
使用Docker和LangChain,无需使用GPU,构建你自己的本地优先型的生成式AI栈。
为什么 本地 LLM 很重要?
大型语言模型(LLM)的崛起已经彻底改变了我们构建应用程序的方法。但要在本地部署它们呢?这对大多数开发者来说仍然是一件棘手的事。从模型格式到依赖地狱,再到硬件限制,甚至奇怪的命令行工具,即使是在笔记本上运行一个小LLM也仿佛在雷区中穿行。
Docker Model Runner改变了这一切——它将容器原生开发的强大能力带入本地AI流程,让你可以专注于开发,而不是与工具链搏斗。
开发者遇到的问题:
- 格式太多:GGUF、PyTorch、ONNX、TF 等等
- 依赖问题和混乱的构建脚本
- 需要 GPU 或配置复杂的 CUDA
- 实验时缺乏一致的本地 API
Docker Model Runner 如下解决这些问题:
- 通过Docker镜像来标准化模型访问
- 使用llama.cpp在后台运行以实现快速处理
- 开箱即用地提供与OpenAI兼容的APIs
- 直接与Docker Desktop无缝集成
🐳 Docker模型运行程序是什么?
它是一个轻量级的本地模型运行时环境,与Docker Desktop集成在一起。它允许你本地运行量化模型(GGUF格式),并通过熟悉的命令行界面(CLI)和OpenAI兼容的API来操作。它基于llama.cpp,设计为:
- 开发者友好: 几秒钟内就能拉取并运行模型
- 离线优先: 适合隐私和边缘设备场景
- 可组合: 可与LangChain、LlamaIndex等配合使用
主要特点:
- 在
localhost:11434运行的 OpenAI 风格的 API - 无需 GPU,可以在配备 Apple Silicon 的 MacBook 上运行
- 可通过命令行轻松切换模型
- 与 Docker Desktop 集成
五分钟:上手
1. 开启模型运行器(Docker桌面)
在 Docker Desktop 中运行 model-runner
2. 创建你的第一个模型
docker model pull ai/smollm2:360M-Q4_K_M
3. 运行带提示词的模型
docker model run ai/smollm2:360M-Q4_K_M "解释多普勒效应,就像我在跟五岁的小朋友说话。"
4. 使用(开放的)API
curl http://localhost:11434/v1/completions \ -H "Content-Type: application/json" \ -d '{"model": "smollm2", "prompt": "你好,你是谁呀?", "max_tokens": 100}'
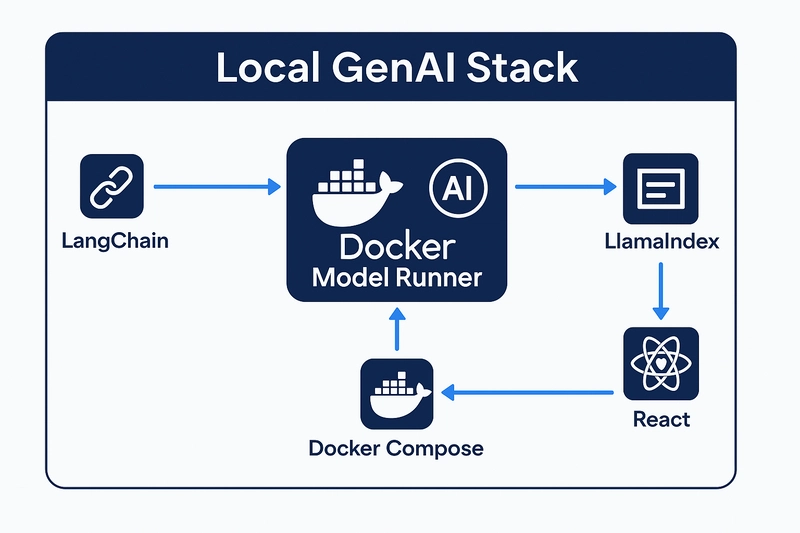
⚙️搭建您的本地生成式AI系统
这里有一个使用 Docker Model Runner 作为推理后端的简单架构。
- LangChain: 用于提示模板和链式操作
- Docker 模型运行:本地运行大型语言模型
- LlamaIndex: 用于文档索引和检索(RAG)
- React 前端: 清晰的聊天界面,便于与模型交互
- Docker Compose: 一键运行所有组件
docker-compose.yml 示例(请参见 GitHub 仓库中的示例):
services:
model-runner:
image: ai/smollm2:360M-Q4_K_M
ports:
- "11434:11434"
frontend:
build: ./frontend
ports:
- "3000:3000"
environment:
- API_URL=http://localhost:11434进入全屏 退出全屏
特色功能:
- 离线运行
- 模型热交换通过环境变量
- 完全支持容器化
💡 小提示:添加一个前端聊天窗口
使用任何前端框架如React、Next.js或Vue来构建一个聊天界面,并通过REST API与本地模型通信。
一个简单的示例检索:
fetch("http://localhost:11434/v1/completions", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ prompt: "Docker是什么?", model: "smollm2" })
});
点击进入全屏 点击退出全屏
这为你提供了一个完全本地化的大型语言模型(LLM)体验,无需使用GPU或云API。
超酷的 高级用法
- RAG 管道: 结合 PDF 和本地向量搜索,同时运行模型运行器
- 多个模型: 运行 phi2、mistral 等独立的服务
- 模型比较: 使用 Compose 构建 A/B 测试界面工具
- Whisper.cpp 集成: 语音转文字容器插件功能(即将推出)
- 边缘 AI 部署: 在隔离系统或开发板上部署
愿景:目标所在
Docker Model Runner 可以成长为一个完整的生态系统。
- ModelHub:可搜索和标记的模型库
- 原生GenAI的Compose模板
- Whisper + LLM混合运行器
- 监控模型性能的仪表盘
- 用于提示工程和测试的VSCode插件
作为开发者,我将这视为一个巨大的机会,可以降低进行AI实验的门槛,并帮助让容器原生AI让每个人都能接触。






热门评论
-

llmzd2025-05-15 0
查看全部评论请问老师,这个和 ollama 相比,有啥优点?