
一、场景
下班的路上,一直在考虑如何处理大批量的文件解析。场景如下:
系统A中记录了客户的账户余额,系统B每天会定时将客户的交易流水放入文件服务器。然后系统A通过Job解析交易文件,更新账户余额。
场景很简单,但当数据量比较大的时候,比如客户数量达到5000万至1亿左右,如何优化业务逻辑,保证数据的正确性?
二、问题与解决方案
对于上述场景,我的第一个想法就是采取“生产者-消费者”的模式,保证程序能够横向扩展。最常用的就是采用MQ。
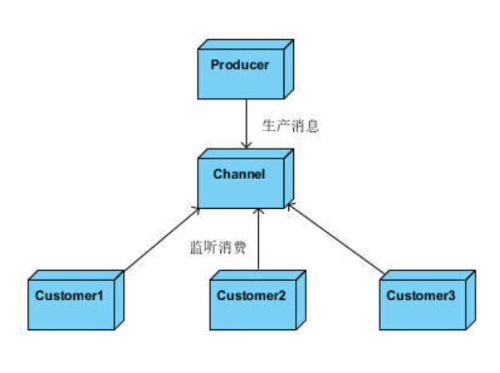
图1.单一通道的生产消费关系
当业务复杂的时候,可以建立多个通道,不同的业务用不同的通道来负责。
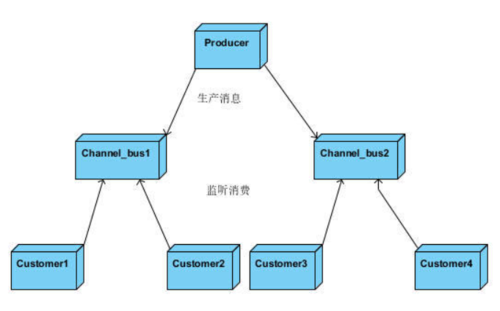
图2.多个通道的生产消费关系
接下来,就是具体业务逻辑中需要考虑到的一些问题。
1.要不要采用线程池?
采用多线程是一定的,但为什么还会有这样的问题呢?因为我还有另外一个比较好的想法,可以采用直接初始化几(30)个线程待命的方式来取代线程池,个人觉得这样会比传统的线程池效率高一点。如果有人觉得这样的想法不是很好,可以忽略这一点,直接用线程池。
2.如何保证数据的一致性?
从任务表中捞出需要解析的文件,需要考虑多任务并发的情形。这时,需要对每一个正在处理的文件加分布式锁,保证当前文件只有一个线程在处理。
3.当一个文件处理中遇到了错误,应该采用什么机制进行容错?
如果是整个文件都无法解析,那么直接反馈到任务执行报告中去。同时生成一个新的调度,等下一个日切时间。
如果是文件中某一条记录无法解析,那么需要对该行记录标记一下,反馈到任务执行报告。同时继续执行下一条。
4.文件解析的效率问题
同一个账户的流水,可能分散于多个不同的文件中,为了提高效率,我们考虑需要建立一张临时表,对账户流水记录进行轧差,最后再更新账户余额。
初步想法是,将解析记录都插入临时表中,当解析任务全部完成后,统一触发轧差更新的调度(按照账户进行轧差)。
所以这里需要2个子调度 :
a.解析文件,批量入库
b.轧差计算,更新账户余额
关于轧差计算,由于记录比较多(2千万用户,每人5条流水,就有1亿条记录了),这样查询效率会比较低,如果有必要,可以考虑分表。
5.如果说文件中并不是交易流水,而是账户余额,这时改如何处理?
同一个账户的余额可能存在于多个文件,如果没有按照时间排序,会导致更新余额时的数据错误。这样的处理不需要考虑轧差的问题,只需要将所有的记录进行排序,更新最后一个余额就可以了。
三、结论
最终的流程图如下:
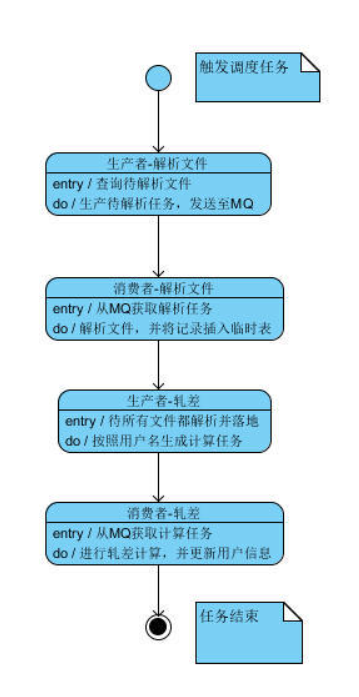
图三.结论
作者:Tide_w
链接:https://www.jianshu.com/p/6b045841e7a9





