
按照上面的公式,我们可以求出∂y∂z2∈R10×10的方阵。
根据定义有:
∂C∂W2=∂C∂y⋅∂y∂z2⋅∂z2∂W2(3.3.003)
其维数为R1×10×R10×10×R10×10×512=R1×10×512,即可得到每个第1层到第2层连接权值的导数,根据梯度下降算法,就可以求出新的连接权值了。
到目前为止,我们已经将所有多层感知器(MLP)模式中用到的技术,全部讲述完成了,有了这些基本知识之后,我们就可以搭建一个完整的多层感知器(MLP)模型了,在下一节中我们将搭建一个最基本的多层感知器模型用于MNIST手写数字识别。
在上篇博文中,我们讲述怎样处理第l−1层到第l层的前向传输和反向求导,我们还没有讲述关于输出层的处理技术。在这里,我们还以MNIST手写数字识别为例,网络计算图如下所示:
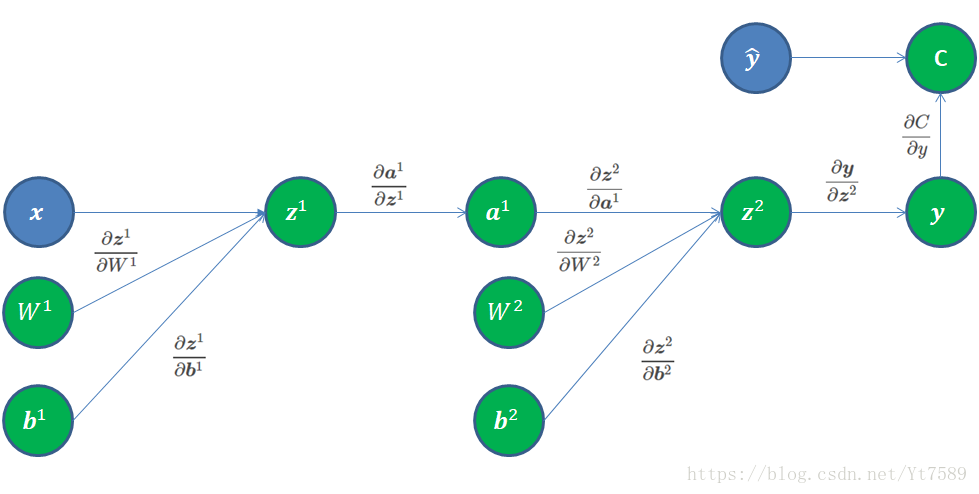
当我们计算出输出层的输出y∈R10时,表示输入图像x是0~9这10个数字的概率。此时输入图像x对应的正确结果y^∈R10,假设该数为r,则y^r=1,其余维0,即y^={0,0,...,1,...,0},其中主1的是第r维。
我们首先处理损失函数,这里我们假设不考虑添加调整项的情况,我们的代价函数取交叉熵(cross entropy)函数,根据交叉熵定义:
H(p,q)=Ep(−logq)=H(p)+KL(p∥q)
对离散值情况,交叉熵(cross entropy)可以表示为:
H(p,q)=−∑k=1Kp(k)logq(k)
在这里我们设正确值y^的分布为p,而计算值y=a2的分布为q,假设共有K=10个类别,并且假设第r维为正确数字,则代价函数的值为:
C=H(p,q)=−∑k=1Kp(k)logq(k)=−(0∗logy1+0∗logy2+...+1∗logyr+...+0∗logy10)=−logyr
我们可以将代价函数值视为R1的向量,我们对y求偏导,根据Jacobian矩阵定义,结果为R1×N2=R1×10的1行10列的矩阵。结果如下所示:
∂C∂y=[00...−1yr...0]
其只有正确数字对应的第r维不为0,其余均为零。
接下来我们来求:∂y∂z2,因为y和a2均为向量,可以直接使用Jacobian矩阵定义得:
∂y∂z2=∂y1∂z21∂y2∂z21...∂yN2∂z21∂y1∂z22∂y2∂z22...∂yN2∂z22............∂y1∂z2N2∂y2∂z2N2...∂yN2∂z2N2
接下来∂z2∂W2、∂z2∂a1、∂z2∂b2就是上一篇博文中讲述的内容。这里我们简单讲解下代价函数和代价函数反向求导的问题。代码如下所示:
@tf.custom_gradientdef cross_entropy(y, y_):
# 找出y_中不等于0的下标值
idx = np.nonzero(y_)[0][0] def grad_fn(dy):
grad_C = np.zeros(y.shape[0])
grad_C[idx] = - 1.0 / y[idx] return tf.constant(grad_C) return -math.log(y[idx]), grad_fndef test003(args={}):
tf.enable_eager_execution()
tfe = tf.contrib.eager
print('代价函数求导...')
y = np.zeros((10)) for idx in range(10):
y[idx] = 0.01
y[2] = 0.31
y[3] = 0.11
y[8] = 0.21
y[1] = 0.11
y[4] = 0.21
y_ = np.array([0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
print('y:{0}'.format(y))
print('y_:{0}'.format(y_))
C = cross_entropy(y, y_)
print('代价函数值:{0}'.format(C.numpy()))
grad_C1 = tfe.gradients_function(cross_entropy)
pC_py = grad_C1(y, y_)
print('pC_py:{0}'.format(pC_py[0].numpy()))运行结果如下所示:

在求∂y2∂z2时,根据我们的定义,输出层采用的是交叉熵(Cross Entropy)函数,形式为:
yi=ez2i∑N2k=1ez2k(3.3.001)
下面我们来求∂yi∂z2j,我们分为i≠j和i=j两种情况来讨论。
当i=j时:
∂yi∂z2i=∂∂z2i(ez2i∑N2k=1ez2k)=ez2i∑N2k=1ez2k−(ez2i∑N2k=1ez2k)2(3.3.002)
当i≠j时:
∂yi∂z2j=∂∂z2j(ez2i∑N2k=1ez2k)=−ez2iez2j(∑N2k=1ez2k)2(3.3.002)
按照上面的公式,我们可以求出∂y∂z2∈R10×10的方阵。
根据定义有:
∂C∂W2=∂C∂y⋅∂y∂z2⋅∂z2∂W2(3.3.003)
其维数为R1×10×R10×10×R10×10×512=R1×10×512,即可得到每个第1层到第2层连接权值的导数,根据梯度下降算法,就可以求出新的连接权值了。
到目前为止,我们已经将所有多层感知器(MLP)模式中用到的技术,全部讲述完成了,有了这些基本知识之后,我们就可以搭建一个完整的多层感知器(MLP)模型了,在下一节中我们将搭建一个最基本的多层感知器模型用于MNIST手写数字识别。
原文出处
打开App,阅读手记






